모수적 피팅
라이브러리 모델을 사용한 모수적 피팅
모수적 피팅에서는 데이터에 피팅하는 하나 이상의 모델에 대한 계수(파라미터)를 찾는 작업이 수행됩니다. 데이터는 통계적 성질을 갖는다고 간주되며, 다음과 같은 2개의 성분으로 나뉩니다.
데이터 = 결정적 성분 + 확률적 성분
결정적 성분은 모수적 모델로 지정되고, 확률적 성분은 종종 데이터와 연관된 오차로 설명됩니다.
데이터 = 모수적 모델 + 오차
모델은 독립 변수(예측 변수)와 하나 이상의 계수에 대한 함수입니다. 오차는 특정 확률 분포(보통 가우스 분포)를 따르는 데이터의 임의 변동을 나타냅니다. 이런 변동은 여러 요인에서 기인할 수 있지만, 측정된 데이터를 취급할 때는 항상 어느 정도 존재합니다. 체계적 변동도 존재할 수 있지만, 이는 데이터를 제대로 표현하지 못하는 피팅 모델을 야기할 수 있습니다.
모델 계수는 물리적 유의성을 갖는 경우가 많습니다. 예를 들어, 방사성 핵종의 단일 붕괴 방식에 해당하는 데이터를 수집하여 붕괴의 반감기(T1/2)를 추정하려 한다고 가정하겠습니다. 방사성 붕괴 법칙에서는 방사성 물질의 활동이 시간의 흐름에 따라 지수적으로 붕괴한다고 설명합니다. 따라서 피팅에 사용할 모델은 다음과 같이 지정됩니다.
여기서 y0은 시간 t = 0에서의 핵의 개수고 λ는 붕괴 상수입니다. 데이터는 다음 방정식으로 설명할 수 있습니다.
y0과 λ는 모두 피팅에 의해 추정되는 계수입니다. T1/2 = ln(2)/λ이므로 붕괴 상수의 피팅된 값은 피팅된 반감기를 산출합니다. 그러나 데이터에 일부 오차가 포함되어 있으므로 데이터로부터 정확하게 방정식의 결정적 성분을 파악할 수는 없습니다. 따라서 계수 및 반감기 계산에는 어느 정도의 불확실성이 수반됩니다. 불확실성이 허용 가능한 수준이라면 여기서 데이터 피팅이 완료됩니다. 불확실성이 허용 가능하지 않은 수준이라면 더 많은 데이터를 수집하거나 측정 오차를 줄이고 새로운 데이터를 수집한 후 모델 피팅을 반복하는 등 불확실성을 낮추는 과정을 수행해야 할 수 있습니다.
모델을 관장하는 이론이 없는 여타 문제에서는 항을 추가하거나 제거하여 모델을 수정하거나 완전히 다른 모델로 대체해 볼 수도 있습니다.
Curve Fitting Toolbox™의 모수적 라이브러리 모델은 다음 섹션에 설명되어 있습니다.
모델 유형 선택하기
대화형 방식으로 모델 유형 선택하기
MATLAB® 명령줄에 curveFitter를 입력하여 곡선 피팅기 앱을 엽니다. 또는 앱 탭의 수학, 통계학 및 최적화 그룹에서 곡선 피팅기를 클릭합니다.
곡선 피팅기 앱에서 곡선 피팅기 탭의 피팅 유형 섹션으로 이동합니다. 피팅 갤러리에서 모델 유형을 선택할 수 있습니다. 화살표를 클릭하여 갤러리를 엽니다.

다음 표에서는 곡선과 곡면에 대해 피팅할 수 있는 모델을 설명합니다.
| 피팅 그룹 | 피팅 유형 | 곡선 | 곡면 |
|---|---|---|---|
| 회귀 모델 | 다항식 | 가능(최대 9차) | 가능(최대 5차) |
| 지수 | 가능 | 불가 | |
| 로그 | 가능 | 불가 | |
| 푸리에 | 가능 | 불가 | |
| 가우스 | 가능 | 불가 | |
| 멱급수 | 가능 | 불가 | |
| 유리 | 가능 | 불가 | |
| 사인 합 | 가능 | 불가 | |
| 베이불 | 가능 | 불가 | |
| 시그모이드 | 가능 | 불가 | |
| 보간 | 보간 | 다음 방법을 사용할 경우 가능
| 다음 방법을 사용할 경우 가능
|
| 평활화 | 평활화 스플라인 | 가능 | 불가 |
| Lowess | 불가 | 가능 | |
| 사용자 지정 | 사용자 지정 수식 | 가능 | 가능 |
| 사용자 지정 선형 모델 피팅하기 | 가능 | 불가 |
결과 창에 모델 사양, 계수 값, 적합도 통계량이 표시됩니다.
팁
피팅에 문제가 있을 경우 결과 창의 메시지를 참고하여 더 나은 설정을 찾아낼 수 있습니다.
