선형 연립방정식
계산 시 고려 사항
테크니컬 컴퓨팅 부문에서 가장 중요한 문제 중 하나는 선형 연립방정식의 해를 구하는 것입니다.
행렬을 표기할 때 일반적인 문제는 다음과 같은 형태를 취합니다. 두 행렬 A와 b가 주어졌을 때, Ax= b 또는 xA= b를 충족하는 고유한 행렬 x가 존재하는가?
간단히 1×1 행렬을 예로 들어보겠습니다. 예를 들어, 다음 방정식에
7x = 21
유일한 해가 있을까요?
정답은 물론 '예'입니다. 이 방정식에는 x = 3이라는 유일한 해(Unique Solution)가 있습니다. 이 해는 다음과 같이 나눗셈으로 간단히 구할 수 있습니다.
x = 21/7 = 3.
이 해는 7의 역수인 7–1= 0.142857...을 계산한 다음 21에 7–1을 곱하는 방식으로는 보통 구하지 않습니다. 이렇게 하면 더 많은 노력이 들어가는 것은 물론 7–1을 유한한 자릿수로 표현할 경우에는 결과가 정확하지 않을 수도 있습니다. 미지수가 두 개 이상인 선형 방정식도 이와 유사합니다. MATLAB®에서는 행렬의 역행렬을 계산하지 않고도 이러한 방정식을 풀 수 있습니다.
표준 수학 표기법은 아니지만 MATLAB에서는 일반적인 연립방정식의 해를 설명하기 위해 스칼라에서 사용되는 나눗셈 기호를 사용합니다. 나눗셈 기호 슬래시(/)와 백슬래시(\)는 MATLAB 함수 mrdivide와 mldivide에 해당합니다. 이러한 연산자는 미지수 행렬이 계수 행렬의 좌측과 우측 중 어느 쪽에 위치하는지에 따라 적절히 사용됩니다.
| 행렬 방정식 xA = b의 해를 나타내며, |
| 행렬 방정식 Ax = b의 해를 나타내며, |
방정식 Ax = b 또는 xA = b의 양변을 모두 A로 "나누는" 상황을 고려해 보겠습니다. 계수 행렬 A는 항상 “분모”입니다.
x = A\b의 차원 호환성 조건을 충족하려면 두 행렬 A와 b의 행 개수가 동일해야 합니다. 그러면 해 x의 열 개수가 b의 열 개수와 같아지고 해당 행 차원은 A의 행 차원과 같게 됩니다. x = b/A의 경우에는 행의 역할과 열의 역할이 서로 바뀝니다.
실제로, Ax = b 형식의 선형 방정식이 xA = b 형식의 선형 방정식보다 자주 나타납니다. 따라서, 백슬래시가 슬래시보다 훨씬 자주 사용됩니다. 이 섹션의 나머지 부분에서는 백슬래시 연산자에 대해 중점적으로 다루고 있습니다. 이에 대응하는 슬래시 연산자의 속성은 다음 항등식에서 추론할 수 있습니다.
(b/A)' = (A'\b').
계수 행렬 A는 정사각 행렬일 필요가 없습니다. A의 크기가 m×n이면 다음과 같은 세 가지 경우로 나눌 수 있습니다.
m = n | 정사각 시스템. 엄밀해(Exact Solution)를 구합니다. |
m > n | 미지수보다 방정식의 개수가 더 많은 과결정 시스템. 최소제곱해(Least-squares Solution)를 구합니다. |
m < n | 미지수보다 방정식의 개수가 더 적은 부족 결정 시스템. 최대 m개의 0이 아닌 성분으로 기저해(Basic Solution)를 구합니다. |
mldivide 알고리즘
mldivide 연산자는 다양한 솔버를 바탕으로 각기 다른 유형의 계수 행렬을 다룹니다. 계수 행렬을 검토하는 방식으로 다양한 경우를 자동으로 진단합니다. 자세한 내용은 mldivide 도움말 페이지의 "알고리즘" 섹션을 참조하십시오.
일반해(General Solution)
선형 연립방정식 Ax = b의 일반해는 구할 수 있는 모든 해를 나타냅니다. 일반해를 구하는 방법은 다음과 같습니다.
