random
구문
설명
예제
평균 가 1이고 표준편차 가 5인 정규분포에서 하나의 난수를 생성합니다. 분포 이름 'Normal' 및 분포 모수를 지정합니다.
rng('default') % For reproducibility mu = 1; sigma = 5; r = random('Normal',mu,sigma)
r = 3.6883
정규분포 객체를 만들고 이 객체를 사용하여 하나의 난수를 생성합니다.
평균 가 1이고 표준편차 가 5인 정규분포 객체를 생성합니다.
mu = 1; sigma = 5; pd = makedist('Normal','mu',mu,'sigma',sigma);
분포에서 하나의 난수를 생성합니다.
rng('default') % For reproducibility r = random(pd)
r = 3.6883
난수 생성기의 현재 상태를 저장합니다. 그런 다음 사건 발생률 모수가 5인 푸아송 분포에서 난수를 생성합니다.
s = rng;
r = random('Poisson',5)r = 5
난수 생성기의 상태를 s로 복원한 후 새 난수를 생성합니다. 값은 이전과 같습니다.
rng(s);
r1 = random('Poisson',5)r1 = 5
기존 배열과 동일한 크기의, 난수로 구성된 행렬을 만듭니다. 형태 모수가 2와 0이고, 스케일 모수가 1이며, 위치 모수가 0인 안정분포를 사용합니다.
A = [3 2; -2 1];
sz = size(A);
R = random('Stable',2,0,1,0,sz)R = 2×2
0.7604 -3.1945
2.5935 1.2193
위에 나와 있는 두 코드 라인을 하나의 라인으로 결합할 수 있습니다.
R = random('Stable',2,0,1,0,size(A))R = 2×2
0.4508 -0.6132
-1.8494 0.4845
디폴트 모수 값을 사용하여 베이불(Weibull) 확률 분포 객체를 생성합니다.
pd = makedist('Weibull')pd =
WeibullDistribution
Weibull distribution
A = 1
B = 1
분포에서 난수를 생성합니다.
rng('default') % For reproducibility r = random(pd,10000,1);
베이불 분포 피팅과 함께 100개의 Bin을 사용하여 히스토그램을 생성합니다.
histfit(r,100,'weibull')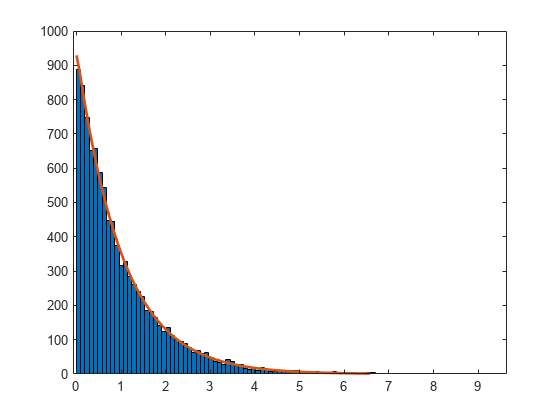
표준 정규 확률 분포 객체를 만듭니다.
pd = makedist('Normal')pd =
NormalDistribution
Normal distribution
mu = 0
sigma = 1
분포에서 난수로 구성된 2×3×2 배열을 생성합니다.
r = random(pd,[2,3,2])
r =
r(:,:,1) =
0.5377 -2.2588 0.3188
1.8339 0.8622 -1.3077
r(:,:,2) =
-0.4336 3.5784 -1.3499
0.3426 2.7694 3.0349