곡선 피팅기 앱은 피팅 옵션 창에 피팅을 개선하기 위해 변경할 수 있는 일련의 피팅 유형 및 설정을 제공합니다. 먼저 디폴트 값을 사용해 본 다음 다른 설정으로 시험해 보십시오. 사용 가능한 피팅 옵션을 사용하는 방법에 대한 자세한 내용은 계수 제약 조건: 한계 및 최적화된 시작점 지정하기 항목을 참조하십시오.
하나의 피팅에 대해 여러 설정을 시도해 볼 수도 있고, 여러 피팅을 만들어서 비교해 볼 수도 있습니다. 곡선 피팅기 앱에서 여러 피팅을 만든 경우 여러 피팅 유형과 설정을 나란히 비교할 수 있습니다. 자세한 내용은 Create Multiple Fits in Curve Fitter App 항목을 참조하십시오.
프로그래밍 방식으로 모델 유형 선택하기
fit 함수를 호출할 때 라이브러리 모델 이름을 문자형 벡터나 string형 스칼라로 지정할 수 있습니다. 예를 들어, 다음과 같이 2차 poly2 모델을 지정할 수 있습니다.
f = fit(x,y,"poly2")사용 가능한 모든 라이브러리 모델 이름을 보려면 곡선과 곡면 피팅 라이브러리 모델 목록 항목을 참조하십시오.
fittype 함수를 사용하여 라이브러리 모델에 대한 fittype 객체를 생성하고, fittype을 fit 함수에 대한 입력값으로 사용할 수도 있습니다.
설정할 수 있는 파라미터를 확인하려면 fitoptions 함수를 사용하십시오. 예를 들면 다음과 같습니다.
fitoptions(poly2)
다른 예를 보려면 대화형 방식으로 모델 유형 선택하기에 나와 있는 표에서 각 모델 유형의 섹션을 참조하십시오. 모델 생성 및 분석에 사용되는 모든 함수에 대해 자세히 알아보려면 곡선 및 곡면 피팅 항목을 참조하십시오.
데이터 정규화하기
곡선 피팅기 앱의 피팅 대부분은 피팅 옵션 창에 정규화 옵션을 제공합니다. 이 옵션을 선택하면 앱은 정규화된 데이터로 모델을 다시 피팅합니다.
대규모 변수의 반올림 오차와 같은 수치적 문제를 완화하려면 입력 데이터(예측 변수 데이터라고도 함)를 정규화하십시오. 정규화는 일반적으로 모든 변수가 피팅에 고르게 기여할 수 있게 하여 수치적 불안정성을 줄이고 피팅을 개선합니다. 이 옵션을 사용하여 입력값을 정규화하면 피팅된 계수의 값은 원래 데이터에 비해 달라집니다. 따라서 계수에 물리 중요도가 있는 경우(예: 지리 데이터의 동방위와 북방위)나 계수를 추정하기 위해 피팅하는 경우 입력 데이터를 정규화해서는 안 됩니다.
곡선 피팅기 앱의 플롯은 정규화 상태와 관계없이 항상 원래 척도를 사용합니다.
명령줄에서 피팅 전에 데이터를 정규화하려면 fit 함수를 Normalize="on"과 함께 사용하거나 options.Normalize를 "on"으로 지정하고 fitoptions 함수를 사용하여 options 구조체를 만듭니다. 그런 다음 지정된 옵션과 함께 fit 함수를 사용합니다.
options = fitoptions; options.Normalize = "on"; options options = basefitoptions with properties: Normalize: 'on' Exclude: [] Weights: [] Method: 'None' load census f1 = fit(cdate,pop,"poly3",options)
고급 옵션
곡선 피팅기 앱
곡선 피팅기 앱의 피팅 옵션 창에서 대화형 방식으로 고급 피팅 옵션을 지정할 수 있습니다. 보간, 평활화 스플라인, Lowess를 제외한 모든 피팅에는 구성 가능한 고급 피팅 옵션이 있습니다. 사용 가능한 옵션은 선택한 피팅(즉, 선형, 비선형 또는 비모수적 피팅)에 따라 달라집니다.
비모수적 피팅(즉, 보간, 평활화 스플라인 및 Lowess 피팅)에는 고급 옵션이 없습니다.
달리 지정되지 않는 한 아래 설명된 옵션은 비선형 모델에만 사용할 수 있습니다.
단일 항 지수 피팅에 대한 피팅 옵션 창이 아래에 나와 있습니다.

명령줄
피팅 전에 디폴트 fit options 구조체를 만들고 데이터를 정규화하도록 옵션을 설정합니다.
options = fitoptions; options.Normalize = 'on'; options options = basefitoptions with properties: Normalize: 'on' Exclude: [] Weights: [] Method: 'None'
Normalize, Exclude 또는 Weights 필드를 설정한 후 다른 피팅 방법에 동일한 옵션을 사용하여 데이터를 피팅하려는 경우 디폴트 fit options 구조체를 수정하는 것이 편리합니다. 예를 들어, 다음과 같이 입력합니다.
load census f1 = fit(cdate,pop,"poly3",options); f2 = fit(cdate,pop,"exp1",options); f3 = fit(cdate,pop,"cubicspline",options);
fit 함수의 세 번째 출력 인수로 데이터 종속적인 피팅 옵션이 반환됩니다. 예를 들어, 평활화 스플라인의 평활화 파라미터는 데이터 종속적입니다.
