fit
곡선 또는 곡면을 데이터에 피팅
구문
설명
fitobject = fit(x,y,fitType,Name=Value)Name=Value 쌍 인수로 지정된 추가 옵션과 함께 라이브러리 모델 fitType을 사용하여 데이터에 대한 피팅을 만듭니다. 지정된 라이브러리 모델에 대해 사용 가능한 속성 이름과 디폴트 값을 표시하려면 fitoptions를 사용하십시오.
예제
census 샘플 데이터 세트를 불러옵니다.
load census;벡터 pop와 벡터 cdate는 각각 모집단 크기와 인구 조사를 실시한 연도에 대한 데이터를 포함하고 있습니다.
2차 곡선을 모집단 데이터에 피팅합니다.
f=fit(cdate,pop,'poly2')f =
Linear model Poly2:
f(x) = p1*x^2 + p2*x + p3
Coefficients (with 95% confidence bounds):
p1 = 0.006541 (0.006124, 0.006958)
p2 = -23.51 (-25.09, -21.93)
p3 = 2.113e+04 (1.964e+04, 2.262e+04)
f는 95% 신뢰한계의 계수 추정값을 비롯한 피팅 결과를 포함합니다.
데이터의 산점도 플롯과 함께 f의 피팅을 플로팅합니다.
plot(f,cdate,pop)
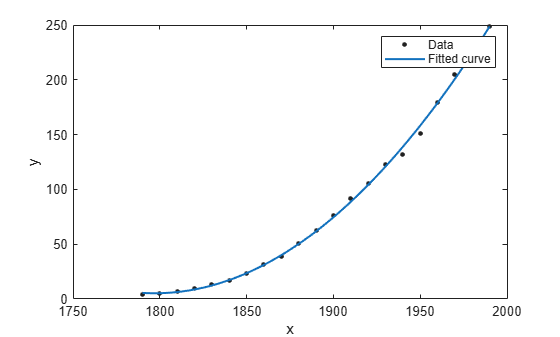
이 플롯은 피팅된 곡선이 모집단 데이터를 가깝게 따라가고 있음을 보여줍니다.
franke 샘플 데이터 세트를 불러옵니다.
load franke벡터 x, y, z는 추가된 잡음과 스케일링이 있는 Franke의 이변량 테스트 함수에서 생성된 데이터를 포함합니다.
다항식 곡면을 데이터에 피팅합니다. x 항에 대해 차수 2를 지정하고 y 항에 대해 차수 3을 지정합니다.
sf = fit([x, y],z,'poly23')sf =
Linear model Poly23:
sf(x,y) = p00 + p10*x + p01*y + p20*x^2 + p11*x*y + p02*y^2 + p21*x^2*y
+ p12*x*y^2 + p03*y^3
Coefficients (with 95% confidence bounds):
p00 = 1.118 (0.9149, 1.321)
p10 = -0.0002941 (-0.000502, -8.623e-05)
p01 = 1.533 (0.7032, 2.364)
p20 = -1.966e-08 (-7.084e-08, 3.152e-08)
p11 = 0.0003427 (-0.0001009, 0.0007863)
p02 = -6.951 (-8.421, -5.481)
p21 = 9.563e-08 (6.276e-09, 1.85e-07)
p12 = -0.0004401 (-0.0007082, -0.0001721)
p03 = 4.999 (4.082, 5.917)
sf는 95% 신뢰한계의 계수 추정값을 비롯한 피팅 결과를 포함합니다.
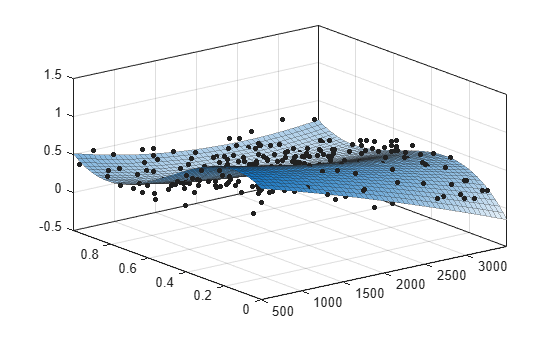
데이터의 산점도 플롯과 함께 sf의 피팅을 플로팅합니다.
plot(sf,[x,y],z)
데이터를 불러와서 플로팅하고, fittype 함수와 fitoptions 함수를 사용하여 피팅 옵션과 피팅 유형을 만든 다음, 피팅을 만들고 플로팅합니다.
