이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
ksdensity
일변량 데이터와 이변량 데이터에 대한 커널 평활화 함수 추정값
구문
설명
[는 위에 열거된 구문에 나와 있는 입력 인수와 함께 하나 이상의 이름-값 쌍의 인수로 지정된 추가 옵션을 사용합니다. 예를 들어, 확률 밀도, 누적 확률, 생존 함수 등과 같이 f,xi] = ksdensity(___,Name,Value)ksdensity가 계산하는 함수 유형을 정의할 수 있습니다. 또는, 평활화 윈도우의 대역폭을 지정할 수 있습니다.
예제
두 개의 혼합된 정규분포에서 표본 데이터 세트를 생성합니다.
rng('default') % For reproducibility x = [randn(30,1); 5+randn(30,1)];
추정된 밀도를 플로팅합니다.
[f,xi] = ksdensity(x); figure plot(xi,f);
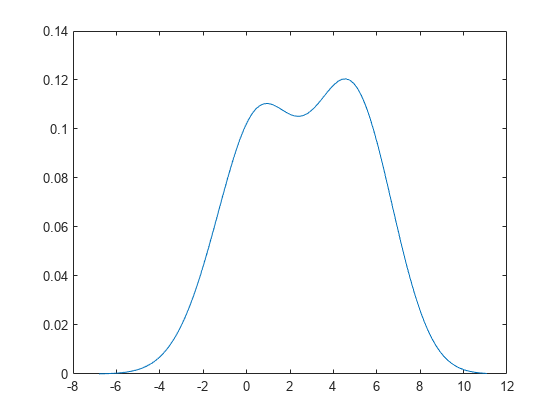
밀도 추정값은 표본의 이봉 분포를 보여줍니다.
절반 정규분포에서 음이 아닌 표본 데이터 세트를 생성합니다.
rng('default') % For reproducibility pd = makedist('HalfNormal','mu',0,'sigma',1); x = random(pd,100,1);
'BoundaryCorrection' 이름-값 쌍의 인수를 사용하여 두 개의 서로 다른 경계 수정 방법인 로그 변환과 반사를 통해 pdf를 추정합니다.
pts = linspace(0,5,1000); % points to evaluate the estimator [f1,xi1] = ksdensity(x,pts,'Support','positive'); [f2,xi2] = ksdensity(x,pts,'Support','positive','BoundaryCorrection','reflection');
추정된 두 pdf를 플로팅합니다.
plot(xi1,f1,xi2,f2) lgd = legend('log','reflection'); title(lgd, 'Boundary Correction Method') xl = xlim; xlim([xl(1)-0.25 xl(2)])
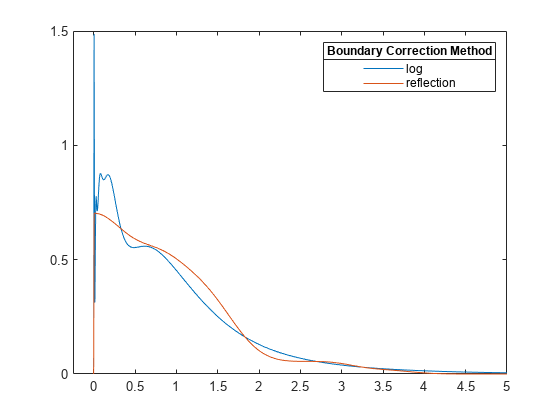
양의 지지 범위 또는 유계 지지 범위를 지정하면 ksdensity는 경계 수정 방법을 사용합니다. 디폴트 경계 수정 방법은 로그 변환입니다. ksdensity가 지지 범위를 다시 변환할 경우 커널 밀도 추정량에 1/x 항이 추가됩니다. 따라서, 추정값은 x = 0 근방에서 피크를 가집니다. 반면, 반사 방법은 경계 근처에서 원치 않는 피크를 발생시키지 않습니다.
표본 데이터를 불러옵니다.
load hospital지정된 값 세트에서 추정된 cdf를 계산하고 플로팅합니다.
