cdf
누적 분포 함수
구문
설명
y = cdf(___,'upper')는 극단 위쪽 꼬리 확률을 더 정확하게 계산하는 알고리즘을 사용하여 cdf의 여분포(complement of cdf)를 반환합니다. 'upper'는 위에 열거된 구문의 모든 입력 인수 다음에 올 수 있습니다.
예제
분포 이름 'Normal' 및 분포 모수를 지정하여 정규분포에 대한 cdf 값을 계산합니다.
cdf를 계산할 지점의 값을 포함하도록 입력 벡터 x를 정의합니다.
x = [-2,-1,0,1,2];
평균 가 1이고 표준편차 가 5인 정규분포에 대한 cdf 값을 계산합니다.
mu = 1;
sigma = 5;
y = cdf('Normal',x,mu,sigma)y = 1×5
0.2743 0.3446 0.4207 0.5000 0.5793
y의 각 값은 입력 벡터 x의 값에 대응됩니다. 예를 들어, 값 x가 1인 경우 이 값에 대응되는 cdf 값 y는 0.5000입니다.
정규분포 객체를 생성하고 이 객체를 사용하여 정규분포의 cdf 값을 계산합니다.
평균 가 1이고 표준편차 가 5인 정규분포 객체를 생성합니다.
mu = 1; sigma = 5; pd = makedist('Normal','mu',mu,'sigma',sigma);
cdf를 계산할 지점의 값을 포함하도록 입력 벡터 x를 정의합니다.
x = [-2,-1,0,1,2];
x의 값에서 정규분포에 대한 cdf 값을 계산합니다.
y = cdf(pd,x)
y = 1×5
0.2743 0.3446 0.4207 0.5000 0.5793
y의 각 값은 입력 벡터 x의 값에 대응됩니다. 예를 들어, 값 x가 1인 경우 이 값에 대응되는 cdf 값 y는 0.5000입니다.
사건 발생률 모수 가 2인 푸아송 분포 객체를 생성합니다.
lambda = 2; pd = makedist('Poisson','lambda',lambda);
cdf를 계산할 지점의 값을 포함하도록 입력 벡터 x를 정의합니다.
x = [0,1,2,3,4];
x의 값에서 푸아송 분포에 대한 cdf 값을 계산합니다.
y = cdf(pd,x)
y = 1×5
0.1353 0.4060 0.6767 0.8571 0.9473
y의 각 값은 입력 벡터 x의 값에 대응됩니다. 예를 들어, 값 x가 3인 경우 이 값에 대응되는 cdf 값 y는 0.8571입니다.
또는 확률 분포 객체를 생성하지 않고 동일한 cdf 값을 계산할 수도 있습니다. cdf 함수를 사용하고 동일한 사건 발생률 모수 의 값을 사용하여 푸아송 분포를 지정하면 됩니다.
y2 = cdf('Poisson',x,lambda)y2 = 1×5
0.1353 0.4060 0.6767 0.8571 0.9473
cdf 값이 확률 분포 객체를 사용하여 계산된 값과 동일합니다.
표준 정규분포 객체를 생성합니다.
pd = makedist('Normal')pd =
NormalDistribution
Normal distribution
mu = 0
sigma = 1
x 값을 지정하고 cdf를 계산합니다.
x = -3:.1:3; p = cdf(pd,x);
표준 정규분포의 cdf를 플로팅합니다.
plot(x,p)

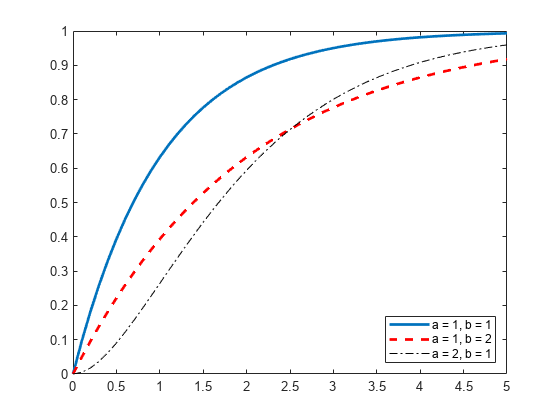
3개의 감마 분포 객체를 생성합니다. 첫 번째 객체는 디폴트 모수 값을 사용합니다. 두 번째 객체는 a = 1과 b = 2를 지정합니다. 세 번째 객체는 a = 2와 b = 1을 지정합니다.
pd_gamma = makedist('Gamma')pd_gamma =
GammaDistribution
Gamma distribution
a = 1
b = 1
pd_12 = makedist('Gamma','a',1,'b',2)
pd_12 =
GammaDistribution
Gamma distribution
a = 1
b = 2
pd_21 = makedist('Gamma','a',2,'b',1)
pd_21 =
GammaDistribution
Gamma distribution
a = 2
b = 1
x 값을 지정하고 각 분포에 대해 cdf를 계산합니다.
x = 0:.1:5; cdf_gamma = cdf(pd_gamma,x); cdf_12 = cdf(pd_12,x); cdf_21 = cdf(pd_21,x);
형태 모수 a와 b에 대해 각기 다른 값을 지정할 때 감마 분포의 cdf가 어떻게 달라지는지를 시각화하는 플롯을 생성합니다.
figure; J = plot(x,cdf_gamma); hold on; K = plot(x,cdf_12,'r--'); L = plot(x,cdf_21,'k-.'); set(J,'LineWidth',2); set(K,'LineWidth',2); legend([J K L],'a = 1, b = 1','a = 1, b = 2','a = 2, b = 1','Location','southeast'); hold off;
누적 확률 0.1 및 0.9에서 분포에 파레토 꼬리를 피팅합니다.
t = trnd(3,100,1); obj = paretotails(t,0.1,0.9); [p,q] = boundary(obj)
p = 2×1
0.1000
0.9000
q = 2×1
-1.8487
2.0766
q의 값에서 cdf를 계산합니다.
cdf(obj,q)
ans = 2×1
0.1000
0.9000
입력 인수
출력 인수
대체 기능
cdf는 분포 이름name으로 지정한 분포를 받거나 확률 분포 객체pd를 받는 일반 함수입니다. 분포 전용 함수(정규분포의 경우normcdf, 이항분포의 경우binocdf)를 사용하는 것이 더 빠릅니다. 분포 전용 함수 목록은 지원되는 분포 항목을 참조하십시오.확률 분포 함수 툴을 사용하면 확률 분포에 대한 누적 분포 함수(cdf) 또는 확률 밀도 함수(pdf)의 대화형 방식 플롯을 생성할 수 있습니다.