[f,gof,out] = fit(cdate,pop,"smoothingspline");
smoothparam = out.p
smoothparam =
0.0089피팅 옵션을 사용하여 새 피팅에 대한 디폴트 평활화 파라미터를 수정합니다.
options = fitoptions("Method","SmoothingSpline","SmoothingParam",0.0098); [f,gof,out] = fit(cdate,pop,"smoothingspline",options);
피팅 옵션을 사용하는 방법에 대한 자세한 내용은 fitoptions 함수를 참조하십시오.
계수 제약 조건: 한계 및 최적화된 시작점 지정하기
계수의 하한과 상한을 지정하여 계수에 제약 조건을 적용하고 계수의 시작점을 제공합니다. 명령줄에서 fit 함수 또는 fitoptions 함수를 Lower, Upper, StartPoint 옵션과 함께 사용합니다. 시작점은 비선형 fittype에만 지정할 수 있는 반면, 선형 fittype에는 시작점이 필요하지 않습니다. 디폴트 제약 조건과 최적화된 시작점에 대한 자세한 내용은 최적화된 시작점 및 디폴트 제약 조건 항목을 참조하십시오.

이러한 피팅 옵션에 대한 자세한 내용은 lsqcurvefit (Optimization Toolbox) 함수를 참조하십시오.
최적화된 시작점 및 디폴트 제약 조건
다음 표에는 피팅 유형 창의 피팅에 대한 디폴트 계수 시작점과 제약 조건이 나와 있습니다. 시작점이 최적화된 경우에는 현재 데이터 세트에 따라 발견적 방식으로 계산됩니다. [0 1] 구간 내에 임의의 시작점이 정의되며, 선형 모델에는 시작점이 필요하지 않습니다. 모델에 제악 조건이 없는 경우, 계수는 하한도 상한도 갖지 않습니다. 피팅 옵션 창에서 사용자 고유의 값을 제공하여 디폴트 시작점과 제약 조건을 재정의할 수 있습니다.
피팅 | 시작점 | 제약 조건 |
|---|---|---|
| N/A | 없음 |
| 임의 | 없음 |
| 최적화됨 | 없음 |
로그 | N/A | 없음 |
| 최적화됨 | 없음 |
| 최적화됨 | ci > 0 |
| N/A | 없음 |
| 최적화됨 | 없음 |
| 임의 | 없음 |
| 최적화됨 | bi > 0 |
| 임의 | a, b > 0 |
시그모이드(모델을 4-파라미터 로지스틱으로 설정) | 최적화됨 | x/c > 0 |
사인 합 피팅과 푸리에 피팅은 특히 시작점에 민감하며, 최적화된 값은 관련 방정식에서 몇 개 항에 대해서만 정확할 수 있음을 유의하십시오.
피팅에 사용할 제약 조건 점(Optimization Toolbox 필요)
곡선 피팅기 앱에서 또는 명령줄에서 ConstraintPoints 이름-값 인수를 사용해 제약 조건 점을 추가하여 회귀 fittype이 특정 점을 통과하도록 제약 조건을 적용할 수 있습니다. 비모수적 피팅(즉, 보간, 평활화 스플라인 및 Lowess 피팅)은 제약 조건 점을 받지 않습니다.
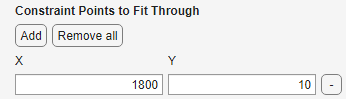
제약 조건 점을 사용하면 곡선이나 곡면을 원점, 하나 이상의 데이터 점 또는 임의의 좌표에 피팅할 수 있습니다.
제약 조건 점의 개수는 fittype의 계수 개수보다 클 수 없습니다. 예를 들어, 다음 1차 다항식은
최대 2개의 제약 조건 점으로 피팅될 수 있습니다.
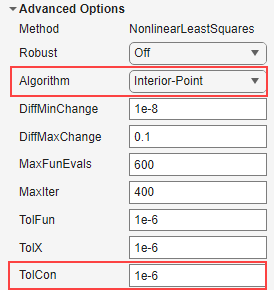
제약 조건 허용오차는 TolCon을 설정하여 지정할 수 있습니다. 이는 제공된 제약 조건 점과 피팅이 통과하는 실제 점 간의 절대 수치적 차이의 상한이며, 이를 초과하면 제약 조건 위반으로 간주됩니다.
비선형 fittype에 대한 제약 조건 점이 제공되는 경우, 즉 메서드가
NonlinearLeastSquares인 경우 피팅 알고리즘은Interior-Point여야 합니다.
팁
제약 조건 위반으로 인한 경고를 디버그하려면 명령줄에서 Display 이름-값 인수를 "iter"로 설정하고 제약 조건 점을 포함하여 워크플로를 반복하십시오.