fitdist
확률 분포 객체를 데이터에 피팅하기
구문
설명
예제
정규분포를 표본 데이터에 피팅하고 히스토그램 및 q-q(분위수-분위수) 플롯을 사용하여 피팅을 검토합니다.
데이터 파일 patients.mat에서 환자의 체중을 불러옵니다.
load patients
x = Weight;이를 데이터에 피팅하여 정규분포 객체를 생성합니다.
pd = fitdist(x,'Normal')pd =
NormalDistribution
Normal distribution
mu = 154 [148.728, 159.272]
sigma = 26.5714 [23.3299, 30.8674]
분포 객체 표시에는 평균(mu) 및 표준편차(sigma)에 대한 모수 추정값과 모수에 대한 95% 신뢰구간이 포함됩니다.
pd의 객체 함수를 사용하여 분포를 실행하고 난수를 생성할 수 있습니다. 지원되는 객체 함수를 표시합니다.
methods(pd)
Methods for class prob.NormalDistribution: cdf gather icdf iqr mean median negloglik paramci pdf plot proflik random std truncate var
예를 들어, paramci 함수를 사용하여 95% 신뢰구간을 구합니다.
ci95 = paramci(pd)
ci95 = 2×2
148.7277 23.3299
159.2723 30.8674
유의수준(Alpha)을 지정하여 다른 신뢰수준을 갖는 신뢰구간을 구합니다. 99% 신뢰구간을 계산합니다.
ci99 = paramci(pd,'Alpha',.01)ci99 = 2×2
147.0213 22.4257
160.9787 32.4182
분포의 pdf 값을 계산하고 플로팅합니다.
x_values = 50:1:250; y = pdf(pd,x_values); plot(x_values,y)
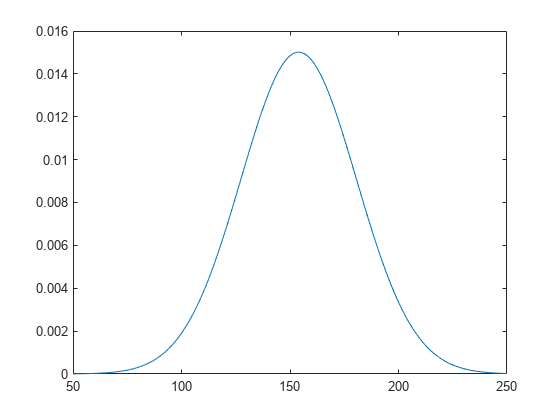
histfit 함수를 사용하여 정규분포가 피팅된 히스토그램을 만듭니다. histfit은 fitdist를 사용하여 분포를 데이터에 피팅합니다.
histfit(x)
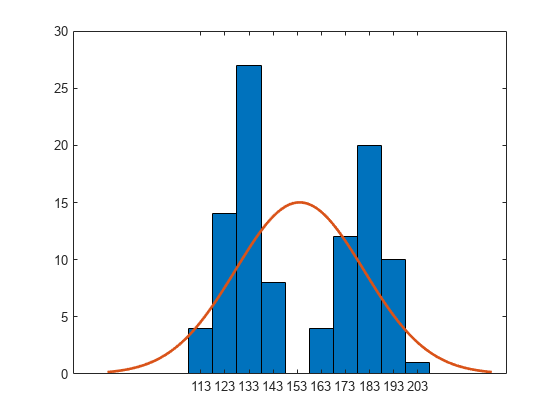
히스토그램에서 데이터가 두 개의 최빈값을 가지며 정규분포 피팅의 최빈값이 이 두 최빈값 사이에 있는 것을 볼 수 있습니다.
qqplot을 사용하여 표본 데이터 x의 분위수와 피팅된 분포의 이론적 분위수 값에 대한 q-q(분위수-분위수) 플롯을 생성합니다.
qqplot(x,pd)
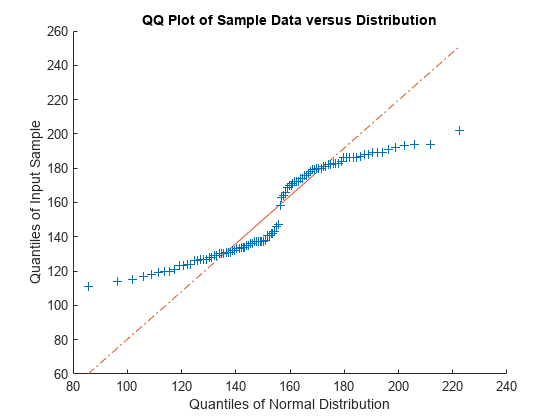
이 플롯은 직선이 아닙니다. 이는 데이터가 정규분포를 따르지 않음을 나타냅니다.
