이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
ecdf
경험적 누적 분포 함수
설명
[는 하나 이상의 이름-값 인수를 사용하여 옵션을 추가로 지정합니다. 예를 들어 f,x] = ecdf(y,Name,Value)'Function','survivor'f의 함수 유형을 생존 함수로 지정합니다.
예제
시뮬레이션된 생존 데이터에 대한 경험적 누적 분포 함수(cdf)의 카플란-마이어 추정값(Kaplan-Meier Estimate)을 계산합니다.
모수 3과 1을 사용하여 베이불 분포에서 생존 데이터를 생성합니다.
rng('default') % For reproducibility failuretime = random('wbl',3,1,15,1);
생존 데이터에 대한 경험적 cdf의 카플란-마이어 추정값을 계산합니다.
[f,x] = ecdf(failuretime); [f,x]
ans = 16×2
0 0.0895
0.0667 0.0895
0.1333 0.1072
0.2000 0.1303
0.2667 0.1313
0.3333 0.2718
0.4000 0.2968
0.4667 0.6147
0.5333 0.6684
0.6000 1.3749
0.6667 1.8106
0.7333 2.1685
0.8000 3.8350
0.8667 5.5428
0.9333 6.1910
⋮
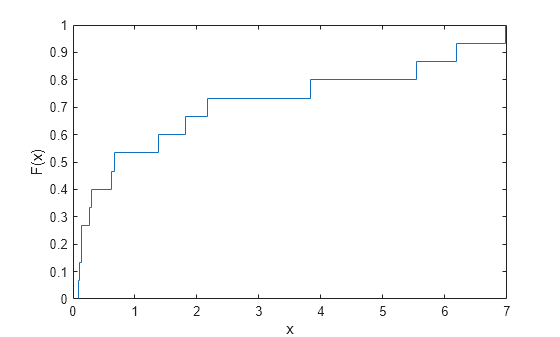
추정된 경험적 cdf를 플로팅합니다.
ecdf(failuretime)
우측 중도절단된 데이터를 생성하고 경험적 누적 분포 함수(cdf)를 알려진 cdf와 비교합니다.
평균 고장 시간이 15인 지수 분포에서 고장 시간을 생성합니다.
rng('default') % For reproducibility y = exprnd(15,75,1);
평균 고장 시간이 30인 지수 분포에서 중도탈락 시간을 생성합니다.
d = exprnd(30,75,1);
관측된 고장 시간, 즉 생성된 고장 시간과 중도탈락 시간의 최솟값을 생성합니다.
t = min(y,d);
중도탈락 시간보다 긴, 생성된 고장 시간을 포함하는 논리형 배열을 생성합니다. 아래 조건이 참인 데이터는 중도절단됩니다.
censored = (y>d);
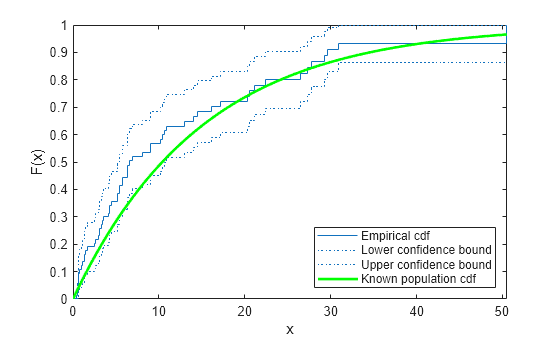
경험적 cdf와 신뢰한계를 계산합니다.
[f,x,flo,fup] = ecdf(t,'Censoring',censored);경험적 cdf와 신뢰한계를 플로팅합니다.
ecdf(t,'Censoring',censored,'Bounds','on') hold on

알려진 모집단 cdf의 플롯을 겹쳐 놓습니다.
xx = 0:.1:max(t); yy = 1-exp(-xx/15); plot(xx,yy,'g-','LineWidth',2) axis([0 max(t) 0 1]) legend('Empirical cdf','Lower confidence bound', ... 'Upper confidence bound','Known population cdf', ... 'Location','southeast') hold off
생존 데이터를 생성하고 99% 신뢰한계를 갖는 경험적 생존 함수를 플로팅합니다.
모수 100과 2를 사용하여 베이불 분포에서 수명 데이터를 생성합니다.
rng('default') % For reproducibility R = wblrnd(100,2,100,1);
99% 신뢰한계를 갖는 데이터에 대한 경험적 생존 함수를 플로팅합니다.
ecdf(R,'Function','survivor','Alpha',0.01,'Bounds','on') hold on

베이불 생존 함수의 플롯을 겹쳐 놓습니다.
x = 1:1:250; wblsurv = 1-cdf('weibull',x,100,2); plot(x,wblsurv,'g-','LineWidth',2) legend('Empirical survivor function','Lower confidence bound', ... 'Upper confidence bound','Weibull survivor function', ... 'Location','northeast')

실제 분포를 기반으로 한 베이불 생존 함수는 신뢰한계 내에 있습니다.
