인스턴스 분할
Computer Vision Toolbox™의 인스턴스 분할 툴을 사용하면 여러 객체가 중첩되어 있는 경우에도 영상 내의 개별 객체를 검출, 분류, 분할할 수 있습니다. 영상 레이블 지정기 앱과 비디오 레이블 지정기 앱을 사용하여 레이블이 지정된 ground truth를 만드는 것부터 시작할 수 있습니다. 이 두 앱은 대화형 및 AI 지원 방식으로 객체 인스턴스에 대해 다각형 ROI나 사각형 ROI를 사용한 주석 처리를 지원합니다. 자세한 내용은 Label Objects Using Polygons for Instance Segmentation 항목을 참조하십시오.
이 툴박스는 SOLOv2, Mask R-CNN과 같은 사전 훈련된 인스턴스 분할 신경망을 제공합니다. 이러한 모델을 바로 추론에 사용하거나 전이 학습을 통해 특정 응용 분야에 맞게 조정할 수 있습니다. 자세한 내용은 Get Started with Instance Segmentation Using Deep Learning 항목과 Get Started with SOLOv2 for Instance Segmentation 항목을 참조하십시오. 클래스에 독립적인 인스턴스 분할을 위해, 이 툴박스는 imsegsam 함수와 segmentAnythingModel 객체를 통해 SAM(Segment Anything Model)을 지원합니다.
훈련 데이터를 준비하기 위해, 이 툴박스는 데이터 세트를 관리하고 구성하는 유틸리티와 함께 데이터 증강 및 전처리 기능을 제공합니다. 자세한 내용은 Postprocess Exported Labels for Instance Segmentation Training 항목을 참조하십시오.
사전 훈련된 모델이나 사용자 지정 모델을 사용하여 예측을 생성한 후에는, 인스턴스 분할 성능을 평가하고 분할 정확도, 객체 수준 정밀도, 그리고 서로 다른 객체 크기별 성능에 대한 상세한 정보를 생성할 수 있습니다. 이러한 메트릭은 마스크 예측과 경계 상자 위치추정의 품질을 평가하는 데 유용합니다. 자세한 내용은 evaluateInstanceSegmentation 항목을 참조하십시오.
이 툴박스는 Pose Mask R-CNN 프레임워크를 통해 인스턴스 분할을 사용한 3차원 객체의 자세 추정도 지원하여, 이를 통해 객체의 방향과 구조에 대한 정밀한 분석을 가능하게 합니다. 자세한 내용은 Perform 6-DoF Pose Estimation for Bin Picking Using Deep Learning 항목을 참조하십시오.

앱
| 영상 레이블 지정기 | 컴퓨터 비전 응용 분야에서 영상에 레이블 지정 |
| 비디오 레이블 지정기 | Label video for computer vision applications |
함수
도움말 항목
시작하기
- Get Started with Instance Segmentation Using Deep Learning
Segment objects using an instance segmentation model such as SOLOv2 or Mask R-CNN. - Get Started with SOLOv2 for Instance Segmentation
Perform multiclass instance segmentation using SOLOv2 and deep learning. - Getting Started with Mask R-CNN for Instance Segmentation
Perform multiclass instance segmentation using Mask R-CNN and deep learning. - Get Started with Segment Anything Model for Image Segmentation
Perform interactive image segmentation using Segment Anything Model 2 (SAM 2) and deep learning.
인스턴스 분할을 위한 Ground Truth 만들기
- Label Objects Using Polygons for Instance Segmentation
Label ground truth objects using polygons for instance segmentation. - Postprocess Exported Labels for Instance Segmentation Training
Postprocess exported ground truth labels and create training datastore for training instance segmentation networks such as SOLOv2 or Mask R-CNN.
인스턴스 분할을 위한 훈련 데이터 준비하기
- Create Instance Segmentation Training Data From Ground Truth
This example shows how to create instance segmentation training data from agroundTruthobject. - Get Started with Image Preprocessing and Augmentation for Deep Learning
Preprocess data for deep learning applications with deterministic operations such as resizing, or augment training data with randomized operations such as random cropping. - Datastores for Deep Learning (Deep Learning Toolbox)
Learn how to use datastores in deep learning applications.