데이터 파일 patients.mat에서 환자의 체중을 불러옵니다.
load patients
x = Weight;이를 데이터에 피팅하여 커널 분포 객체를 생성합니다. Epanechnikov 커널 함수를 사용합니다.
pd = fitdist(x,'Kernel','Kernel','epanechnikov')
pd =
KernelDistribution
Kernel = epanechnikov
Bandwidth = 14.3792
Support = unbounded
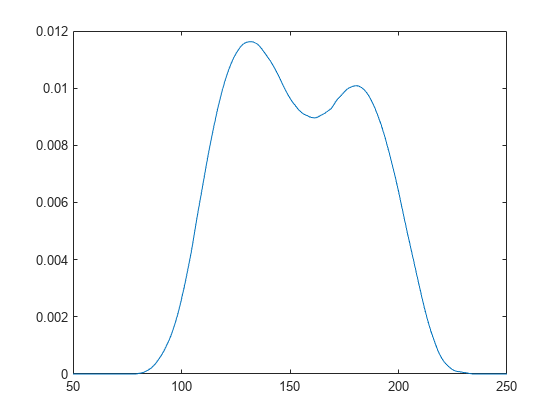
분포의 pdf를 플로팅합니다.
x_values = 50:1:250; y = pdf(pd,x_values); plot(x_values,y)
데이터 파일 patients.mat에서 환자의 체중과 성별을 불러옵니다.
load patients
x = Weight;환자 성별로 그룹화된 데이터에 피팅하여 정규분포 객체를 생성합니다.
[pdca,gn,gl] = fitdist(x,'Normal','By',Gender)
pdca=1×2 cell array
{1×1 prob.NormalDistribution} {1×1 prob.NormalDistribution}
gn = 2×1 cell
{'Male' }
{'Female'}
gl = 2×1 cell
{'Male' }
{'Female'}
셀형 배열 pdca는 각 성별 그룹에 대해 하나씩, 총 두 개의 확률 분포 객체를 포함합니다. 셀형 배열 gn은 두 개의 그룹 레이블을 포함합니다. 셀형 배열 gl은 두 개의 그룹 수준을 포함합니다.
셀형 배열 pdca에 포함된 각 분포를 확인하여 환자 성별로 그룹화된 평균 mu와 표준편차 sigma를 비교합니다.
female = pdca{1} % Distribution for femalesfemale =
NormalDistribution
Normal distribution
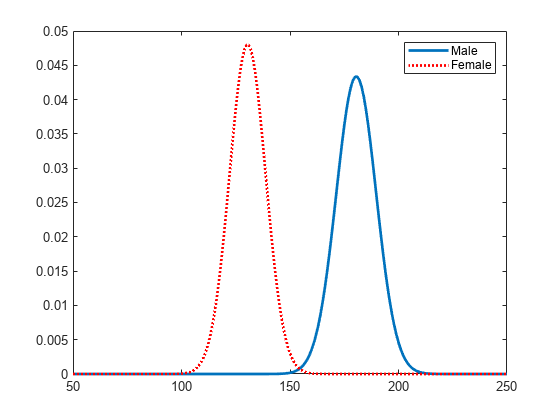
mu = 180.532 [177.833, 183.231]
sigma = 9.19322 [7.63933, 11.5466]
male = pdca{2} % Distribution for malesmale =
NormalDistribution
Normal distribution
mu = 130.472 [128.183, 132.76]
sigma = 8.30339 [6.96947, 10.2736]
각 분포의 pdf를 계산합니다.
x_values = 50:1:250; femalepdf = pdf(female,x_values); malepdf = pdf(male,x_values);
성별을 기준으로 체중 분포를 시각적으로 비교할 수 있도록 pdf를 플로팅합니다.
figure plot(x_values,femalepdf,'LineWidth',2) hold on plot(x_values,malepdf,'Color','r','LineStyle',':','LineWidth',2) legend(gn,'Location','NorthEast') hold off
데이터 파일 patients.mat에서 환자의 체중과 성별을 불러옵니다.
load patients
x = Weight;환자 성별로 그룹화된 데이터에 피팅하여 커널 분포 객체를 생성합니다. 삼각 커널 함수를 사용합니다.
