객체 검출
Computer Vision Toolbox™는 딥러닝과 전통적인 컴퓨터 비전 기법을 모두 사용하여 객체 검출 모델을 구축, 훈련, 평가 및 배포할 수 있는 포괄적인 툴과 함수를 제공합니다. 영상 레이블 지정기 앱과 비디오 레이블 지정기 앱을 사용하여 레이블이 지정된 ground truth를 만드는 것부터 시작할 수 있습니다. 이 두 앱은 대화형 및 AI 지원 방식으로 영상과 비디오 프레임에서 객체를 둘러싸는 경계 상자를 주석 처리하는 작업을 지원합니다.
데이터에 레이블을 지정한 후에는 YOLO v2, YOLO v3, YOLO v4, YOLOX, RTMDet, SSD, Grounding DINO 등 다양한 사전 훈련된 딥러닝 객체 검출기 중에서 선택할 수 있습니다. 이 툴박스에는 peopleDetector 및 faceDetector와 같이 사람 인식 작업과 얼굴 인식 작업에 특화된 검출기도 포함되어 있습니다. 이러한 모델을 바로 추론에 사용하거나, 전이 학습의 시작점으로 사용하여 특정 데이터 세트와 응용 분야에 맞게 사용자 지정할 수 있습니다. 자세한 내용은 Get Started with Object Detection Using Deep Learning 항목을 참조하십시오. 고전적인 객체 검출 방법을 위해, 이 툴박스에는 ACF(Aggregate Channel Features)와 캐스케이드(Viola-Jones) 객체 검출기에 대한 지원이 포함되어 있습니다.
이 툴박스는 전이 학습을 사용하여 객체 검출기를 훈련시킬 수 있는 함수를 제공합니다. 또한 이 툴박스는 훈련 데이터를 관리하고 전처리하는 기능과 데이터 증강 툴을 제공하여, 실제 환경의 변화를 시뮬레이션함으로써 강인한 모델로 훈련시킵니다. 자세한 내용은 Get Started with Image Preprocessing and Augmentation for Deep Learning 항목을 참조하십시오.
사전 훈련된 모델이나 사용자 지정 모델을 사용하여 검출을 생성한 후에는 객체 검출기 분석기 앱을 사용하여 검출 결과를 ground truth 데이터와 비교할 수 있습니다. 이 앱을 사용하면 다양한 IoU(Intersection over Union) 임계값 범위에서 혼동행렬, 정밀도, 재현율, F1 점수, mAP(mean Average Precision)와 같은 주요 성능 메트릭을 평가할 수 있습니다. 또는 evaluateObjectDetection 함수를 사용하여 검출 성능 메트릭을 평가할 수 있습니다. 자세한 내용은 Evaluate Object Detector Performance 항목과 Get Started with Object Detector Analyzer App 항목을 참조하십시오.