추천 예제
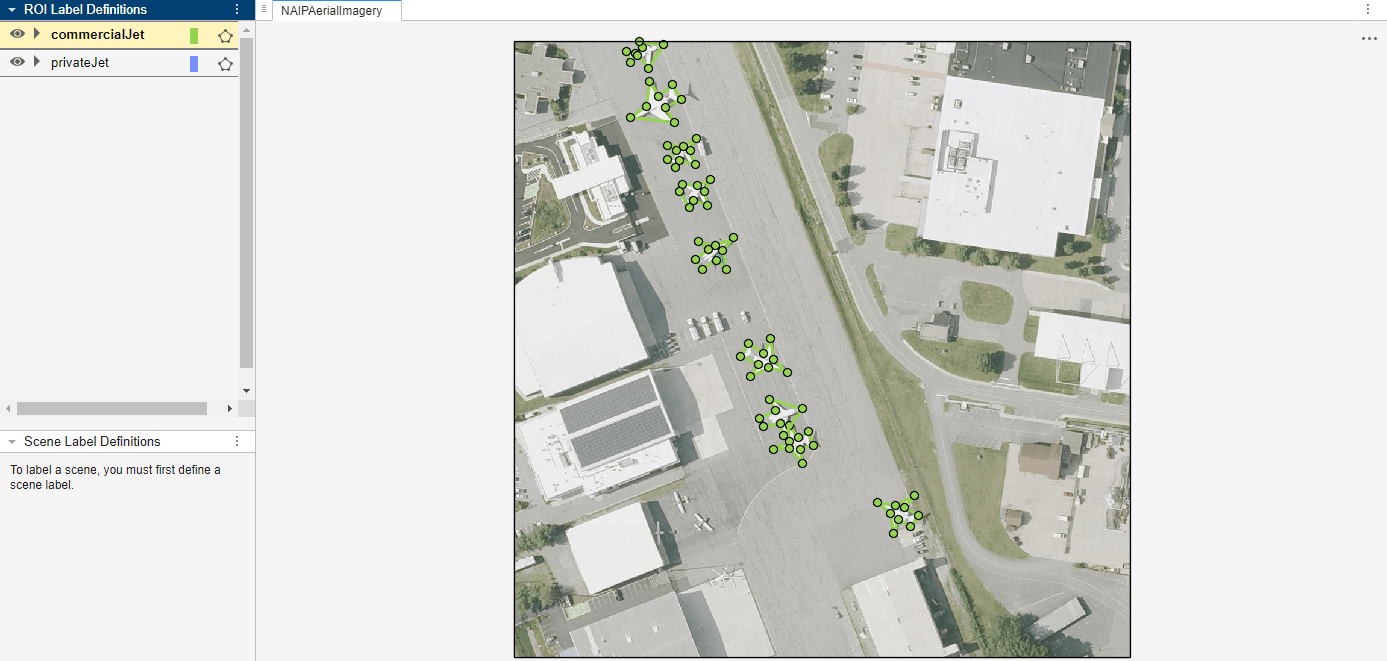
Automate Ground Truth Polygon Labeling Using Grounded SAM Model
Combine Grounding DINO and the Segment Anything Model 2 (SAM 2) to automatically produce polygon labels using the Video Labeler app.

Automate Ground Truth Labeling for Instance Segmentation
Create an automation algorithm to automatically label data for instance segmentation using a pretrained SOLOv2 network in the Video Labeler app.

Automatically Search and Label Video Frames Using VLMs
Automatically search and detect objects based on natural language text queries using vision-language models (VLMs).

Perform Instance Segmentation Using SOLOv2
Segment object instances of randomly rotated machine parts in a bin using a deep learning SOLOv2 network.

Perform Instance Segmentation Using Mask R-CNN
Segment individual instances of people and cars using a multiclass mask region-based convolutional neural network (R-CNN).
