Probability density function
Description
Examples
Compute Normal Distribution pdf by Specifying Distribution Name and Parameters
Compute the pdf values for a normal distribution by specifying the distribution name 'Normal' and the distribution parameters.
Define the input vector x to contain the values at which to calculate the pdf.
x = [-2 -1 0 1 2];
Compute the pdf values for the normal distribution with the mean equal to 1 and the standard deviation equal to 5.
mu = 1;
sigma = 5;
y = pdf('Normal',x,mu,sigma)y = 1×5
0.0666 0.0737 0.0782 0.0798 0.0782
Each value in y corresponds to a value in the input vector x. For example, at the value x equal to 1, the corresponding pdf value y is equal to 0.0798.
Compute Normal Distribution pdf Using Distribution Object
Create a normal distribution object and compute the pdf values of the normal distribution using the object.
Create a normal distribution object with the mean equal to 1 and the standard deviation equal to 5.
mu = 1; sigma = 5; pd = makedist('Normal','mu',mu,'sigma',sigma);
Define the input vector x to contain the values at which to calculate the pdf.
x = [-2 -1 0 1 2];
Compute the pdf values for the normal distribution at the values in x.
y = pdf(pd,x)
y = 1×5
0.0666 0.0737 0.0782 0.0798 0.0782
Each value in y corresponds to a value in the input vector x. For example, at the value x equal to 1, the corresponding pdf value y is equal to 0.0798.
Compute the Poisson Distribution pdf
Create a Poisson distribution object with the rate parameter, , equal to 2.
lambda = 2; pd = makedist('Poisson','lambda',lambda);
Define the input vector x to contain the values at which to calculate the pdf.
x = [0 1 2 3 4];
Compute the pdf values for the Poisson distribution at the values in x.
y = pdf(pd,x)
y = 1×5
0.1353 0.2707 0.2707 0.1804 0.0902
Each value in y corresponds to a value in the input vector x. For example, at the value x equal to 3, the corresponding pdf value in y is equal to 0.1804.
Alternatively, you can compute the same pdf values without creating a probability distribution object. Use the pdf function, and specify a Poisson distribution using the same value for the rate parameter, .
y2 = pdf('Poisson',x,lambda)y2 = 1×5
0.1353 0.2707 0.2707 0.1804 0.0902
The pdf values are the same as those computed using the probability distribution object.
Plot the pdf of a Standard Normal Distribution
Create a standard normal distribution object.
pd = makedist('Normal')pd =
NormalDistribution
Normal distribution
mu = 0
sigma = 1
Specify the x values and compute the pdf.
x = -3:.1:3; pdf_normal = pdf(pd,x);
Plot the pdf.
plot(x,pdf_normal,'LineWidth',2)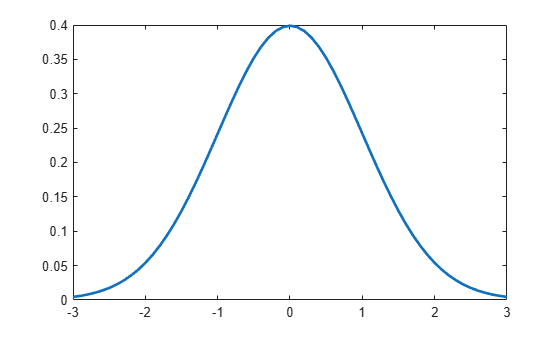
Plot pdf of Weibull Distribution
Create a Weibull probability distribution object.
pd = makedist('Weibull','A',5,'B',2)
pd =
WeibullDistribution
Weibull distribution
A = 5
B = 2
Specify the x values and compute the pdf.
x = 0:.1:15; y = pdf(pd,x);
Plot the pdf.
plot(x,y,'LineWidth',2)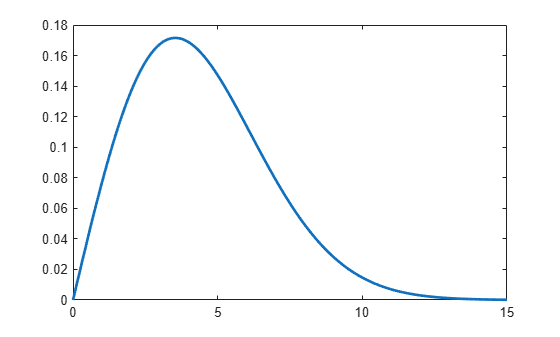
Input Arguments
Output Arguments
Alternative Functionality
pdfis a generic function that accepts either a distribution by its namenameor a probability distribution objectpd. It is faster to use a distribution-specific function, such asnormpdffor the normal distribution andbinopdffor the binomial distribution. For a list of distribution-specific functions, see Supported Distributions.Use the Probability Distribution Function app to create an interactive plot of the cumulative distribution function (cdf) or probability density function (pdf) for a probability distribution.
Extended Capabilities
Version History
Introduced before R2006aSee Also
cdf | icdf | mle | random | makedist | fitdist | Distribution Fitter | paretotails | ksdensity | kde
Select a Web Site
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select: United States.
You can also select a web site from the following list
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)
Asia Pacific
- Australia (English)
- India (English)
- New Zealand (English)
- 中国
- 日本Japanese (日本語)
- 한국Korean (한국어)