앱
| 영상 레이블 지정기 | 컴퓨터 비전 응용 분야에서 영상에 레이블 지정 |
| 비디오 레이블 지정기 | Label video for computer vision applications |
| 객체 검출기 분석기 | Interactively visualize and evaluate object detection results against ground truth (R2026a 이후) |
함수
블록
| Deep Learning Object Detector | 훈련된 딥러닝 객체 검출기를 사용하여 객체 검출 (R2021b 이후) |
도움말 항목
객체 검출을 위한 Ground Truth 및 훈련 데이터 만들기
- Get Started with the Image Labeler
Interactively label rectangular ROIs for object detection, pixels for semantic segmentation, polygons for instance segmentation, and scenes for image classification. - Get Started with the Video Labeler
Interactively label rectangular ROIs for object detection, pixels for semantic segmentation, polygons for instance segmentation, and scenes for image classification in a video or image sequence. - Training Data for Object Detection and Semantic Segmentation
Create training data for object detection or semantic segmentation using the Image Labeler or Video Labeler. - Get Started with Image Preprocessing and Augmentation for Deep Learning
Preprocess data for deep learning applications with deterministic operations such as resizing, or augment training data with randomized operations such as random cropping.
사전 훈련된 검출기를 사용하여 객체 검출
- Get Started with Object Detection Using Deep Learning
Perform object detection using deep learning neural networks such as YOLOX, YOLO v4, RTMDet, and SSD. - Choose an Object Detector
Compare object detection deep learning models, such as YOLOX, YOLO v4, RTMDet, and SSD. - Get Started with Cascade Object Detector
Train a custom classifier. - MATLAB의 딥러닝 (Deep Learning Toolbox)
사전 훈련된 신경망 및 전이 학습, 그리고 GPU, CPU, 클러스터 및 클라우드에서의 훈련 등 분류 및 회귀에 컨벌루션 신경망을 사용하여 MATLAB®의 딥러닝 기능을 알아봅니다. - 사전 훈련된 심층 신경망 (Deep Learning Toolbox)
분류, 전이 학습 및 특징 추출을 위해 사전 훈련된 컨벌루션 신경망을 다운로드하고 사용하는 방법을 알아봅니다.
객체 검출 결과 평가
- Evaluate Object Detector Performance
Evaluate object detector performance using metrics such as average precision, precision recall, and confusion matrix. - Get Started with Object Detector Analyzer App
Use Object Detector Analyzer app to evaluate pretrained object detectors or precomputed detection results against the ground truth data, and evaluate performance metrics. - Calibrate Object Detection Confidence Scores
This example shows how to calibrate the confidence scores of an object using Platt scaling.
추천 예제