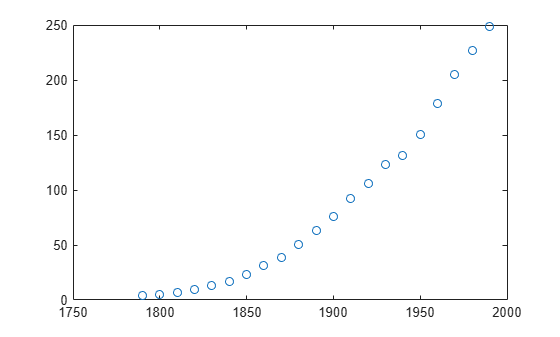
census.mat의 데이터를 불러와서 플로팅합니다.
load census plot(cdate,pop,'o')
사용자 지정 비선형 모델 에 대한 fit options 객체와 피팅 유형을 만듭니다. 여기서 a와 b는 계수이고 n은 문제 종속적인 파라미터입니다.
fo = fitoptions('Method','NonlinearLeastSquares',... 'Lower',[0,0],... 'Upper',[Inf,max(cdate)],... 'StartPoint',[1 1]); ft = fittype('a*(x-b)^n','problem','n','options',fo);
피팅 옵션과 값 n = 2를 사용하여 데이터를 피팅합니다.
[curve2,gof2] = fit(cdate,pop,ft,'problem',2)curve2 =
General model:
curve2(x) = a*(x-b)^n
Coefficients (with 95% confidence bounds):
a = 0.006092 (0.005743, 0.006441)
b = 1789 (1784, 1793)
Problem parameters:
n = 2
gof2 = struct with fields:
sse: 246.1543
rsquare: 0.9980
dfe: 19
adjrsquare: 0.9979
rmse: 3.5994
피팅 옵션과 값 n = 3을 사용하여 데이터를 피팅합니다.
[curve3,gof3] = fit(cdate,pop,ft,'problem',3)curve3 =
General model:
curve3(x) = a*(x-b)^n
Coefficients (with 95% confidence bounds):
a = 1.359e-05 (1.245e-05, 1.474e-05)
b = 1725 (1718, 1731)
Problem parameters:
n = 3
gof3 = struct with fields:
sse: 232.0058
rsquare: 0.9981
dfe: 19
adjrsquare: 0.9980
rmse: 3.4944
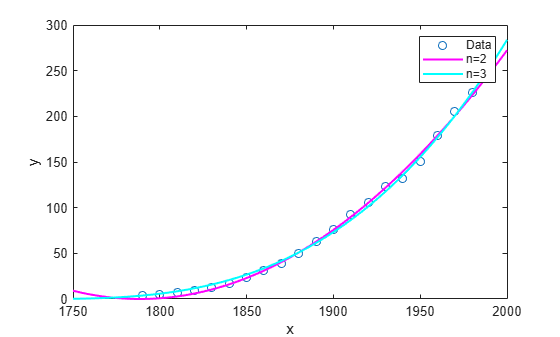
피팅 결과를 데이터와 함께 플로팅합니다.
hold on plot(curve2,'m') plot(curve3,'c') legend('Data','n=2','n=3') hold off
carbon12alpha 핵반응 샘플 데이터 세트를 불러옵니다.
load carbon12alphaangle은 방출 각도(단위: 라디안)로 구성된 벡터입니다. counts는 angle의 각도에 대응하는 원시 알파 입자 개수로 구성된 벡터입니다.
각도에 대해 플로팅된 개수의 산점도 플롯을 표시합니다.
scatter(angle,counts)

산점도 플롯은 각도가 0과 4.5 사이에서 증가함에 따라 개수가 진동함을 보여줍니다. 다항식 모델을 데이터에 피팅하려면 fitType 입력 인수를 "poly#"로 지정합니다. 여기서 #는 1에서 9 사이의 정수입니다. 최대 9차까지 모델을 피팅할 수 있습니다. 자세한 내용은 곡선과 곡면 피팅 라이브러리 모델 목록 항목을 참조하십시오.
