이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
histfit
분포가 피팅된 히스토그램
설명
histfit(는 data)data에 포함된 요소 개수에 대한 제곱근과 같은 Bin 개수를 사용하여 data의 값에 대한 히스토그램을 플로팅하고 정규 밀도 함수를 피팅합니다.
예제
평균이 10이고 분산이 1인 정규분포에서 크기가 100인 표본을 생성합니다.
rng default; % For reproducibility r = normrnd(10,1,100,1);
정규분포가 피팅된 히스토그램을 생성합니다.
histfit(r)

histfit은 fitdist를 사용하여 분포를 데이터에 피팅합니다. 피팅에 사용되는 모수를 가져오려면 fitdist를 사용하십시오.
pd = fitdist(r,'Normal')pd =
NormalDistribution
Normal distribution
mu = 10.1231 [9.89244, 10.3537]
sigma = 1.1624 [1.02059, 1.35033]
모수 추정값 다음에 있는 구간은 분포 모수에 대한 95% 신뢰구간입니다.
평균이 10이고 분산이 1인 정규분포에서 크기가 100인 표본을 생성합니다.
rng default; % For reproducibility r = normrnd(10,1,100,1);
6개 Bin을 사용하여 정규분포가 피팅된 히스토그램을 생성합니다.
histfit(r,6)

모수 (3,10)을 사용하여 베타 분포에서 크기가 100인 표본을 생성합니다.
rng default; % For reproducibility b = betarnd(3,10,100,1);
10개 Bin을 사용하여 베타 분포가 피팅된 히스토그램을 생성합니다.
histfit(b,10,'beta')
모수 (3,10)을 사용하여 베타 분포에서 크기가 100인 표본을 생성합니다.
rng default; % For reproducibility b = betarnd(3,10,[100,1]);
10개 Bin을 사용하여 평활화 함수가 피팅된 히스토그램을 생성합니다.
histfit(b,10,'kernel')
평균이 3이고 분산이 1인 정규분포에서 크기가 100인 표본을 생성합니다.
rng('default') % For reproducibility r = normrnd(3,1,100,1);
두 개의 서브플롯이 있는 Figure를 만들고 Axes 객체를 ax1 및 ax2로 반환합니다. 대응되는 Axes 객체를 참조하여 각 좌표축 세트에 정규분포가 피팅된 히스토그램을 만듭니다. 왼쪽 서브플롯에 10개 Bin이 있는 히스토그램을 플로팅합니다. 오른쪽 서브플롯에 5개 Bin이 있는 히스토그램을 플로팅합니다. 대응되는 Axes 객체를 title 함수로 전달하여 각 플롯에 제목을 추가합니다.
ax1 = subplot(1,2,1); % Left subplot histfit(ax1,r,10,'normal') title(ax1,'Left Subplot') ax2 = subplot(1,2,2); % Right subplot histfit(ax2,r,5,'normal') title(ax2,'Right Subplot')

평균이 10이고 분산이 1인 정규분포에서 크기가 100인 표본을 생성합니다.
rng default % for reproducibility r = normrnd(10,1,100,1);
정규분포가 피팅된 히스토그램을 생성합니다.
h = histfit(r,10,'normal')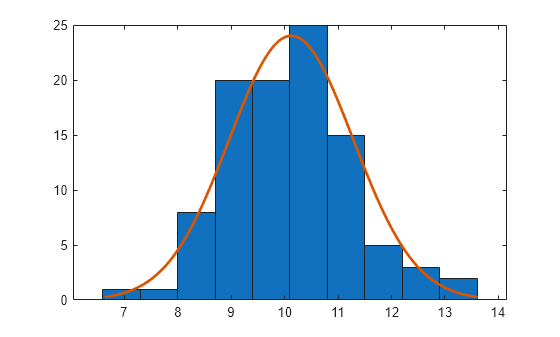
h = 2×1 graphics array: Bar Line
히스토그램의 막대 색을 변경합니다.
h(1).FaceColor = [.8 .8 1];
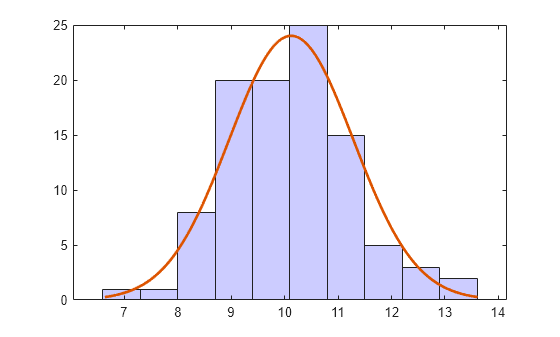
밀도 곡선의 색을 변경합니다.
h(2).Color = [.2 .2 .2];

입력 인수
출력 인수
알고리즘
histfit은 fitdist를 사용하여 분포를 데이터에 피팅합니다. 피팅에 사용되는 모수를 가져오려면 fitdist를 사용하십시오.
확장 기능
버전 내역
R2006a 이전에 개발됨