kde
Description
[
estimates a probability density function (pdf) for the univariate data in the vector
f,xf] = kde(a)a and returns values f of the estimated pdf at
the evaluation points xf. kde uses kernel
density estimation to estimate the pdf. See Kernel Distribution for more
information.
[___] = kde(
specifies options using one or more name-value arguments. For example,
a,Name=Value)kde(a,ProbabilityFcn="cdf") estimates the cumulative distribution
function (cdf) for a instead of the pdf. Use this syntax with any of
the output argument combinations in the previous syntaxes.
Examples
Generate some normally distributed data.
rng(0,"twister") % For reproducibility a = randn(100,1);
Estimate the pdf for the sample data.
[fp,xfp] = kde(a);
fp contains the values for the estimated pdf at the evaluation points in xfp.
Estimate the cdf for the sample data.
[fc,xfc] = kde(a,ProbabilityFcn="cdf");fc contains the values for the estimated cdf at the evaluation points in xfc. xfc and xfp contain the same evaluation points because they were both calculated with the sample data in a.
Evaluate the pdf and cdf for the normal distribution at the evaluation points.
np = (1/sqrt(2*pi))*exp(-.5*(xfp.^2)); nc = 0.5*(1+erf(xfc/sqrt(2)));
Plot the estimated pdf with the normal distribution pdf.
plot(xfp,fp,"-",xfp,np,"--") legend("kde estimate","Normal density")
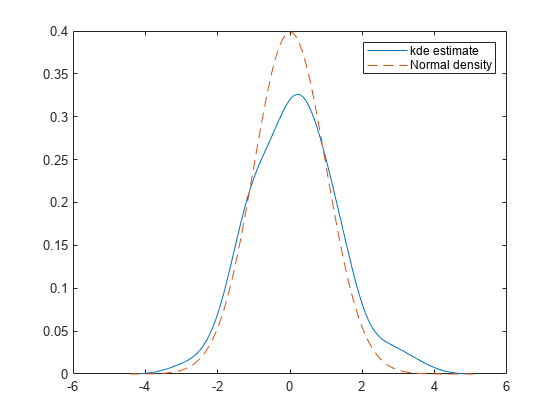
Plot the estimated pdf with the normal distribution pdf.
figure plot(xfc,fc,"-",xfc,nc,"--") legend("kde estimate","Normal cumulative",Location="northwest")
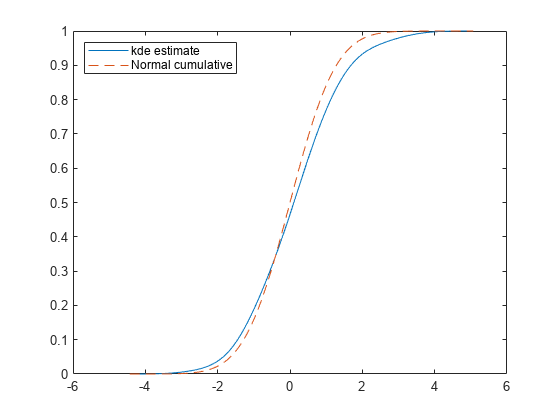
The plots show that the estimated pdf and cdf have shapes similar to the pdf and cdf of the standard normal distribution.
Generate some normally distributed data.
rng(0,"twister") % For reproducibility a = randn(100,1);
Estimate the pdf for the sample data. By default, kde uses the normal-approximation method to calculate the bandwidth for the kernel smoothing function.
[fn,xfn,bwn] = kde(a);
fn contains the values for the estimated pdf at the evaluation points in xfn, and bwn is the bandwidth for the kernel smoothing function.
Estimate the pdf using the plug-in method, and display the bandwidth associated with each estimated pdf.
[p,xp,bwp] = kde(a,Bandwidth="plug-in");
[bwn,bwp]ans = 1×2
0.4958 0.5751
The bandwidth calculated with the normal-approximation method is less than the bandwidth calculated with the plug-in method.
Plot the estimated pdfs.
plot(xfn,fn) hold on plot(xp,p) legend("normal-approx","plug-in")
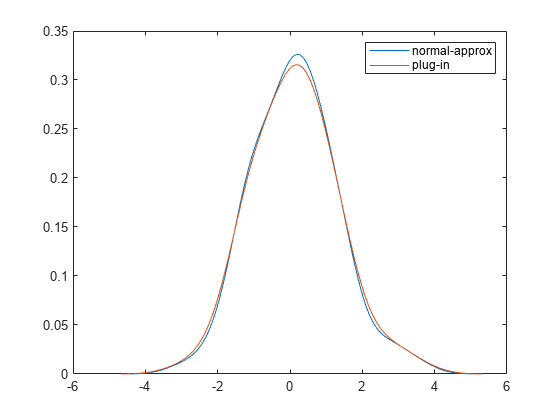
The estimated pdfs have shapes typical of a normal distribution. The peak of the pdf corresponding to the normal-approximation method is higher than the peak of the pdf corresponding to the plug-in method.
Generate some bimodal sample data.
rng(0,"twister") % For reproducibility a = [randn(100,1)-5; randn(20,1)+5];
Use the default "normal" kernel smoothing function to estimate the pdf for the sample data. Use the "box", "triangle", and "parabolic" kernel smoothing functions to calculate three more estimates for the pdf.
[f1,xf1] = kde(a); [f2,xf2] = kde(a,Kernel="box"); [f3,xf3] = kde(a,Kernel="triangle"); [f4,xf4] = kde(a,Kernel="parabolic");
xf1, xf2, xf3, and xf4 contain the same evaluation points because they were each calculated with the sample data in a. f1, f2, f3, and f4 contain the values of each estimated pdf at the evaluation points.
Plot the estimated pdfs.
tiledlayout(2,2) nexttile plot(xf1,f1) % normal nexttile plot(xf2,f2) % box nexttile plot(xf3,f3) % triangle nexttile plot(xf4,f4) % parabolic

The plots show that the four estimated pdfs have similar vertical ranges and two peaks each. The pdf calculated with the "box" kernel appears to be the least smooth of the four estimates.
Input Arguments
Name-Value Arguments
Output Arguments
More About
References
[1] Botev, Z. I., J. F. Grotowski, and D. P. Kroese. "Kernel Density Estimation via Diffusion." The Annals of Statistics, vol. 38, no. 5 (October 1, 2010). https://projecteuclid.org/journals/annals-of-statistics/volume-38/issue-5/Kernel-density-estimation-via-diffusion/10.1214/10-AOS799.full
[2] Bowman, A. W., and A. Azzalini. "Applied Smoothing Techniques for Data Analysis." New York: Oxford University Press Inc., 1997.
[3] Hill, P. D. "Kernel estimation of a distribution function." Communications in Statistics - Theory and Methods. 14, no. 3(January 1985): 605–620.
[4] Jones, M. C. "Simple boundary correction for kernel density estimation." Statistics and Computing. no. 3(September 1993): 135–146.
[5] Silverman, B. W. "Density Estimation for Statistics and Data Analysis." Chapman & Hall/CRC, 1986.
Version History
Introduced in R2023bSee Also
Functions
histogram|histcounts(Statistics and Machine Learning Toolbox) |ksdensity(Statistics and Machine Learning Toolbox)
Topics
- Kernel Distribution (Statistics and Machine Learning Toolbox)
- Nonparametric and Empirical Probability Distributions (Statistics and Machine Learning Toolbox)