대응하는 동차 시스템 Ax = 0을 풉니다.
null명령을 사용하는데null(A)를 입력하여 푸십시오. 그러면 해 공간의 기저가 Ax = 0에 반환됩니다. 모든 해는 기저 벡터의 선형 결합이 됩니다.비동차 시스템 Ax = b의 특수해를 구합니다.
그러면 Ax= b의 모든 해는 위의 2단계에서 구한 Ax =b의 특수해의 합과 1단계에서 구한 기저 벡터의 선형 결합을 더하여 표현할 수 있습니다.
이 섹션의 나머지 부분에서는 MATLAB을 사용하여 2단계에 나와 있는 대로 Ax = b의 특수해를 구하는 방법에 대해 설명합니다.
정사각 시스템
가장 일반적인 상황에서는 정사각 계수 행렬 A와 단일 우변 열 벡터 b를 사용해야 합니다.
정칙 계수 행렬
행렬 A가 정칙 행렬이면 해 x = A\b는 b의 크기와 같아집니다. 예를 들면 다음과 같습니다.
A = pascal(3);
u = [3; 1; 4];
x = A\u
x =
10
-12
5A*x가 u와 정확히 같은지 확인하여 검증해 볼 수 있습니다.
A와 b가 크기가 같은 정사각 행렬인 경우 x= A\b도 같은 크기를 갖게 됩니다.
b = magic(3);
X = A\b
X =
19 -3 -1
-17 4 13
6 0 -6A*x가 b와 정확히 같은지 확인하여 검증해 볼 수 있습니다.
위의 두 예제에서는 모두 정수로 엄밀해(Exact Solution)를 얻게 됩니다. 이는 계수 행렬을 완전 랭크 행렬(정칙 행렬)인 pascal(3)이 되도록 선택했기 때문입니다.
특이 계수 행렬
정사각 행렬 A에 선형 독립 열이 없다면 특이 행렬로 간주됩니다. A가 특이 행렬인 경우에는, Ax = b에 해가 존재하지 않거나 유일한 해가 존재하지 않게 됩니다. 백슬래시 연산자 A\b는 A가 특이 행렬에 가깝거나 완전한 특이점을 감지하면 경고를 발생시킵니다.
A가 특이 행렬이고 Ax = b에 해가 있는 경우 다음을 입력하여 유일하지 않은 특수해를 구할 수 있습니다.
P = pinv(A)*b
pinv(A)는 A의 의사 역행렬입니다. Ax = b에 엄밀해가 없는 경우 pinv(A)는 최소제곱해를 반환합니다.
예를 들면 다음과 같습니다.
A = [ 1 3 7
-1 4 4
1 10 18 ]위의 행렬은 특이 행렬이며 다음을 입력하여 검증할 수 있습니다.
rank(A)
ans =
2A가 완전 랭크 행렬이 아니므로 일부 특이값의 경우 값이 0입니다.
엄밀해. b =[5;2;12]의 경우 방정식 Ax = b의 엄밀해는 다음과 같이 구할 수 있습니다.
pinv(A)*b
ans =
0.3850
-0.1103
0.7066다음을 입력하여 pinv(A)*b가 엄밀해인지 검증합니다.
A*pinv(A)*b
ans =
5.0000
2.0000
12.0000최소제곱해. 반면 b = [3;6;0]이면 Ax = b에는 엄밀해가 없습니다. 이 경우 pinv(A)*b는 최소제곱해를 반환합니다. 다음을 입력하는 경우
A*pinv(A)*b
ans =
-1.0000
4.0000
2.0000원래 벡터 b를 다시 얻지 못합니다.
첨가 행렬 [A b]의 기약행 사다리꼴을 구하여 Ax = b에 엄밀해가 있는지 여부를 확인할 수 있습니다. 이 예제에서 이를 확인하려면 다음과 같이 입력합니다.
rref([A b])
ans =
1.0000 0 2.2857 0
0 1.0000 1.5714 0
0 0 0 1.0000맨 아래 행에는 마지막 성분을 제외하고 모두 0만 있기 때문에 방정식에 해가 없습니다. 이 경우 pinv(A)는 최소제곱해를 반환합니다.
