특이값
사각 행렬 A의 특이값은 다음을 충족하는 스칼라 σ이고, 특이 벡터는 다음을 충족하는 벡터 쌍 u와 v입니다.
여기서 는 A의 에르미트(Hermitian) 전치 행렬입니다. 특이 벡터 u와 v는 일반적으로 1의 노름(Norm) 값을 갖도록 스케일링됩니다. 또한, u와 v가 A의 특이 벡터이면 -u와 -v도 A의 특이 벡터입니다.
특이값 σ는 A가 복소수이더라도 항상 음이 아닌 실수입니다. 대각 행렬 Σ에 특이값이 있고 이에 대응하는 특이 벡터가 두 직교 행렬 U와 V의 열을 구성하여 다음 방정식을 얻게 됩니다.
U와 V는 유니타리 행렬이므로 첫 번째 방정식에 오른쪽으로 를 곱하면 다음과 같은 특이값 분해 방정식이 생성됩니다.
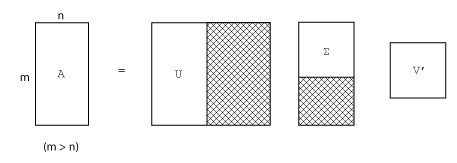
m×n 행렬의 전체 특이값 분해를 수행하려면 다음이 필요합니다.
m×m 행렬 U
m×n 행렬 Σ
n×n 행렬 V
즉, U와 V가 모두 정사각 행렬이고 Σ의 크기는 A의 크기와 동일합니다. A에 열 개수보다 행 개수가 훨씬 많은 경우(m > n) 그 결과로 생성되는 m×m 행렬 U가 매우 커집니다. 그러나 Σ에서 U에 있는 열의 대부분은 0으로 곱해집니다. 이러한 상황에서 효율적인 크기로 분해를 수행하면 m×n U, n×n Σ, 동일한 V가 생성되어 시간과 저장 용량이 모두 절감됩니다.
상미분 방정식의 경우처럼, 한 벡터 공간에서 매핑할 경우에는 고유값 분해가 행렬 분석에 적합합니다. 하지만 가령 차원이 다른 경우처럼 한 벡터 공간에서 다른 벡터 공간으로의 매핑을 분석하는 데는 특이값 분해가 적합합니다. 대부분의 선형 연립방정식은 두 번째 범주에 해당됩니다.
A가 양의 정부호 정사각 대칭 행렬인 경우, A의 고유값 분해와 특이값 분해는 같습니다. 하지만 A가 대칭성과 양의 정부호 특성에서 벗어난다면 두 분해 간의 차이는 증가합니다. 특히, 실수 행렬의 특이값 분해를 수행하면 결과로 항상 실수 행렬을 얻게 되지만 실수 비대칭 행렬의 고유값 분해를 수행하면 결과로 복소수 행렬을 얻게 될 수 있습니다.
예제 행렬의 경우
A = [9 4
6 8
2 7];전체 특이값 분해는 다음과 같습니다.
[U,S,V] = svd(A)
U =
-0.6105 0.7174 0.3355
-0.6646 -0.2336 -0.7098
-0.4308 -0.6563 0.6194
S =
14.9359 0
0 5.1883
0 0
V =
-0.6925 0.7214
-0.7214 -0.6925여기서 U*S*V'가 A와 반올림 오차 범위 내에서 같음을 확인할 수 있습니다. 이 작은 문제의 경우 효율적인 크기로 분해를 수행하면 결과값이 약간 더 작아질 뿐입니다.
[U,S,V] = svd(A,"econ")
U =
-0.6105 0.7174
-0.6646 -0.2336
-0.4308 -0.6563
S =
14.9359 0
0 5.1883
V =
-0.6925 0.7214
-0.7214 -0.6925여기서도 U*S*V'는 A와 반올림 오차 범위 내에서 같음을 확인할 수 있습니다.