시뮬레이션된 양측 중도절단된 생존 데이터의 누적 위험 함수를 계산하고 플로팅합니다.
번바움-손더스(Birnbaum-Saunders) 분포에서 고장 시간을 생성합니다.
rng('default') % For reproducibility failuretime = random('BirnbaumSaunders',0.3,1,[100,1]);
연구가 시간 0.1에서 시작하고 시간 0.9에서 끝난다고 가정합니다. 이 가정은 0.1보다 작은 고장 시간은 좌측 중도절단되고 0.9보다 큰 고장 시간은 우측 중도절단됨을 의미합니다.
각 요소가 failuretime의 대응되는 관측값에 대한 중도절단 상태를 나타내는 벡터를 생성합니다. –1, 1 및 0을 사용하여 각각 좌측 중도절단된 관측값, 우측 중도절단된 관측값 및 완전히 관측된 관측값을 나타냅니다.
L = 0.1; U = 0.9; left_censored = (failuretime<L); right_censored = (failuretime>U); c = right_censored - left_censored;
95% 신뢰한계를 갖는 데이터에 대한 경험적 누적 위험 함수를 플로팅합니다.
ecdf(failuretime,'Function','cumulative hazard', ... 'Censoring',c,'Bounds','on')

구간 중도절단된 데이터의 경험적 cdf를 계산하고 플로팅합니다.
cities 데이터 세트를 불러옵니다. 데이터는 기후, 주택 시장, 건강, 범죄, 교통, 교육, 예술, 취미, 경제의 9가지 삶의 질 지표에 대한 미국 329개 도시의 평점을 포함합니다. 각 지표에 대해 평점이 높을수록 더 좋습니다.
load cities첫 번째 지표(기후)를 표본 데이터로 선택합니다.
Y = ratings(:,1);
Y의 지표는 가장 가까운 정수로 반올림된 값이라고 가정합니다. 이렇게 하면 Y에 있는 값을 구간 중도절단된 관측값으로 처리할 수 있습니다. Y의 관측값 y는 실제 평점이 y–0.5와 y+0.5 사이에 있음을 나타냅니다.
각 행이 Y의 각 정수를 둘러싸는 구간을 나타내는 행렬을 생성합니다.
intervalY = [Y-0.5, Y+0.5];
경험적 cdf 값을 계산합니다.
[f,x] = ecdf(intervalY);
경험적 cdf 값을 플로팅합니다.
figure ecdf(intervalY)
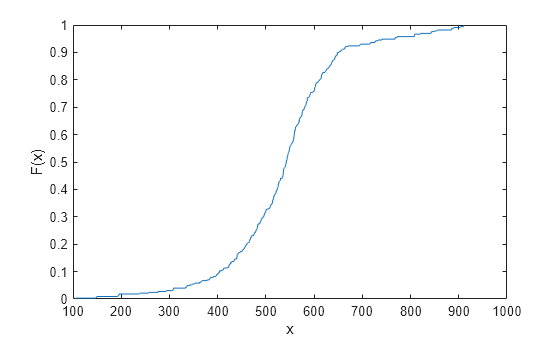
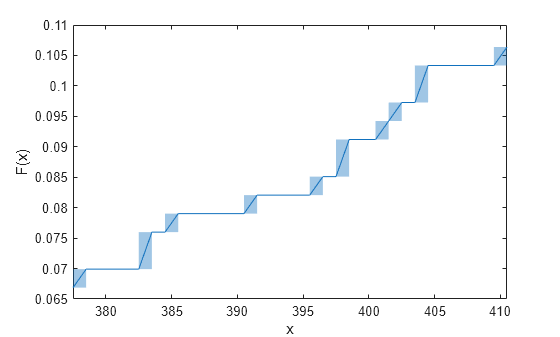
더 작은 영역을 확대하여 구간 추정값을 봅니다.
idx_roi = 21:30; xlim([x(idx_roi(1),1) x(idx_roi(end),2)])
대응되는 x 값 및 f 값을 표시합니다.
table(idx_roi',x(idx_roi,:),f(idx_roi,:), ... 'VariableNames',{'Index','x','Empirical cdf F(x)'})
ans=10×3 table
Index x Empirical cdf F(x)
_____ ______________ __________________
21 377.5 378.5 0.069909
22 382.5 383.5 0.075988
23 384.5 385.5 0.079027
24 390.5 391.5 0.082067
25 395.5 396.5 0.085106
26 397.5 398.5 0.091185
27 400.5 401.5 0.094225
28 401.5 402.5 0.097264
29 403.5 404.5 0.10334
30 409.5 410.5 0.10638
음영 사각형은 대응되는 구간 내에서 경험적 cdf 값 F(x)가 변경됨을 나타냅니다. 예를 들어, 확대된 플롯의 왼쪽에서 두 번째 음영 사각형은 구간 (382.5,383.5]에 해당합니다. F(382.5)는 0.075988이고 F(383.5)는 0.079027이므로, 구간 (382.5,383.5]에서 0.075988에서 0.079027로 변경된 것입니다. 정확한 변경 시간은 불분명합니다.
