로그정규분포
개요
로그정규분포는 갈톤(Galton) 분포라고도 하며, 확률 분포의 로그가 정규분포를 가질 때의 확률 분포를 말합니다. log(x)는 x가 양수인 경우에만 존재하므로 관심 있는 수량이 양수인 경우에만 로그정규분포를 적용할 수 있습니다.
Statistics and Machine Learning Toolbox™에서는 다음과 같이 로그정규분포를 사용하는 여러 방법을 제공합니다.
확률 분포를 표본 데이터에 피팅하거나(
fitdist) 모수 값을 지정하여(makedist) 확률 분포 객체LognormalDistribution을 생성합니다. 그런 다음 객체 함수를 사용하여 분포를 실행하고, 난수를 생성하는 등의 작업을 수행합니다.분포 피팅기 앱을 사용하여 대화형 방식으로 로그정규분포를 사용합니다. 앱에서 객체를 내보내고 객체 함수를 사용할 수 있습니다.
지정된 분포 모수를 이용해 분포 전용 함수(
logncdf,lognpdf,logninv,lognlike,lognstat,lognfit,lognrnd)를 사용합니다. 분포 전용 함수는 여러 로그정규분포의 모수를 받을 수 있습니다.일반 분포 함수(
cdf,icdf,pdf,random)를 지정된 분포 이름('Lognormal') 및 모수와 함께 사용합니다.
모수
로그정규분포는 다음과 같은 모수를 사용합니다.
| 모수 | 설명 | 지원 |
|---|---|---|
mu (μ) | 로그 값의 평균 | |
sigma (σ) | 로그 값의 표준편차 |
X가 모수 µ 및 σ를 갖는 로그정규분포를 따르면 log(X)는 평균 µ 및 표준편차 σ를 갖는 정규분포를 따릅니다.
모수 추정
로그정규분포를 데이터에 피팅하고 모수 추정값을 구하려면 lognfit, fitdist 또는 mle를 사용하십시오.
중도절단되지 않은 데이터에 대해
lognfit및fitdist는 분포 모수에 대한 무편향 추정값을 구하고,mle는 최대가능도 추정값을 구합니다.중도절단된 데이터에 대해
lognfit,fitdist,mle는 최대가능도 추정값을 구합니다.
모수 추정값을 반환하는 lognfit 및 mle와 달리, fitdist는 피팅된 확률 분포 객체 LognormalDistribution을 반환합니다. 객체 속성 mu와 sigma는 모수 추정값을 저장합니다.
기술 통계량
로그정규 확률 변수의 평균 m과 분산 v는 다음과 같이 로그정규분포 모수 µ 및 σ의 함수입니다.
또한, 다음과 같이 평균 m과 분산 v로부터 로그정규분포 모수 µ와 σ를 계산할 수 있습니다.
확률 밀도 함수
로그정규분포에 대한 확률 밀도 함수(pdf)는 다음과 같습니다.
예제는 로그정규분포 pdf 계산하기 항목을 참조하십시오.
누적 분포 함수
로그정규분포에 대한 누적 분포 함수(cdf)는 다음과 같습니다.
예제는 로그정규분포 cdf 계산하기 항목을 참조하십시오.
예제
로그정규분포 pdf 계산하기
미국의 4인 가족의 수입이 mu = log(20,000)이고 sigma = 1인 로그정규분포를 따른다고 가정해 보겠습니다. 수입 밀도를 계산하고 플로팅합니다.
모수 값을 지정하여 로그정규분포 객체를 만듭니다.
pd = makedist('Lognormal','mu',log(20000),'sigma',1)
pd =
LognormalDistribution
Lognormal distribution
mu = 9.90349
sigma = 1
pdf 값을 계산합니다.
x = (10:1000:125010)'; y = pdf(pd,x);
pdf를 플로팅합니다.
plot(x,y)
h = gca;
h.XTick = [0 30000 60000 90000 120000];
h.XTickLabel = {'0','$30,000','$60,000',...