[pdca,gn,gl] = fitdist(x,'Kernel','By',Gender,'Kernel','triangle');
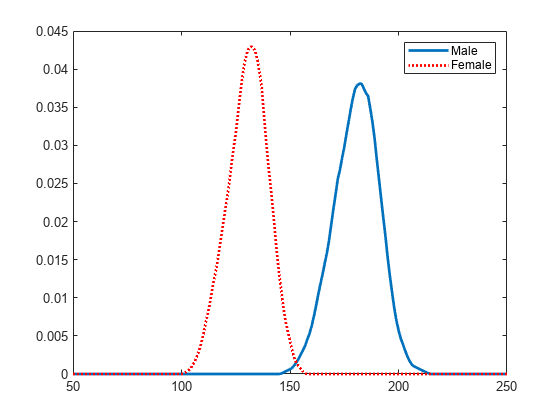
셀형 배열 pdca에 포함된 각 분포를 검토하여 각 성별에 대한 커널 분포를 확인합니다.
female = pdca{1} % Distribution for femalesfemale =
KernelDistribution
Kernel = triangle
Bandwidth = 5.08961
Support = unbounded
male = pdca{2} % Distribution for malesmale =
KernelDistribution
Kernel = triangle
Bandwidth = 4.25894
Support = unbounded
각 분포의 pdf를 계산합니다.
x_values = 50:1:250; femalepdf = pdf(female,x_values); malepdf = pdf(male,x_values);
성별을 기준으로 체중 분포를 시각적으로 비교할 수 있도록 pdf를 플로팅합니다.
figure plot(x_values,femalepdf,'LineWidth',2) hold on plot(x_values,malepdf,'Color','r','LineStyle',':','LineWidth',2) legend(gn,'Location','NorthEast') hold off
입력 인수
이름-값 인수
출력 인수
알고리즘
fitdist 함수는 최대가능도 추정값을 사용하여 대부분의 분포를 피팅합니다. 이에 두 가지 예외가 있는데 중도절단되지 않은 데이터를 포함하는 정규분포 및 로그정규분포에 대한 경우입니다.
중도절단되지 않은 정규분포의 경우, 시그마 모수에 대해 추정된 값은 분산의 무편향 추정값에 대한 제곱근입니다.
중도절단되지 않은 로그정규분포의 경우, 시그마 모수에 대해 추정된 값은 데이터의 로그 분산의 무편향 추정값에 대한 제곱근입니다.
대체 기능
분포 피팅기 앱은 작업 공간에서 데이터를 가져오고 확률 분포를 이 데이터에 대화형 방식으로 피팅할 수 있는 그래픽 사용자 인터페이스(GUI)를 제공합니다. 그러면 분포를 확률 분포 객체로 작업 공간에 저장할 수 있습니다. 명령줄에서
distributionFitter를 사용하여 분포 피팅기 앱을 열거나 앱 탭에서 분포 피팅기를 클릭하십시오.분포를 좌측 중도절단된 데이터, 양측 중도절단된 데이터 또는 구간 중도절단된 데이터에 피팅하려면
mle를 사용하십시오.mle함수를 사용하여 최대가능도 추정값을 구하거나makedist함수를 사용하여 확률 분포 객체를 생성할 수 있습니다. 예제는 양측 중도절단된 데이터에 대한 MLE 구하기 항목을 참조하십시오.
참고 문헌
[1] Johnson, N. L., S. Kotz, and N. Balakrishnan. Continuous Univariate Distributions. Vol. 1, Hoboken, NJ: Wiley-Interscience, 1993.
[2] Johnson, N. L., S. Kotz, and N. Balakrishnan. Continuous Univariate Distributions. Vol. 2, Hoboken, NJ: Wiley-Interscience, 1994.
[3] Bowman, A. W., and A. Azzalini. Applied Smoothing Techniques for Data Analysis. New York: Oxford University Press, 1997.