과결정 시스템
이 예제에서는 실험 데이터에 대한 다양한 유형의 곡선 피팅에서 어떻게 과결정 시스템이 자주 발견되는지를 보여줍니다.
시간 t의 여러 다른 값에서 수량 y를 측정하여 다음과 같은 관측값을 생성합니다. 다음 명령문을 사용하면 데이터를 입력한 후 테이블 형식으로 볼 수 있습니다.
t = [0 .3 .8 1.1 1.6 2.3]'; y = [.82 .72 .63 .60 .55 .50]'; B = table(t,y)
B=6×2 table
t y
___ ____
0 0.82
0.3 0.72
0.8 0.63
1.1 0.6
1.6 0.55
2.3 0.5
다음 감쇠 지수 함수(Decaying Exponential Function)를 사용하여 데이터를 모델링해 보겠습니다.
.
위 방정식은 두 개의 다른 벡터의 선형 결합을 통해 벡터 y의 근삿값을 구해야 함을 의미합니다. 두 벡터 중 하나는 모두 1로만 구성된 상수 벡터이고 다른 하나는 성분 exp(-t)를 갖는 벡터입니다. 미정 계수 과 는 모델과 데이터의 편차제곱합을 최소화하는 최소제곱 피팅을 수행하여 구할 수 있습니다. 2개의 미지수에 대한 6개의 방정식이 있으며, 다음과 같이 6×2 행렬로 표현됩니다.
E = [ones(size(t)) exp(-t)]
E = 6×2
1.0000 1.0000
1.0000 0.7408
1.0000 0.4493
1.0000 0.3329
1.0000 0.2019
1.0000 0.1003
백슬래시 연산자를 사용하여 최소제곱해(Least-squares Solution)를 구합니다.
c = E\y
c = 2×1
0.4760
0.3413
즉, 이 데이터에 대한 최소제곱 피팅은 다음과 같습니다.
다음 명령문은 t를 균일한 간격으로 증가시키며 모델을 평가한 다음 원래 데이터와 함께 결과를 플로팅합니다.
T = (0:0.1:2.5)'; Y = [ones(size(T)) exp(-T)]*c; plot(T,Y,'-',t,y,'o')
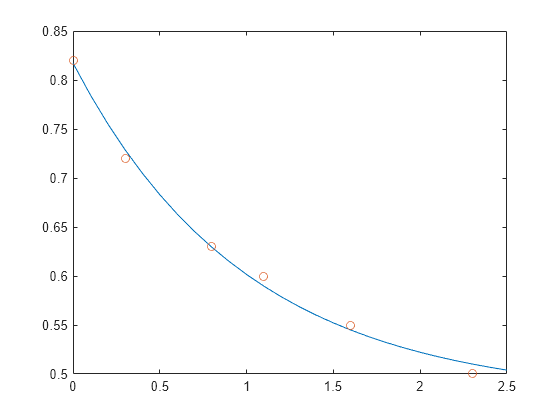
E*c는 y와 정확히 같지는 않지만, 그 차이는 원래 데이터의 계측 오차보다 작을 것입니다.
사각 행렬 A가 선형 독립 열을 갖지 않으면 랭크 부족이 됩니다. A의 랭크가 부족하면 AX = B의 최소제곱해는 유일한 해가 아닙니다. A\B는 A의 랭크가 부족한 경우 경고를 발생시키고, 최소제곱해를 구합니다. lsqminnorm을 사용하면 모든 해 중에서 최소 노름을 갖는 해 X를 구할 수 있습니다.
부족 결정 시스템
이 예제에서는 부족 결정 시스템에 대한 해가 유일한 해가 아님을 보여줍니다. 부족 결정 선형 시스템에는 방정식보다 미지수가 더 많습니다. MATLAB에서 행렬 왼쪽 나눗셈 연산은 m×n 계수 행렬에 대해 최대 m개의 0이 아닌 성분을 갖는 기저 최소제곱해를 구합니다.
다음은 임의의 간단한 한 예입니다.