pts = (min(hospital.Weight):2:max(hospital.Weight)); figure() ecdf(hospital.Weight) hold on [f,xi,bw] = ksdensity(hospital.Weight,pts,'Support','positive',... 'Function','cdf'); plot(xi,f,'-g','LineWidth',2) legend('empirical cdf','kernel-bw:default','Location','northwest') xlabel('Patient weights') ylabel('Estimated cdf')
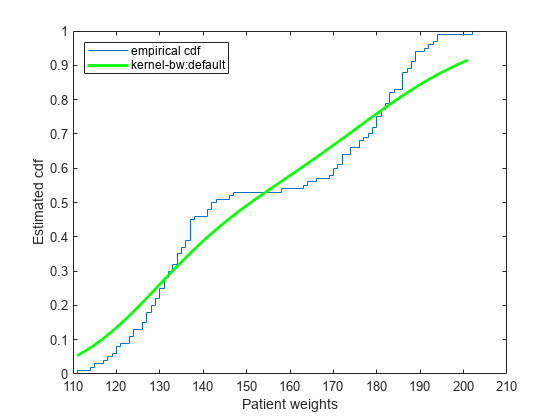
ksdensity가 누적 분포 함수 추정값을 너무 많이 평활화하는 것처럼 보입니다. 더 작은 대역폭을 가지는 추정값이 경험적 누적 분포 함수에 더 가까운 추정값을 생성할 가능성이 있습니다.
평활화 윈도우의 대역폭을 반환합니다.
bw
bw = 0.1070
더 작은 대역폭을 사용하여 누적 분포 함수 추정값을 플로팅합니다.
[f,xi] = ksdensity(hospital.Weight,pts,'Support','positive',... 'Function','cdf','Bandwidth',0.05); plot(xi,f,'--r','LineWidth',2) legend('empirical cdf','kernel-bw:default','kernel-bw:0.05',... 'Location','northwest') hold off
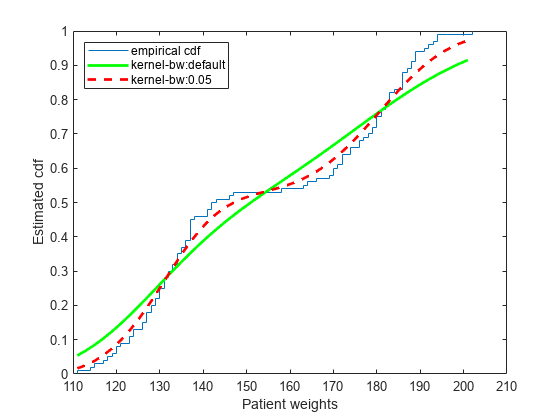
더 작은 대역폭을 사용한 ksdensity 추정값이 경험적 누적 분포 함수와 더 잘 일치합니다.
표본 데이터를 불러옵니다.
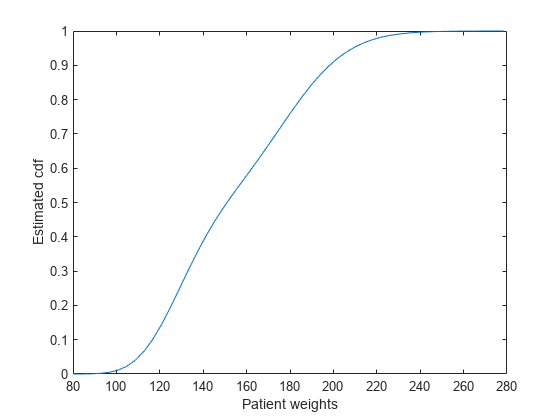
load hospital균일한 간격으로 배치된 50개 점에서 계산된 추정된 cdf를 플로팅합니다.
figure() ksdensity(hospital.Weight,'Support','positive','Function','cdf',... 'NumPoints',50) xlabel('Patient weights') ylabel('Estimated cdf')
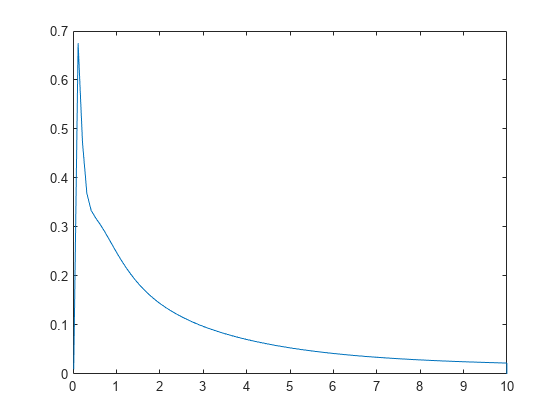
평균이 3인 지수 분포에서 표본 데이터를 생성합니다.
rng('default') % For reproducibility x = random('exp',3,100,1);
중도절단을 나타내는 논리형 벡터를 생성합니다. 여기서, 수명이 10보다 긴 관측값은 중도절단됩니다.