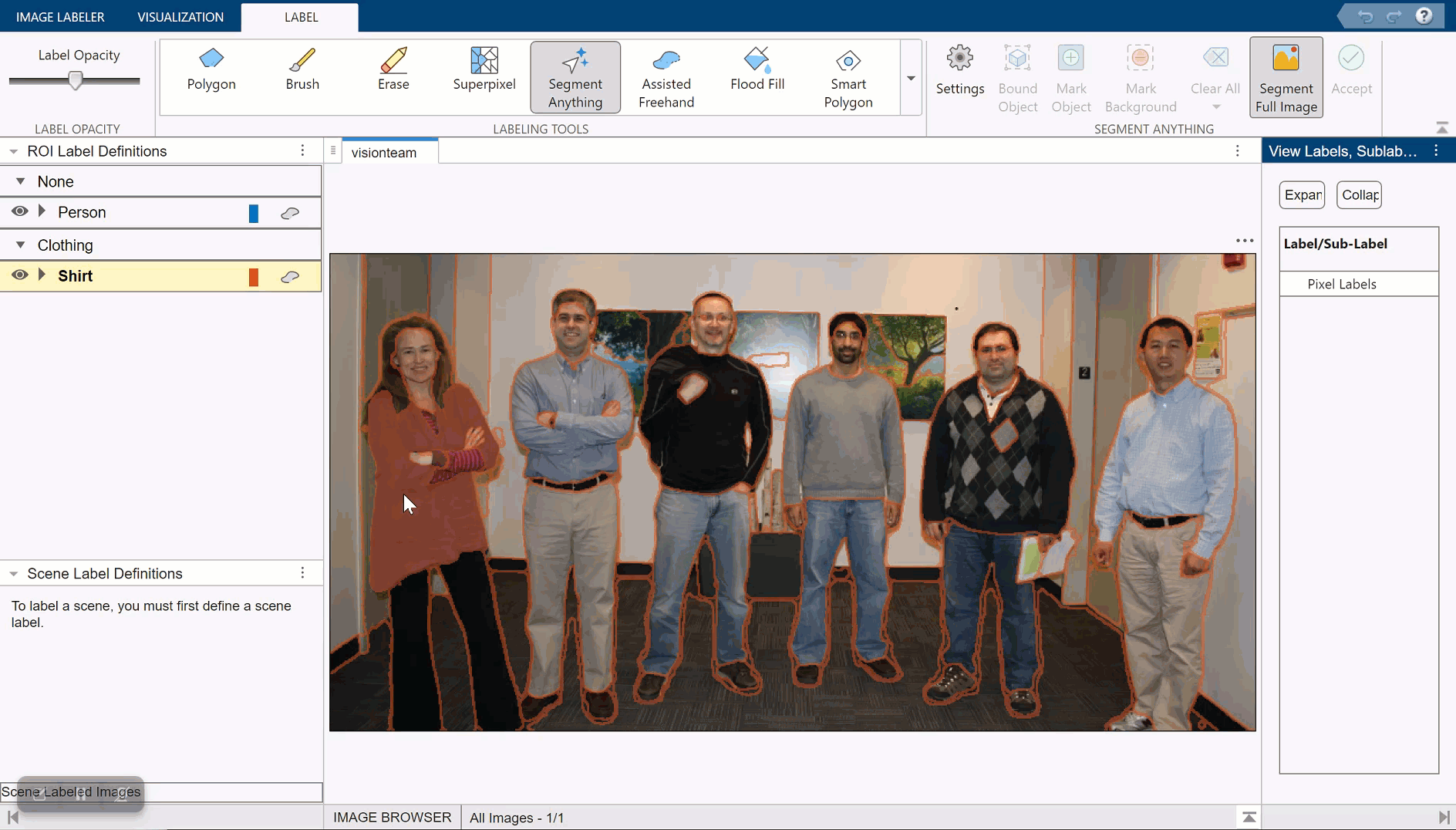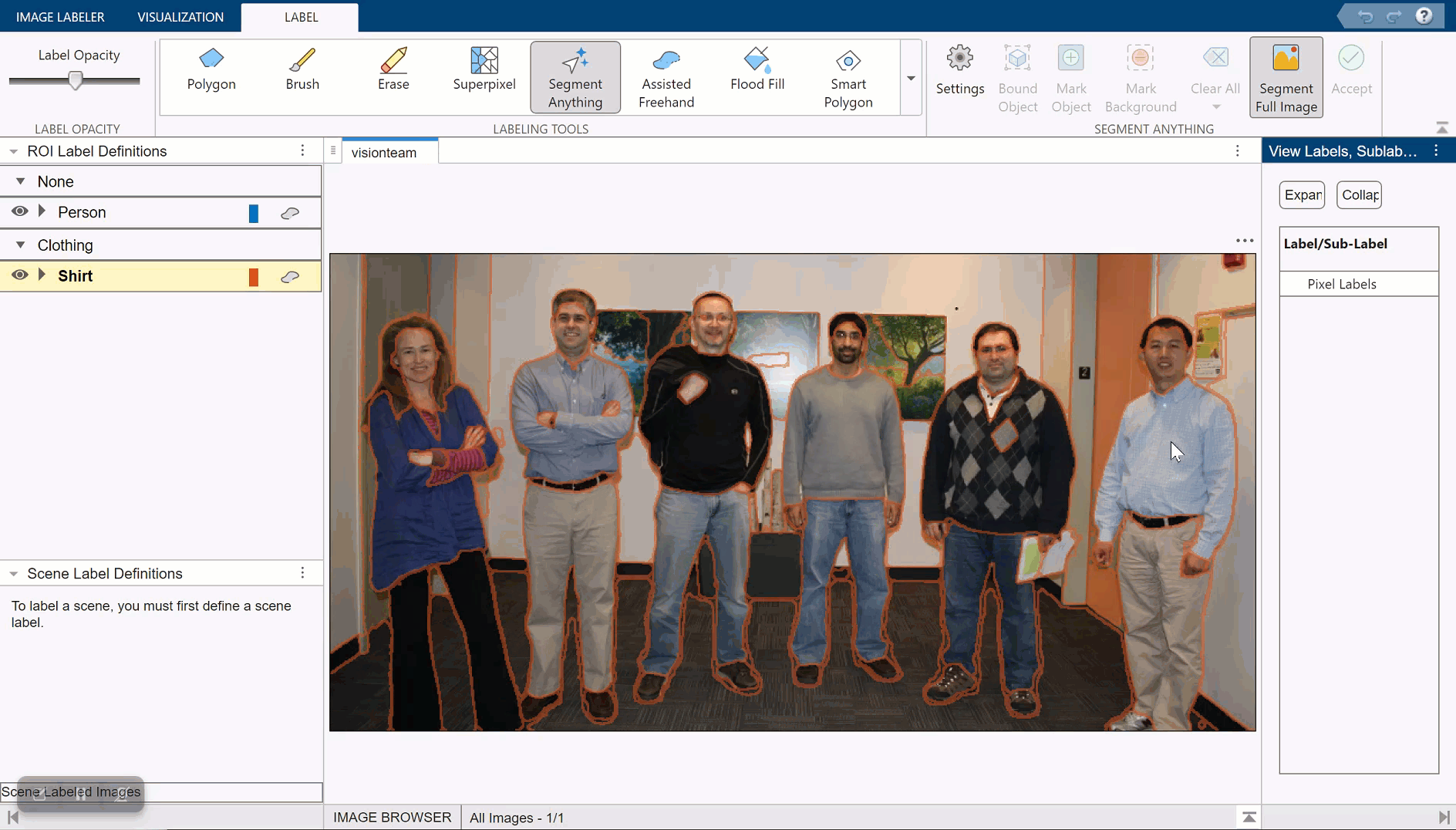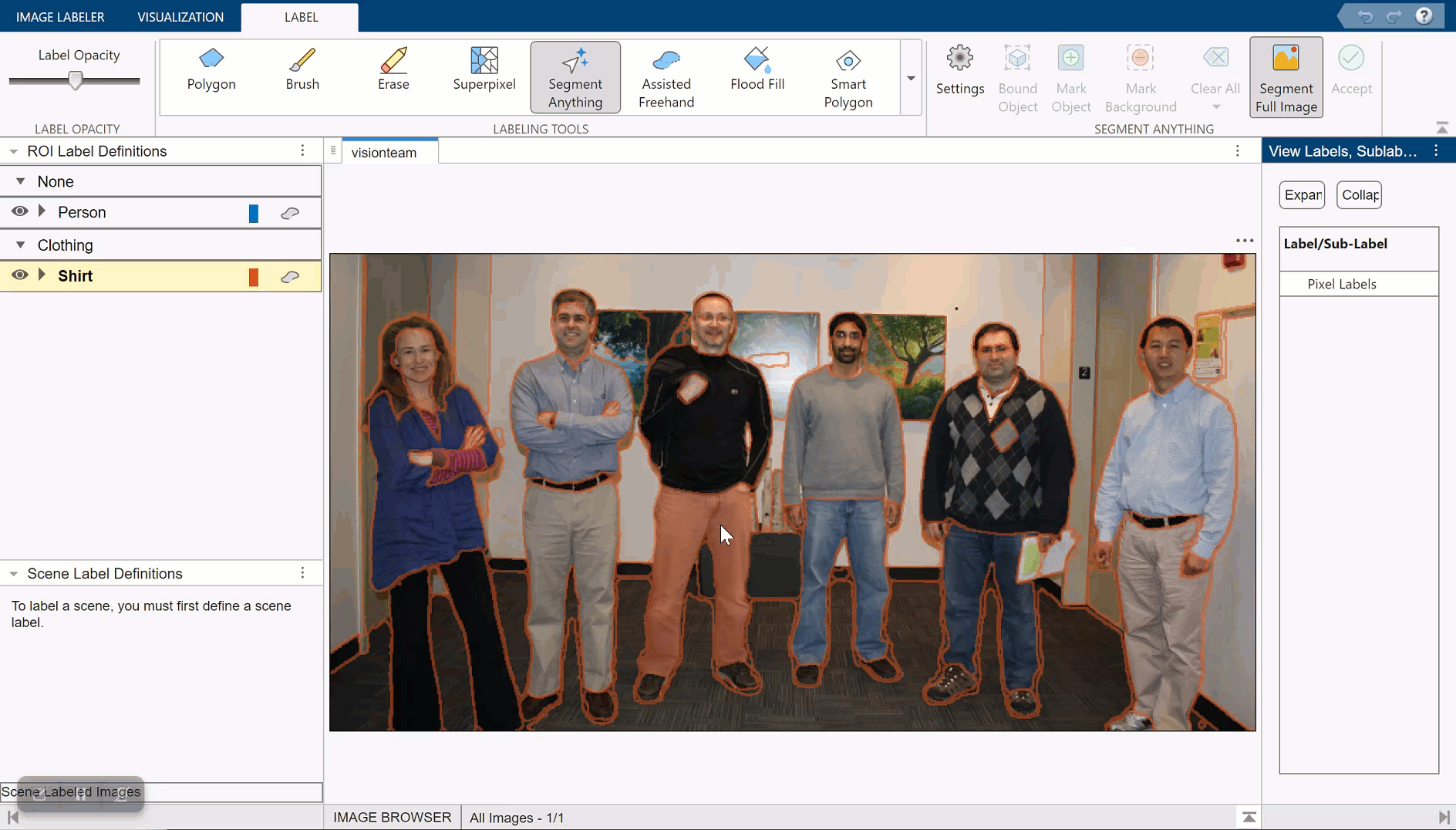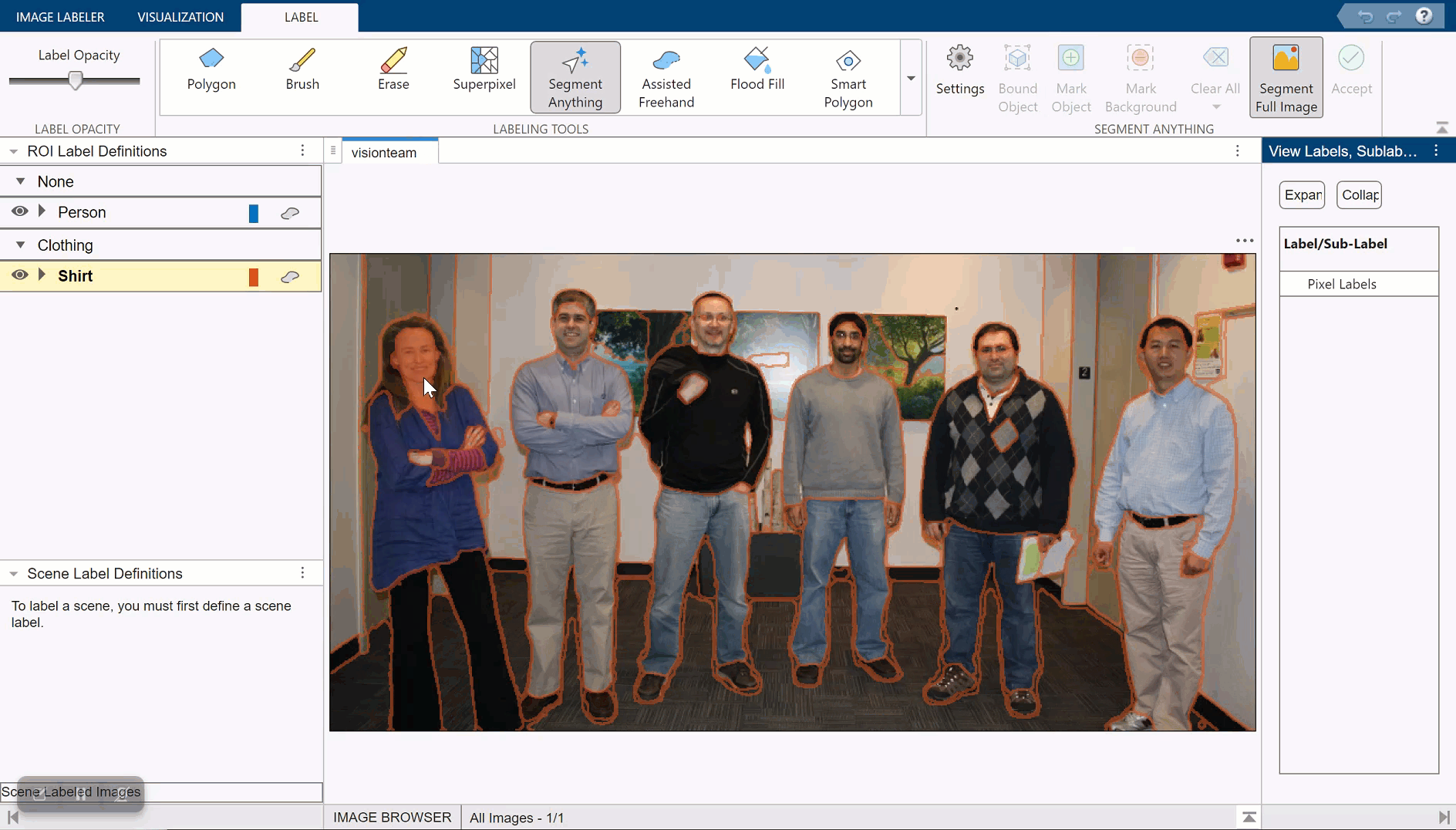
Automatically Label Ground Truth Using Segment Anything Model
Produce pixel labels for semantic segmentation using the Segment Anything Model (SAM) in the 영상 레이블 지정기 app. The SAM is an automatic segmentation technique that you can use to segment object regions to label with just a few clicks, or automatically segment the entire image and instantaneously create labels for selected regions. In this example, you interactively label pixels for semantic segmentation in two ways.

Segment Anything Model을 사용하여 대화형 ROI에서 객체 분할하기
이 예제에서는 SAM(Segment Anything Model)을 사용하여 영상에서 선택한 ROI(관심 영역)에 있는 객체를 대화형 방식으로 분할하는 방법을 보여줍니다.

Perform 6-DoF Pose Estimation for Bin Picking Using Deep Learning
Perform six degrees-of-freedom (6-DoF) pose estimation by estimating the 3-D position and orientation of machine parts in a bin using RGB-D images and a deep learning network.