R = [6 8 7 3; 3 5 4 1] rng(0); b = randi(8,2,1)
R =
6 8 7 3
3 5 4 1
b =
7
8 선형 시스템 Rp = b는 미지수가 네 개인 방정식 두 개인 경우가 됩니다. 계수 행렬에 작은 정수가 포함되어 있으므로 format 명령을 사용하여 유리수 형식으로 해를 표시하는 것이 좋습니다. 특수해는 다음과 같이 구합니다.
format rat
p = R\b
p =
0
17/7
0
-29/7 0이 아닌 성분 중 하나가 p(2)인데, 이는 R(:,2)가 가장 큰 노름을 가지는 R의 열이기 때문입니다. 다른 0이 아닌 성분은 p(4)인데, 이는 R(:,2)가 소거된 후 R(:,4)가 우위를 차지하기 때문입니다.
부족 결정 시스템에 대한 전체 일반해는 영공간 벡터(Null Space Vector)의 임의의 선형 결합에 p를 더하는 것으로 특징지어질 수 있습니다. 영공간 벡터의 임의의 선형 결합은 유리 기저를 요청하는 옵션과 함께 null 함수를 사용하여 확인할 수 있습니다.
Z = null(R,'r')
Z =
-1/2 -7/6
-1/2 1/2
1 0
0 1 R*Z는 0이며 다음과 같은 임의의 벡터 x에 대해 잔차 R*x - b가 작음을 확인할 수 있습니다.
x = p + Z*q
Z의 열은 영공간 벡터이므로 곱 Z*q는 이러한 벡터의 선형 결합이 됩니다.
설명을 위해 임의의 q를 선택하고 x를 생성해 보겠습니다.
q = [-2; 1]; x = p + Z*q;
그다음 잔차에 대한 노름을 계산합니다.
format short
norm(R*x - b)ans = 2.6645e-15
무한개의 많은 해가 있으면 최소 노름을 갖는 해에 특히 관심을 가질 수 있습니다. lsqminnorm을 사용하면 최소 노름을 갖는 최소제곱해를 구할 수 있습니다. 이 해는 norm(p)의 값이 가장 작습니다.
p = lsqminnorm(R,b)
p =
-207/137
365/137
79/137
-424/137 여러 개의 우변에 대한 해 구하기
계수 행렬 A가 동일하지만 우변 b가 각기 다른 선형 시스템들을 푸는 문제가 있을 수 있습니다. 각기 다른 b 값을 한 번에 알 수 있다면, b를 여러 개의 열을 갖는 행렬로 만든 다음 단일 백슬래시 명령 X = A\[b1 b2 b3 …]을 사용하여 모든 연립방정식을 동시에 풀 수 있습니다.
그러나 각기 다른 b 값을 한 번에 모두 알 수 없을 수도 있습니다. 이 경우에는 여러 개의 연립방정식을 연속해서 풀어야 합니다. 슬래시(/)나 백슬래시(\)를 사용하여 이러한 연립방정식 중 하나를 풀 경우, 이 두 슬래시 연산자는 계수 행렬 A를 분해한 다음 행렬 분해를 사용하여 해를 구합니다. 그러나, 이어지는 다른 b를 갖는 유사한 연립방정식을 풀 때마다 연산자는 A에 대해 동일한 분해를 수행합니다. 즉, 중복된 계산이 수행됩니다.
이러한 비효율성을 방지하려면 A에 대한 분해를 미리 수행한 다음 해당 인수를 재사용하여 각기 다른 b에 대해 해를 구해야 합니다. 그러나 실제로는 이 방식으로 분해를 미리 계산하는 것이 어려울 수 있습니다. 어떤 분해를 계산할지(LU, LDL, 촐레스키 등)뿐 아니라 문제를 풀기 위해 인수를 어떤 식으로 곱해야 할지도 알아야 하기 때문입니다. 예를 들어, LU 분해의 경우 원래 시스템 Ax = b를 풀려면 다음 두 개의 선형 시스템을 풀어야 합니다.
[L,U] = lu(A); x = U \ (L \ b);
이 대신, 여러 개의 연속된 우변을 갖는 선형 시스템을 푸는 데는 decomposition 객체를 사용하는 방법이 권장됩니다. 이 객체를 사용하면 행렬 분해를 미리 계산하는 성능상의 이점을 누릴 수 있으며, 행렬 인수를 어떻게 사용할지에 대해서는 몰라도 관계없습니다. 앞에 나온 LU 분해는 다음과 같이 바꿀 수 있습니다.
dA = decomposition(A,'lu');
x = dA\b;어떤 분해를 사용해야 할지 잘 모르겠는 경우, decomposition(A)는 백슬래시가 하는 것과 유사하게 A의 속성에 따라 올바른 유형을 선택합니다.