T = 10; cens = (x>T);
추정된 밀도 함수를 계산하고 플로팅합니다.
figure ksdensity(x,'Support','positive','Censoring',cens);
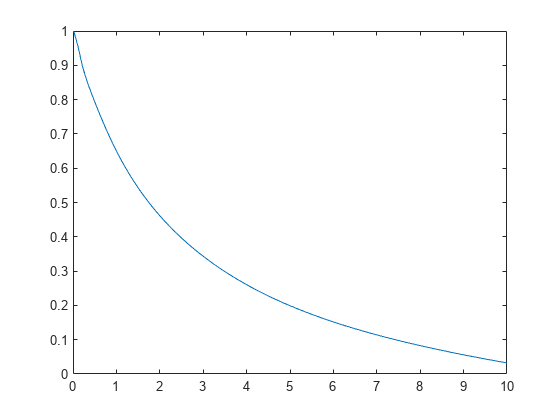
생존 함수를 계산하고 플로팅합니다.
figure ksdensity(x,'Support','positive','Censoring',cens,... 'Function','survivor');
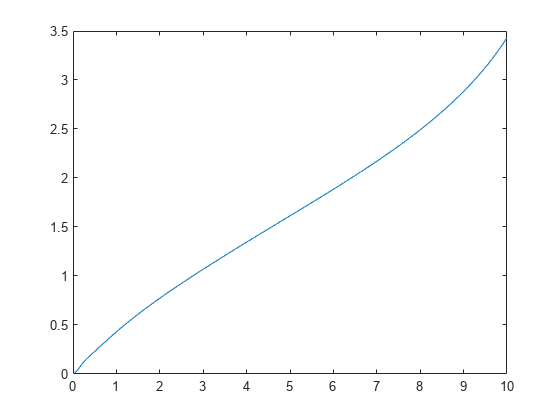
누적 위험 함수를 계산하고 플로팅합니다.
figure ksdensity(x,'Support','positive','Censoring',cens,... 'Function','cumhazard');
두 개의 혼합된 정규분포를 생성하고 지정된 확률 값 세트에서 추정된 역누적 분포 함수를 플로팅합니다.
rng('default') % For reproducibility x = [randn(30,1); 5+randn(30,1)]; pi = linspace(.01,.99,99); figure ksdensity(x,pi,'Function','icdf');
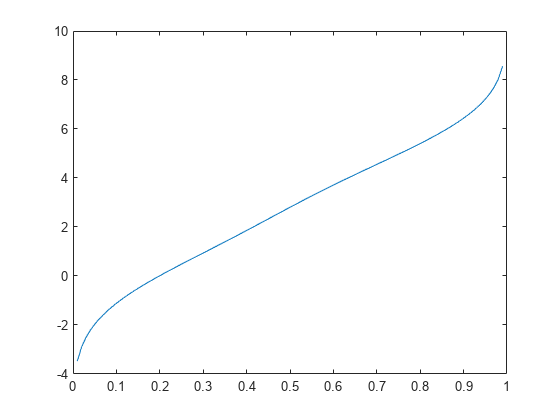
두 개의 혼합된 정규분포를 생성합니다.
rng('default') % For reproducibility x = [randn(30,1); 5+randn(30,1)];
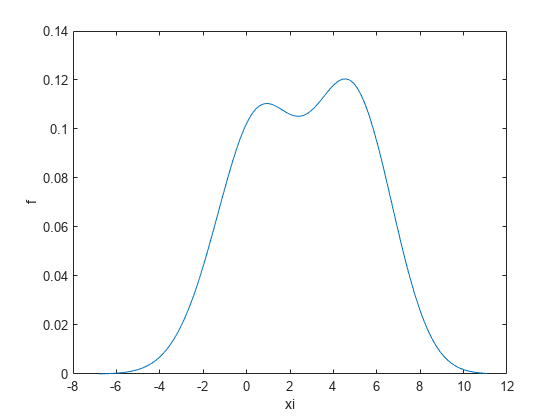
확률 밀도 추정값에 대한 평활화 윈도우의 대역폭을 반환합니다.
[f,xi,bw] = ksdensity(x); bw
bw = 1.5141
디폴트 대역폭은 정규 밀도에 가장 적합합니다.
추정된 밀도를 플로팅합니다.
figure plot(xi,f); xlabel('xi') ylabel('f') hold on
증가된 대역폭 값을 사용하여 밀도를 플로팅합니다.