'$90,000','$120,000'};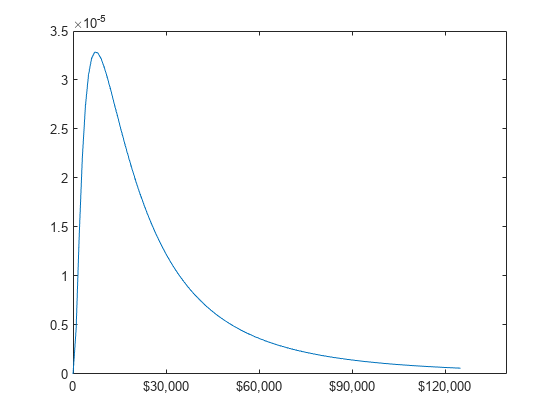
로그정규분포 cdf 계산하기
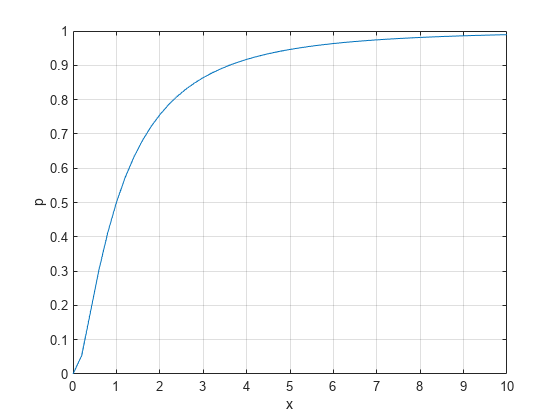
평균 mu 및 표준편차 sigma를 갖는 로그정규분포에 대해 x의 값에서 cdf 값을 계산합니다.
x = 0:0.2:10; mu = 0; sigma = 1; p = logncdf(x,mu,sigma);
cdf를 플로팅합니다.
plot(x,p) grid on xlabel('x') ylabel('p')
정규분포와 로그정규분포 사이의 관계
X가 모수 µ 및 σ를 갖는 로그정규분포를 따르면 log(X)는 평균 µ 및 표준편차 σ를 갖는 정규분포를 따릅니다. 분포 객체를 사용하여 정규분포와 로그정규분포 사이의 관계를 조사합니다.
모수 값을 지정하여 로그정규분포 객체를 만듭니다.
pd = makedist('Lognormal','mu',5,'sigma',2)
pd =
LognormalDistribution
Lognormal distribution
mu = 5
sigma = 2
로그정규분포의 평균을 계산합니다.
mean(pd)
ans = 1.0966e+03
로그정규분포의 평균은 mu 모수와 동일하지 않습니다. 로그 값의 평균은 mu와 동일합니다. 난수를 생성하여 이 관계를 확인합니다.
로그정규분포에서 난수를 생성하고 그 로그 값을 계산합니다.
rng('default'); % For reproducibility x = random(pd,10000,1); logx = log(x);
로그 값의 평균을 계산합니다.
m = mean(logx)
m = 5.0033
x가 로그정규분포를 갖기 때문에 x의 로그의 평균은 x의 mu 모수에 가깝습니다.
정규분포가 피팅된 logx의 히스토그램을 생성합니다.
histfit(logx)
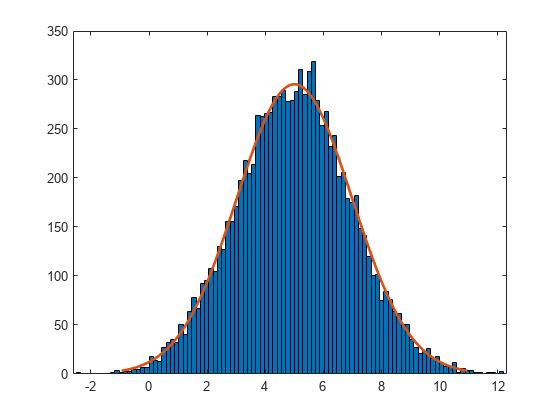
이 플롯을 통해 x의 로그 값이 정규분포된 것을 알 수 있습니다.
histfit은 fitdist를 사용하여 분포를 데이터에 피팅합니다. 피팅에 사용되는 모수를 가져오려면 fitdist를 사용하십시오.
pd_normal = fitdist(logx,'Normal')pd_normal =
NormalDistribution
Normal distribution
mu = 5.00332 [4.96445, 5.04219]
sigma = 1.98296 [1.95585, 2.01083]
추정된 정규분포 모수는 로그정규분포 모수 5와 2에 가깝습니다.