다음은 이 방법을 사용할 때 얻을 수 있는 성능상의 이점을 보여주는 간단한 테스트입니다. 이 테스트에서는 백슬래시(\)와 decomposition을 둘 다 사용하여 동일한 희소 선형 시스템을 100번씩 풉니다.
n = 1e3; A = sprand(n,n,0.2) + speye(n); b = ones(n,1); % Backslash solution tic for k = 1:100 x = A\b; end toc
Elapsed time is 9.006156 seconds.
% decomposition solution tic dA = decomposition(A); for k = 1:100 x = dA\b; end toc
Elapsed time is 0.374347 seconds.
이 문제에서는 decomposition을 사용한 풀이가 백슬래시만 사용한 것보다 훨씬 더 빠르며, 구문도 여전히 간단합니다.
반복법
계수 행렬 A가 큰 희소 행렬인 경우 일반적으로 행렬 분해 방법을 사용하는 것은 효율적이지 않습니다. 반복법은 일련의 근사해를 생성합니다. MATLAB에서는 큰 희소 입력 행렬을 다룰 수 있는 여러 가지 반복법을 제공합니다.
| 함수 | 설명 |
|---|---|
pcg | 선조건 적용 켤레 기울기법(Preconditioned Conjugate Gradients Method). 이 방법은 양의 정부호 계수 에르미트 행렬 A에 적합합니다. |
bicg | 쌍켤레 기울기법(BiConjugate Gradients Method) |
bicgstab | 쌍켤레 기울기 안정법(BiConjugate Gradients Stabilized Method) |
bicgstabl | BiCGStab(l) 계산법(BiCGStab(l) Method) |
cgs | 켤레 기울기 제곱법(Conjugate Gradients Squared Method) |
gmres | 일반화된 최소 잔차법(Generalized Minimum Residual Method) |
lsqr | LSQR 계산법(LSQR Method) |
minres | 최소 잔차법(Minimum Residual Method). 이 방법은 에르미트 계수 행렬 A에 적합합니다. |
qmr | 준최소 잔차법(Quasi-Minimal Residual Method) |
symmlq | 대칭 LQ 계산법(Symmetric LQ Method) |
tfqmr | 비전치 QMR 계산법(Transpose-Free QMR Method) |
멀티스레드 계산
MATLAB에서는 다수의 선형 대수 함수와 요소별 숫자형 함수의 멀티스레드 계산을 지원합니다. 이 함수들은 여러 스레드에서 자동으로 실행됩니다. 여러 개의 CPU를 기반으로 보다 빠른 속도로 실행해야 하는 함수 또는 표현식의 경우 다음과 같은 다양한 조건을 충족해야 합니다.
함수가 동시에 실행 가능한 여러 부분으로 쉽게 분할할 수 있는 연산을 수행해야 합니다. 이 부분들은 프로세스 간에 거의 교신이 이루어지지 않는 상태로 실행될 수 있어야 하며, 순차적 연산이 거의 필요하지 않아야 합니다.
데이터를 나누고 개별 실행 스레드를 관리하는 데 소요되는 시간보다 동시 실행으로 얻게 되는 이점이 더 클 정도로 데이터 크기가 충분히 커야 합니다. 예를 들어, 대부분의 함수는 배열에 수천 개 이상의 요소가 포함되어 있는 경우에만 실행 속도가 빨라집니다.
연산이 메모리에 바인딩되지 않아야 합니다. 처리 시간에서 메모리 액세스 시간이 많은 비중을 차지해서는 안 되기 때문입니다. 일반적으로 단순한 함수보다 복잡한 함수의 경우에 더 높은 속도 향상이 이루어집니다.
inv, lscov, linsolve, mldivide는 멀티스레드 계산을 사용할 경우 대규모 배정밀도 배열에 대해 현저히 향상된 속도를 보여줍니다.
참고 항목
mldivide | mrdivide | pinv | decomposition | lsqminnorm