5차, 7차 및 9차 다항식을 핵반응 데이터에 피팅합니다. 각 피팅에 대한 적합도 통계량을 반환합니다.
[f5,gof5] = fit(angle,counts,"poly5"); [f7,gof7] = fit(angle,counts,"poly7"); [f9,gof9] = fit(angle,counts,"poly9");
linspace 함수를 사용하여 0과 4.5 사이에 있는 쿼리 점으로 구성된 벡터를 생성합니다. 쿼리 점에서 다항식 피팅을 평가한 후 핵반응 데이터와 함께 이를 플로팅합니다.
xq = linspace(0,4.5,1000); figure hold on scatter(angle,counts,"k") plot(xq,f5(xq)) plot(xq,f7(xq)) plot(xq,f9(xq)) ylim([-100,550]) legend("original data","fifth-degree polynomial","seventh-degree polynomial","ninth-degree polynomial")

플롯은 9차 다항식이 가장 근접하게 데이터를 따라가고 있음을 보여줍니다.
struct2table 함수를 사용하여 각 피팅에 대한 적합도 통계량을 표시합니다.
gof = struct2table([gof5 gof7 gof9],RowNames=["f5" "f7" "f9"])
gof=3×5 table
sse rsquare dfe adjrsquare rmse
__________ _______ ___ __________ ______
f5 1.0901e+05 0.54614 18 0.42007 77.82
f7 32695 0.86387 16 0.80431 45.204
f9 3660.2 0.98476 14 0.97496 16.169
9차 다항식 피팅의 오차 제곱합(SSE)은 5차 다항식 피팅과 7차 다항식 피팅의 SSE보다 작습니다. 이 결과는 9차 다항식이 가장 근접하게 데이터를 따라가고 있음을 입증합니다.
census 샘플 데이터 세트를 불러옵니다. 3차 다항식을 피팅하고 Normalize(정규화) 옵션과 Robust 피팅 옵션을 지정합니다.
load census; f = fit(cdate,pop,'poly3','Normalize','on','Robust','Bisquare')
f =
Linear model Poly3:
f(x) = p1*x^3 + p2*x^2 + p3*x + p4
where x is normalized by mean 1890 and std 62.05
Coefficients (with 95% confidence bounds):
p1 = -0.4619 (-1.895, 0.9707)
p2 = 25.01 (23.79, 26.22)
p3 = 77.03 (74.37, 79.7)
p4 = 62.81 (61.26, 64.37)
피팅을 플로팅합니다.
plot(f,cdate,pop)
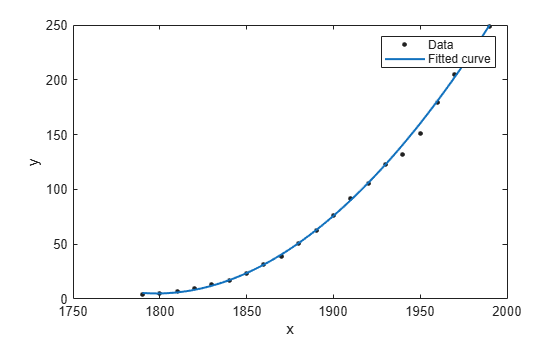
지수적 추세를 갖는 데이터를 생성하고 단일 항 지수를 사용하여 데이터를 피팅합니다. 피팅과 데이터를 플로팅합니다.
rng(2,"twister"); x = (0:0.2:10)'; y = 2*exp(0.2*x) + 0.2*randn(size(x)); % Without constraints fitresult1 = fit(x,y,"exp1"); plot(fitresult1,x,y); hold on
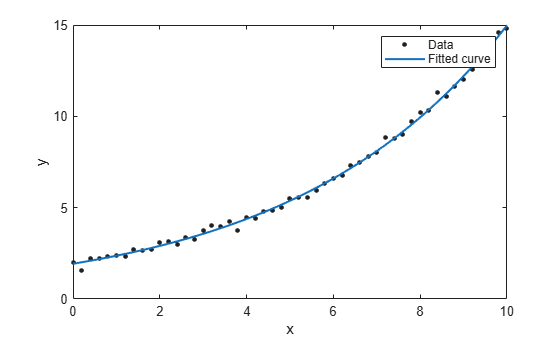
두 번째 데이터 점을 제약 조건으로 설정하여 새로운 지수 곡선을 피팅합니다. 비선형 fittype이므로 제약 조건 점으로 피팅하려면 Algorithm을 "Interior-Point"로 지정해야 합니다. 지정하지 않으면 내부적으로 "Interior-Point" 알고리즘을 사용하도록 전환됩니다.