다양한 방법으로 구간 추정값을 플로팅할 수 있습니다. 각 구간의 시작 부분에서 확률 변경이 발생한다고 가정하는 경우 x의 첫 번째 열을 사용하여 F(x) 값을 플로팅할 수 있습니다.
figure stairs(x(:,1),f) title('Probability changes at the start') xlabel('x') ylabel('F(x)') xlim([x(idx_roi(1),1) x(idx_roi(end),2)])
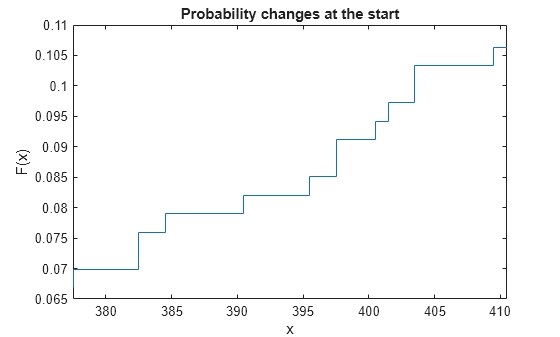
또는 각 구간의 끝부분에서 확률 변경이 발생한다고 가정하는 경우 x의 두 번째 열을 사용하여 F(x) 값을 플로팅할 수 있습니다.
figure stairs(x(:,2),f) title('Probability changes at the end') xlabel('x') ylabel('F(x)') xlim([x(idx_roi(1),1) x(idx_roi(end),2)])
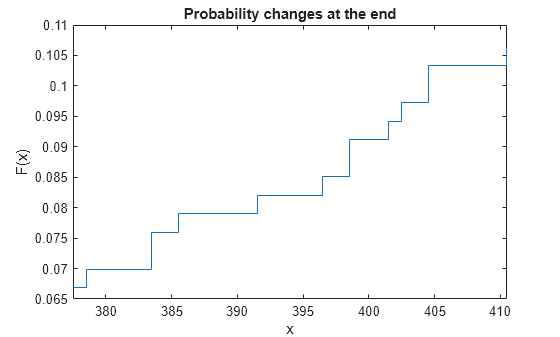
앞의 두 개 플롯을 합쳐서 구간을 시각화합니다.
figure stairs(x(:,1),f) hold on stairs(x(:,2),f) title('Probability changes in the interval') xlabel('x') ylabel('F(x)') xlim([x(idx_roi(1),1) x(idx_roi(end),2)]) hold off

데이터에 대한 경험적 누적 분포 함수(cdf)를 계산하고, 경험적 cdf에 대한 근삿값을 사용하여 조각별 선형 분포 객체를 만듭니다.
표본 데이터를 불러옵니다. 히스토그램을 사용하여 환자의 체중 데이터를 시각화합니다.
load patients histogram(Weight(strcmp(Gender,'Female'))) hold on histogram(Weight(strcmp(Gender,'Male'))) legend('Female','Male')
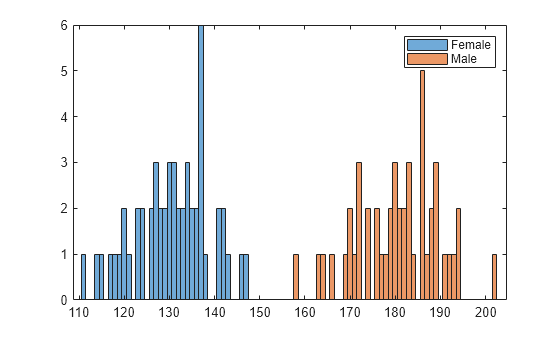
히스토그램에서 데이터가 두 개의 최빈값을 가진 것을 알 수 있습니다. 하나는 여성 환자에 대한 최빈값이고 다른 하나는 남성 환자에 대한 최빈값입니다.
데이터에 대한 경험적 cdf를 계산합니다.
