이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
분포 피팅기
데이터에 확률 분포 피팅하기
설명
분포 피팅기 앱을 사용하여 확률 분포를 MATLAB® 작업 공간에서 가져온 데이터에 대화형 방식으로 피팅합니다. 22개 기본 제공 확률 분포 중에서 선택하거나 고유한 사용자 지정 분포를 생성할 수 있습니다. 앱이 피팅된 분포의 플롯을 데이터의 히스토그램에 겹쳐서 표시합니다. 사용할 수 있는 플롯으로는 확률 밀도 함수(pdf), 누적 분포 함수(cdf), 확률 플롯 및 생존 함수가 있습니다. 피팅된 파라미터 값을 확률 분포 객체로 작업 공간에 내보내고 객체 함수를 사용하여 추가 분석을 수행할 수 있습니다. 이러한 객체를 사용하는 방법에 대한 자세한 내용은 확률 분포 사용하기 항목을 참조하십시오. 분포 피팅기 앱의 프로그래밍 방식 워크플로에 대한 자세한 내용은 프로그래밍 방식으로 사용하기 항목을 참조하십시오.
필요한 제품
MATLAB
Statistics and Machine Learning Toolbox™
분포 피팅기 앱 열기
MATLAB 툴스트립: 앱 탭의 수학, 통계학 및 최적화에서 앱 아이콘을 클릭합니다.
MATLAB 명령 프롬프트:
distributionFitter를 입력합니다.
예제
carsmall 표본 데이터를 불러옵니다.
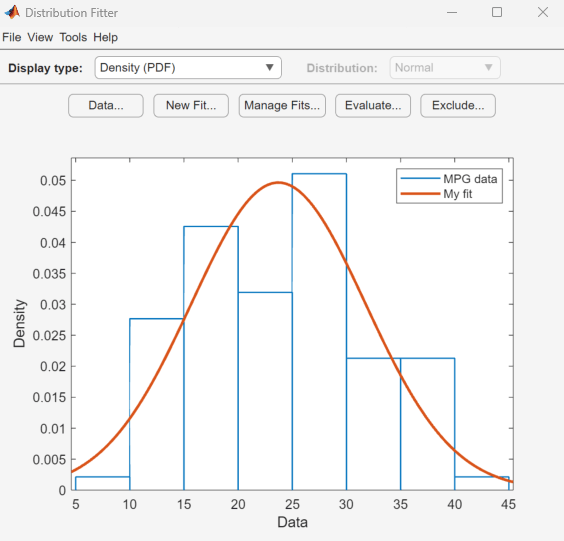
load carsmallMPG(갤런당 마일) 데이터를 사용하여 분포 피팅기 앱을 엽니다.
distributionFitter(MPG)

MPG 데이터로 채워진 분포 피팅기 앱이 열리고 밀도(PDF) 플롯이 표시됩니다. 앱을 사용하여 여러 가지 플롯을 표시하고 이 데이터에 분포를 피팅할 수 있습니다.
표본 데이터를 불러옵니다.
load lightbulb.mat데이터의 첫 번째 열은 두 가지 유형의 전구 수명(단위: 시간)을 포함합니다. 두 번째 열은 전구 유형에 대한 정보를 포함합니다. 1은 형광등을 나타내고 0은 백열등을 나타냅니다. 세 번째 열은 중도절단 정보를 포함합니다. 1은 중도절단된 데이터를 나타내고, 0은 정확한 고장 시간을 나타냅니다. 이는 시뮬레이션된 데이터입니다.
lightbulb의 첫 번째 열을 입력 데이터로 사용하고 세 번째 열을 중도절단 데이터로 사용하여 분포 피팅기 앱을 엽니다. 데이터 이름을 lifetime으로 지정합니다.
distributionFitter(lightbulb(:,1),lightbulb(:,3),[],"lifetime")
데이터 대화 상자를 열기 위해 데이터를 클릭합니다. 데이터 세트 관리 창에서 lifetime 데이터 세트 행을 클릭하여 강조 표시합니다. 마지막으로, 데이터 세트 보기 대화 상자를 열기 위해 보기를 클릭합니다. 수명 데이터는 두 번째 열에 표시되고 이에 대응되는 중도절단 표시자는 세 번째 열에 표시됩니다.