% With constraints point = [x(2) y(2)]; fitresult2 = fit(x,y,"exp1",ConstraintPoints=point,Algorithm="Interior-Point"); plot(fitresult2); plot(point(:,1),point(:,2),"*"); legend("Data","Without Constraints","With Constraints", ... "Constraint Point",Location="best");

파일에 함수를 정의하고 이를 사용하여 피팅 유형을 만든 후 곡선을 피팅합니다.
함수를 MATLAB® 파일에 정의합니다.
type piecewiseLine.mfunction y = piecewiseLine(x,a,b,c,k)
% PIECEWISELINE A line made of two pieces
y = zeros(size(x));
% This example includes a for-loop and if statement
% purely for example purposes.
for i = 1:length(x)
if x(i) < k
y(i) = a + b.*x(i);
else
y(i) = a + b*k + c.*(x(i)-k);
end
end
end
파일을 저장합니다.
일부 데이터를 정의하고, 함수 piecewiseLine을 지정하여 피팅 유형을 만듭니다.
x = [0.81;0.91;0.13;0.91;0.63;0.098;0.28;0.55;... 0.96;0.96;0.16;0.97;0.96]; y = [0.17;0.12;0.16;0.0035;0.37;0.082;0.34;0.56;... 0.15;-0.046;0.17;-0.091;-0.071]; ft = fittype('piecewiseLine( x, a, b, c, k )')
ft =
General model:
ft(a,b,c,k,x) = piecewiseLine( x, a, b, c, k )
ft에 대한 입력값은 사전순으로 나열된 계수와 그 뒤에 오는 독립 변수들로 구성됩니다. 자세한 내용은 익명 함수의 입력 순서 항목을 참조하십시오.
계수의 순서를 제어하려면 익명 함수 입력값을 사용하십시오. 예를 들어, 계수 a와 b의 순서를 변경하려면 다음을 입력하십시오.
ft = fittype(@(b,a,c,k,x) piecewiseLine(x,a,b,c,k))
독립 변수 x를 마지막에 지정해야 합니다.
피팅 유형 ft를 사용하여 피팅을 만든 다음 결과를 플로팅합니다.
f = fit(x, y, ft, 'StartPoint', [1, 0, 1, 0.5]);
plot(f, x, y)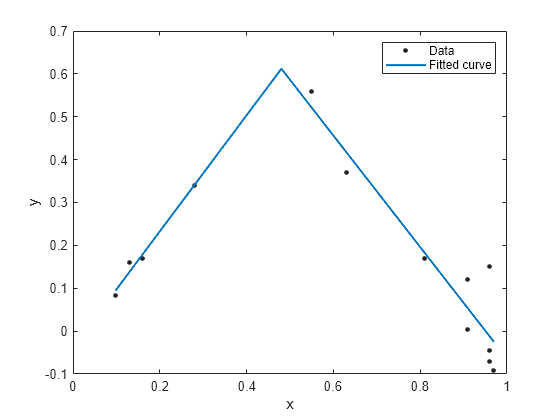
제외된 점을 변수로 정의한 다음 이를 fit 함수에 대한 입력값으로 제공할 수 있습니다. 다음 단계에서는 위 예제의 피팅을 다시 생성하여 데이터와 피팅뿐만 아니라 제외된 점도 플로팅할 수 있도록 합니다.
데이터를 불러와서 사용자 지정 수식과 몇몇 시작점을 정의합니다.