[f,x] = ecdf(Weight);
5개 점마다 값을 취하여 조각별 선형 근삿값을 생성합니다.
f = f(1:5:end); x = x(1:5:end);
경험적 cdf와 근삿값을 플로팅합니다.
figure ecdf(Weight) hold on plot(x,f,'ko-','MarkerFace','r') legend('Empirical cdf','Piecewise linear approximation', ... 'Location','best')
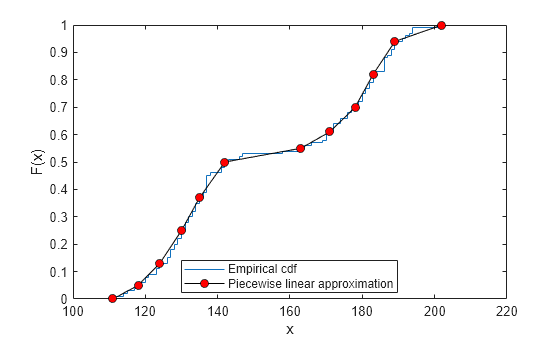
경험적 cdf의 조각별 근삿값을 사용하여 조각별 선형 확률 분포 객체를 생성합니다.
pd = makedist('PiecewiseLinear','x',x,'Fx',f)
pd = PiecewiseLinearDistribution F(111) = 0 F(118) = 0.05 F(124) = 0.13 F(130) = 0.25 F(135) = 0.37 F(142) = 0.5 F(163) = 0.55 F(171) = 0.61 F(178) = 0.7 F(183) = 0.82 F(189) = 0.94 F(202) = 1
분포에서 100개의 난수를 생성합니다.
rng('default') % For reproducibility rw = random(pd,[100,1]);
난수를 플로팅하여 해당 분포와 원래 데이터를 시각적으로 비교합니다.
figure histogram(Weight) hold on histogram(rw) legend('Original data','Generated data')
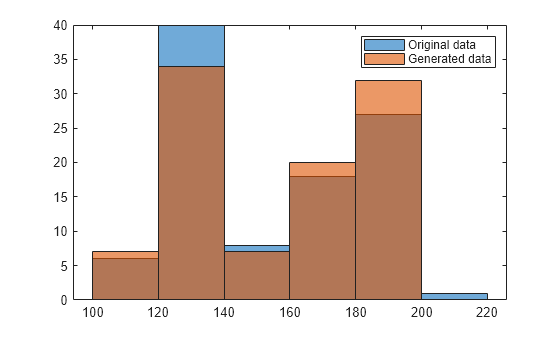
조각별 선형 분포에서 생성된 난수는 원래 데이터와 동일한 이봉 분포를 가집니다.
입력 인수
이름-값 인수
출력 인수
세부 정보
알고리즘
ecdf는 중도절단 정보에 따라 다양한 알고리즘을 사용하여 함수 값(f)과 신뢰한계(flo 및 fup)를 계산합니다. f의 함수 유형은 Function 이름-값 인수로 지정된 대로 cdf(디폴트 값), 생존 함수 또는 누적 위험 함수일 수 있습니다.
| 중도절단 유형 | f의 알고리즘 | flo 및 fup의 알고리즘 |
|---|---|---|
| 우측 중도절단된 데이터 - 완전히 관측된 관측값 또는 우측 중도절단된 관측값 포함 |
| 카플란-마이어 추정량의 분산에 대한 근삿값인 그린우드의 공식(Greenwood’s Formula)을 사용합니다. 분산 추정값은 다음과 같이 지정됩니다. |
| 좌측 중도절단된 데이터 - 완전히 관측된 관측값 또는 좌측 중도절단된 관측값 포함 | 카플란-마이어 추정량을 사용합니다. | 그린우드의 공식(Greenwood’s Formula)을 사용합니다. |
| 양측 중도절단된 데이터 - 우측 중도절단된 관측값과 좌측 중도절단된 관측값을 모두 포함 | Turnbull의 알고리즘[3][4]을 사용합니다. 알고리즘에 사용할 최대 반복 횟수( | 피셔 정보 행렬을 사용합니다. |
| 구간 중도절단된 데이터 - 구간 중도절단된 관측값 포함 |
| 지원되지 않습니다. |
참고 문헌
[1] Cox, D. R., and D. Oakes. Analysis of Survival Data. London: Chapman & Hall, 1984.
[2] Lawless, J. F. Statistical Models and Methods for Lifetime Data. 2nd ed., Hoboken, NJ: John Wiley & Sons, Inc., 2003.
[3] Klein, John P., and Melvin L. Moeschberger. Survival Analysis: Techniques for Censored and Truncated Data. 2nd ed. Statistics for Biology and Health. New York: Springer, 2003.
[4] Turnbull, Bruce W. "Nonparametric Estimation of a Survivorship Function with Doubly Censored Data." Journal of the American Statistical Association 69, No. 345 (1974): 169–73.
[5] Anderson-Bergman, Clifford. "An Efficient Implementation of the EMICM Algorithm for the Interval Censored NPMLE." Journal of Computational and Graphical Statistics 26, no. 2 (April 3, 2017): 463–67.
[6] Ware, James H., and David L. Demets. "Reanalysis of Some Baboon Descent Data." Biometrics 32, no. 2 (June 1976): 459–63.
확장 기능
버전 내역
R2006a 이전에 개발됨