[f,xi] = ksdensity(x,'Bandwidth',1.8); plot(xi,f,'--r','LineWidth',1.5)
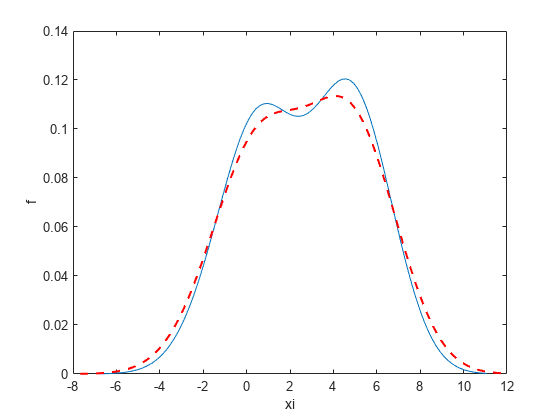
대역폭이 클수록 밀도 추정값이 더 평활화되며, 이 경우 분포의 일부 특징이 가려질 수 있습니다.
이제, 감소된 대역폭 값을 사용하여 밀도를 플로팅합니다.
[f,xi] = ksdensity(x,'Bandwidth',0.8); plot(xi,f,'-.k','LineWidth',1.5) legend('bw = default','bw = 1.8','bw = 0.8') hold off
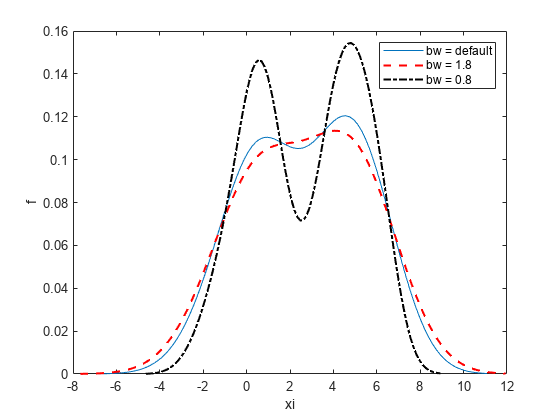
대역폭이 작을수록 밀도 추정값이 덜 평활화되며, 이 경우 표본의 일부 특징이 과장됩니다.
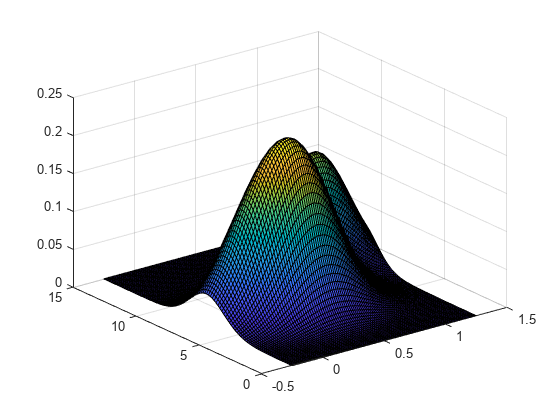
밀도를 계산할 점으로 구성된 2열 벡터를 생성합니다.
gridx1 = -0.25:.05:1.25; gridx2 = 0:.1:15; [x1,x2] = meshgrid(gridx1, gridx2); x1 = x1(:); x2 = x2(:); xi = [x1 x2];
혼합된 이변량 정규분포에서 난수를 포함하는 30×2 행렬을 생성합니다.
rng('default') % For reproducibility x = [0+.5*rand(20,1) 5+2.5*rand(20,1); .75+.25*rand(10,1) 8.75+1.25*rand(10,1)];
표본 데이터에 대한 추정된 밀도를 플로팅합니다.
figure ksdensity(x,xi);
입력 인수
이름-값 인수
출력 인수
세부 정보
대체 기능
MATLAB® kde 함수도 일변량 데이터에 대한 pdf 또는 cdf를 추정하는 데 사용할 수 있습니다. ksdensity 함수와 달리, kde는 경계 수정 방법 또는 데이터 중도절단을 지원하지 않습니다.
참고 문헌
[1] Botev, Z. I., J. F. Grotowski, and D. P. Kroese. "Kernel Density Estimation via Diffusion." The Annals of Statistics, vol. 38, no. 5 (October 1, 2010). https://projecteuclid.org/journals/annals-of-statistics/volume-38/issue-5/Kernel-density-estimation-via-diffusion/10.1214/10-AOS799.full
[2] Bowman, A. W., and A. Azzalini. Applied Smoothing Techniques for Data Analysis. New York: Oxford University Press Inc., 1997.
[3] Hill, P. D. “Kernel estimation of a distribution function.” Communications in Statistics - Theory and Methods. Vol 14, Issue. 3, 1985, pp. 605-620.
[4] Jones, M. C. “Simple boundary correction for kernel density estimation.” Statistics and Computing. Vol. 3, Issue 3, 1993, pp. 135-146.
[5] Silverman, B. W. Density Estimation for Statistics and Data Analysis. Chapman & Hall/CRC, 1986.
확장 기능
버전 내역
R2006a 이전에 개발됨