[x, y] = titanium;
gaussEqn = 'a*exp(-((x-b)/c)^2)+d'gaussEqn = 'a*exp(-((x-b)/c)^2)+d'
startPoints = [1.5 900 10 0.6]
startPoints = 1×4
1.5000 900.0000 10.0000 0.6000
인덱스 벡터와 표현식을 사용하여 제외할 점 집합 2개를 정의합니다.
exclude1 = [1 10 25]; exclude2 = x < 800;
사용자 지정 수식, 시작점, 2개의 제외된 점 집합을 사용하여 2개의 피팅을 만듭니다.
f1 = fit(x',y',gaussEqn,'Start', startPoints, 'Exclude', exclude1); f2 = fit(x',y',gaussEqn,'Start', startPoints, 'Exclude', exclude2);
두 피팅을 모두 플로팅하고 제외된 데이터를 강조 표시합니다.
plot(f1,x,y,exclude1)
title('Fit with data points 1, 10, and 25 excluded')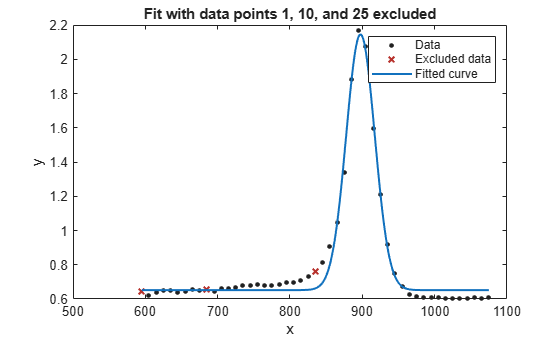
figure;
plot(f2,x,y,exclude2)
title('Fit with data points excluded such that x < 800')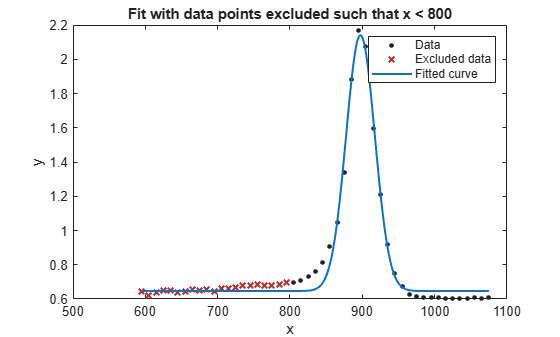
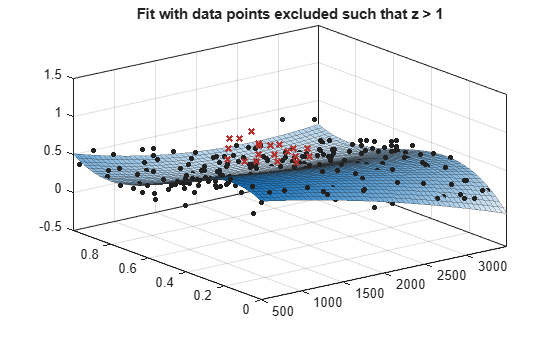
제외된 점이 있는 곡면 피팅 예로, 곡면 데이터를 불러와서 제외된 데이터를 지정하여 피팅을 만들고 플로팅합니다.
load franke f1 = fit([x y],z,'poly23', 'Exclude', [1 10 25]); f2 = fit([x y],z,'poly23', 'Exclude', z > 1); figure plot(f1, [x y], z, 'Exclude', [1 10 25]); title('Fit with data points 1, 10, and 25 excluded')
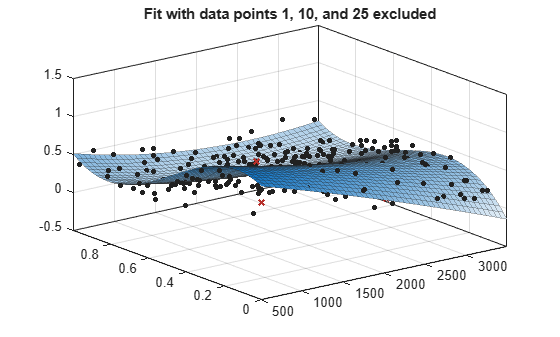
figure plot(f2, [x y], z, 'Exclude', z > 1); title('Fit with data points excluded such that z > 1')
membrane 함수와 randn 함수를 사용하여 잡음 있는 데이터를 생성합니다.
n = 41; M = membrane(1,20)+0.02*randn(n); [X,Y] = meshgrid(1:n);
행렬 M은 추가된 잡음이 있는 L 모양의 멤브레인에 대한 데이터를 포함하고 있습니다. 행렬 X와 행렬 Y는 M의 대응하는 요소에 대한 행 인덱스 값과 열 인덱스 값을 각각 포함하고 있습니다.