Automatically Search and Label Video Frames Using VLMs
Automatically search and detect objects based on natural language text queries using vision-language models (VLMs).
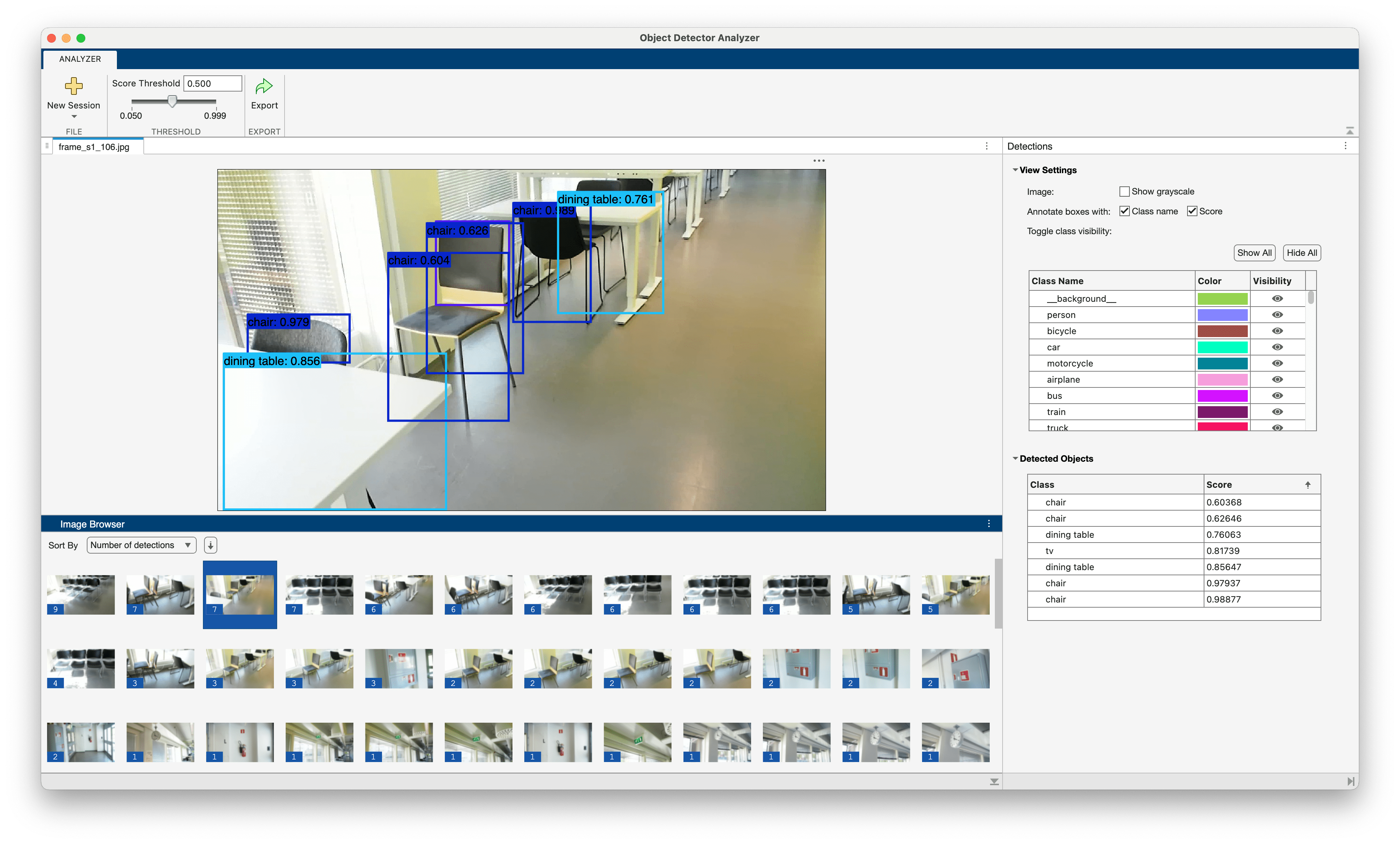
Visualize Object Detection Results from Pretrained PyTorch Model
Detect objects using a pretrained PyTorch® model and visualize the results in Object Detector Analyzer.
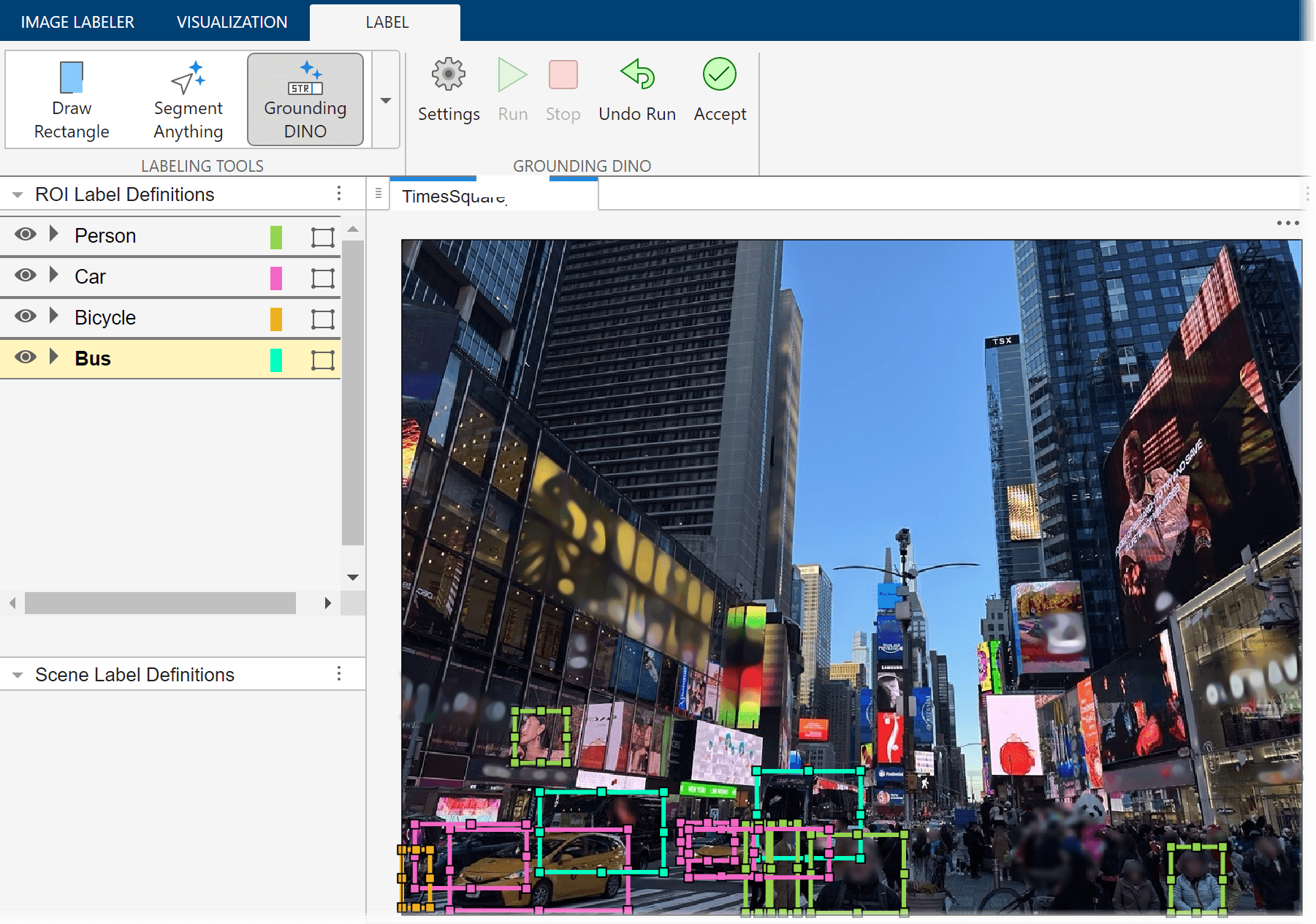
Automatically Label Ground Truth Using Vision-Language Model
Automatically label ground truth images for object detection using the Grounding DINO vision-language model (VLM).