일괄 처리되는 SVD 계산
같은 크기를 가진 대량의 행렬 모음을 분해해야 할 경우 루프 내에서 svd를 사용하여 모든 분해를 수행하는 것은 비효율적입니다. 대신에, 모든 행렬을 다차원 배열로 결합하고, pagesvd를 사용하여 단일 함수 호출로 모든 배열 페이지에서 특이값 분해를 수행합니다.
| 함수 | 사용법 |
|---|---|
pagesvd | pagesvd를 사용하여 다차원 배열의 페이지에서 특이값 분해를 수행합니다. 이는 모두 같은 크기를 가진 대량의 행렬 모음에서 SVD를 수행하는 경우에 효율적인 방법입니다. |
예를 들어 세 개의 2×2 행렬 모음이 있다고 가정합니다. cat 함수를 사용하여 행렬을 2×2×3 배열로 결합합니다.
A = [0 -1; 1 0]; B = [-1 0; 0 -1]; C = [0 1; -1 0]; X = cat(3,A,B,C);
이제 pagesvd를 사용하여 세 개 분해를 동시에 수행합니다.
[U,S,V] = pagesvd(X);
X의 페이지마다 출력값 U, S, V에 해당 페이지가 있습니다. 예를 들어 행렬 A가 X의 첫 번째 페이지에 있다고 가정할 경우, 해당 분해는 U(:,:,1)*S(:,:,1)*V(:,:,1)'로 지정됩니다.
낮은 랭크 SVD 근사
큰 희소 행렬의 경우 svd를 사용하여 모든 특이값과 특이 벡터를 계산하는 것이 항상 실용적이지만은 않습니다. 예를 들어, 가장 큰 특이값 몇 개만 구하면 되는 상황에서 5000×5000 희소 행렬의 특이값을 모두 계산하는 것은 부담이 됩니다.
특이값과 특이 벡터가 몇 개 정도만 필요한 경우에는 svd 함수보다 svds 및 svdsketch 함수를 사용하는 것이 좋습니다.
| 함수 | 사용법 |
|---|---|
svds | svds를 사용하여 SVD의 랭크-k 근사를 계산합니다. 특이값의 서브셋이 가장 큰 값이어야 하는지, 가장 작은 값이어야 하는지 또는 특정 수에 가장 가까운 값이어야 하는지를 지정할 수 있습니다. svds는 일반적으로 최적의 랭크-k 근사를 계산합니다. |
svdsketch | svdsketch를 사용하여 지정된 허용오차를 충족하는 입력 행렬의 부분적 SVD를 계산합니다. svds에서는 사용자가 랭크를 지정해야 하는 반면, svdsketch는 지정된 허용오차를 기반으로 하여 행렬 스케치의 랭크를 적절하게 결정합니다. svdsketch가 최종적으로 사용하는 랭크-k 근사는 허용오차를 충족하지만, svds와 달리 최적의 근사라는 보장은 없습니다. |
예를 들어, 밀도가 30% 정도인 희소 형식의 1000×1000 확률 행렬이 있다고 가정하겠습니다.
n = 1000; A = sprand(n,n,0.3);
가장 큰 특이값 6개는 다음과 같이 구합니다.
S = svds(A) S = 130.2184 16.4358 16.4119 16.3688 16.3242 16.2838
또한, 가장 작은 특이값 6개는 다음과 같이 구합니다.
S = svds(A,6,"smallest")
S =
0.0740
0.0574
0.0388
0.0282
0.0131
0.0066비희소 행렬 full(A)로서 메모리에 다 들어갈 수 있는 더 작은 행렬의 경우, svds나 svdsketch보다는 svd(full(A))를 사용하는 것이 더 빠를 수도 있습니다. 그러나, 정말 큰 희소 행렬의 경우에는 반드시 svds 또는 svdsketch를 사용해야 합니다.
참고 항목
svd | svds | svdsketch | gsvd | pagesvd