데이터의 곡면 플롯을 표시합니다.
figure(1) surf(X,Y,M)

플롯은 주름이 있는 L 모양의 멤브레인을 보여줍니다. 멤브레인의 주름은 데이터의 잡음으로 인해 발생합니다.
선형 보간을 사용하여 주름이 있는 멤브레인을 통과하도록 두 곡면을 피팅합니다. 첫 번째 곡면의 경우, 선형 외삽 방법을 지정합니다. 두 번째 곡면의 경우, 외삽 방법을 최근접이웃으로 지정합니다.
flinextrap = fit([X(:),Y(:)],M(:),"linearinterp",ExtrapolationMethod="linear"); fnearextrap = fit([X(:),Y(:)],M(:),"linearinterp",ExtrapolationMethod="nearest");
X 데이터와 Y 데이터의 컨벡스 헐 외부에 있는 쿼리 점에서 피팅을 평가하기 위해 meshgrid 함수를 사용하여 외삽 방법 간의 차이를 조사합니다.
[Xq,Yq] = meshgrid(-10:50); Zlin = flinextrap(Xq,Yq); Znear = fnearextrap(Xq,Yq);
평가된 피팅을 플로팅합니다.
figure(2) surf(Xq,Yq,Zlin) title("Linear Extrapolation") xlabel("X") ylabel("Y") zlabel("M")

figure(3) surf(Xq,Yq,Znear) title("Nearest Neighbor Extrapolation") xlabel("X") ylabel("Y") zlabel("M")
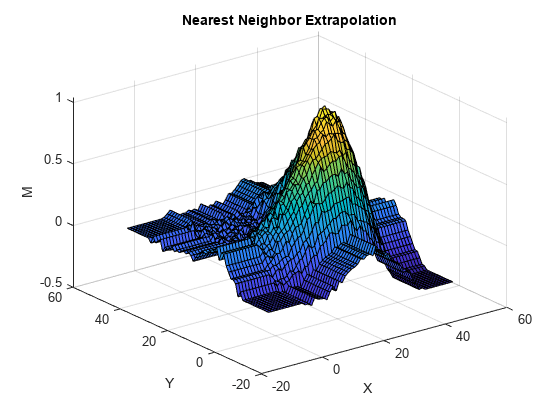
선형 외삽 방법은 컨벡스 헐의 외부에서 스파이크를 생성합니다. 스파이크를 형성하는 평면 부분은 컨벡스 헐의 테두리에 있는 점의 기울기를 따라갑니다. 최근접이웃 외삽 방법은 테두리에 있는 데이터를 사용하여 곡면을 각 방향으로 확장합니다. 이 외삽 방법은 테두리를 모방하는 파형을 생성합니다.
평활화 스플라인 곡선을 피팅하고 적합도 통계량과 피팅 알고리즘에 대한 정보를 반환합니다.
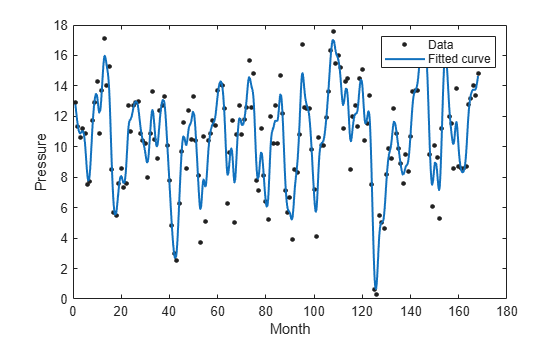
enso 샘플 데이터 세트를 불러옵니다. enso 샘플 데이터 세트는 이스터 섬과 호주의 다윈 간의 월별 평균 대기압 차이에 대한 데이터를 포함하고 있습니다.
load enso;평활화 스플라인 곡선을 month의 데이터와 pressure의 데이터에 피팅하고 적합도 통계량과 output 구조체를 반환합니다.