Detect Small Objects Using Tiled Training of YOLOX Network
Detect small objects in full-resolution images using tiled training of a you only look once version X (YOLOX) deep learning network.

Object Detection in Large Satellite Imagery Using Deep Learning
Perform object detection on large satellite imagery using deep learning.

YOLO v4 딥러닝을 사용한 객체 검출
이 예제에서는 YOLO v4(You Only Look Once Version 4) 딥러닝 신경망을 사용하여 영상에서 객체를 검출하는 방법을 보여줍니다. 이 예제에서는 다음을 수행합니다

Multiclass Object Detection Using YOLO v2 Deep Learning
Train a YOLO v2 multiclass object detector and evaluate object detector performance across selected classes and overlap thresholds.

Train Object Detectors in Experiment Manager
Use the Experiment Manager app to find optimal training options for object detectors.

영상 특징점을 사용하여 복잡한 장면에서 객체 찾기
이 예제에서는 객체의 참조 영상이 주어졌을 때 복잡한 장면에서 특정 객체를 검출하는 방법을 보여줍니다.

Detect Cars Using Gaussian Mixture Models
Detect and count cars in a video sequence using foreground detector based on Gaussian mixture models (GMMs).

Import Pretrained ONNX YOLO v2 Object Detector
Import pretrained YOLO v2 object detector from ONNX deep learning framework.
Export YOLO v2 Object Detector to ONNX
Export pretrained YOLO v2 object detector to ONNX deep learning framework.

Generate Code for Detecting Objects in Images by Using ACF Object Detector
Generate code from a MATLAB® function that detects objects in images by using an acfObjectDetector object. When you intend to generate code from your MATLAB function that uses an acfObjectDetector object, you must create the object outside of the MATLAB function. The example explains how to modify the MATLAB code in Train Stop Sign Detector Using ACF Object Detector to support code generation.

YOLO v2를 사용하여 객체 검출을 위한 코드 생성하기
YOLO v2를 사용하여 객체 검출을 위한 CUDA® 코드를 생성합니다.

Code Generation for Object Detection by Using Single Shot Multibox Detector
Generate CUDA code for an SSD network.

Code Generation for People Detection Using Deep Learning
Generate CUDA code for people detection