로그정규분포 pdf와 버(Burr) 분포 pdf 비교하기
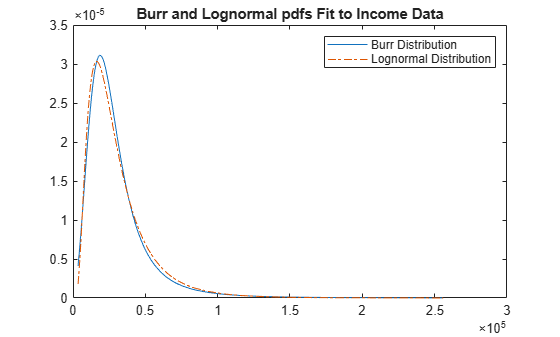
로그정규분포에서 생성된 수입 데이터를 사용하여 로그정규분포 pdf와 버(Burr) 분포 pdf를 비교합니다.
수입 데이터를 생성합니다.
rng('default') % For reproducibility y = random('Lognormal',log(25000),0.65,[500,1]);
버(Burr) 분포를 피팅합니다.
pd = fitdist(y,'burr')pd =
BurrDistribution
Burr distribution
alpha = 26007.2 [21165.5, 31956.4]
c = 2.63743 [2.3053, 3.0174]
k = 1.09658 [0.775479, 1.55064]
수입 데이터의 버(Burr) 분포 pdf와 로그정규분포 pdf를 동일한 Figure에 플로팅합니다.
p_burr = pdf(pd,sortrows(y)); p_lognormal = pdf('Lognormal',sortrows(y),log(25000),0.65); plot(sortrows(y),p_burr,'-',sortrows(y),p_lognormal,'-.') title('Burr and Lognormal pdfs Fit to Income Data') legend('Burr Distribution','Lognormal Distribution')
관련 분포
정규분포 — 로그정규분포는 정규분포와 밀접한 관련이 있습니다. X가 모수 μ 및 σ를 갖는 로그정규분포를 따르면 log(x)는 평균 μ 및 표준편차 σ를 갖는 정규분포를 따릅니다. 정규분포와 로그정규분포 사이의 관계 항목을 참조하십시오.
Burr Type XII Distribution — 버(Burr) 분포는 다양한 분포 형태를 표현할 수 있는 유연한 분포군입니다. 버 분포는 감마 분포, 로그정규분포, 로그-로지스틱 분포, 종 모양 분포, J 모양 베타 분포(U 모양 제외)와 같이 널리 사용되는 다양한 분포를 극한 분포로 갖습니다. 로그정규분포 pdf와 버(Burr) 분포 pdf 비교하기 항목을 참조하십시오.
참고 문헌
[1] Abramowitz, Milton, and Irene A. Stegun, eds. Handbook of Mathematical Functions: With Formulas, Graphs, and Mathematical Tables. 9. Dover print.; [Nachdr. der Ausg. von 1972]. Dover Books on Mathematics. New York, NY: Dover Publ, 2013.
[2] Evans, M., N. Hastings, and B. Peacock. Statistical Distributions. 2nd ed., Hoboken, NJ: John Wiley & Sons, Inc., 1993.
[3] Lawless, J. F. Statistical Models and Methods for Lifetime Data. Hoboken, NJ: Wiley-Interscience, 1982.
[4] Marsaglia, G., and W. W. Tsang. “A Fast, Easily Implemented Method for Sampling from Decreasing or Symmetric Unimodal Density Functions.” SIAM Journal on Scientific and Statistical Computing. Vol. 5, Number 2, 1984, pp. 349–359.
[5] Meeker, W. Q., and L. A. Escobar. Statistical Methods for Reliability Data. Hoboken, NJ: John Wiley & Sons, Inc., 1998.
[6] Mood, A. M., F. A. Graybill, and D. C. Boes. Introduction to the Theory of Statistics. 3rd ed., New York: McGraw-Hill, 1974. pp. 540–541.
참고 항목
LognormalDistribution | logncdf | lognpdf | logninv | lognlike | lognstat | lognfit | lognrnd