[curve,gof,output] = fit(month,pressure,"smoothingspline");곡선을 피팅하는 데 사용된 데이터와 함께, 피팅된 곡선을 플로팅합니다.
plot(curve,month,pressure); xlabel("Month"); ylabel("Pressure");
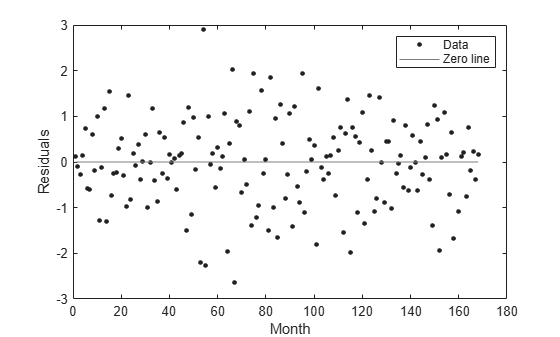
x 데이터(month)에 대해 잔차를 플로팅합니다.
plot(curve,month,pressure,"residuals") xlabel("Month") ylabel("Residuals")
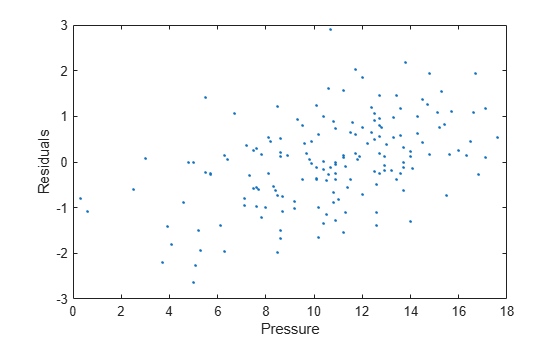
output 구조체에 있는 residuals 데이터를 사용하여 y 데이터(pressure)에 대해 잔차를 플로팅합니다. output의 residuals 필드에 액세스하려면 점 표기법을 사용합니다.
residuals = output.residuals; plot( pressure,residuals,".") xlabel("Pressure") ylabel("Residuals")
익명 함수를 사용하여 fit 함수로 다른 데이터를 보다 쉽게 전달할 수 있습니다.
익명 함수를 정의하기 전에 먼저 데이터를 불러오고 Emax를 1로 설정합니다.
data = importdata( 'OpioidHypnoticSynergy.txt' );
Propofol = data.data(:,1);
Remifentanil = data.data(:,2);
Algometry = data.data(:,3);
Emax = 1;모델 방정식을 익명 함수로 정의합니다.
Effect = @(IC50A, IC50B, alpha, n, x, y) ... Emax*( x/IC50A + y/IC50B + alpha*( x/IC50A )... .* ( y/IC50B ) ).^n ./(( x/IC50A + y/IC50B + ... alpha*( x/IC50A ) .* ( y/IC50B ) ).^n + 1);
익명 함수 Effect를 fit 함수에 대한 입력값으로 사용하고 결과를 플로팅합니다.
AlgometryEffect = fit( [Propofol, Remifentanil], Algometry, Effect, ... 'StartPoint', [2, 10, 1, 0.8], ... 'Lower', [-Inf, -Inf, -5, -Inf], ... 'Robust', 'LAR' ) plot( AlgometryEffect, [Propofol, Remifentanil], Algometry )
익명 함수와 피팅용 기타 사용자 지정 모델에 관한 다른 예제는 fittype 함수를 참조하십시오.
Upper, Lower, StartPoint 속성의 경우 계수 요소의 순서를 찾아야 합니다.
피팅 유형을 만듭니다.
ft = fittype('b*x^2+c*x+a');coeffnames 함수를 사용하여 계수의 이름과 순서를 가져옵니다.
coeffnames(ft)
ans = 3×1 cell
{'a'}
{'b'}
{'c'}
이것은 fittype을 사용하여 ft를 만들 때 사용한 표현식의 계수 순서와 다릅니다.
데이터를 불러오고 피팅을 만든 후 시작점을 설정합니다.
load enso fit(month,pressure,ft,'StartPoint',[1,3,5])
ans =
General model:
ans(x) = b*x^2+c*x+a
Coefficients (with 95% confidence bounds):
a = 10.94 (9.362, 12.52)
b = 0.0001677 (-7.985e-05, 0.0004153)
c = -0.0224 (-0.06559, 0.02079)
이렇게 하면 계수에 초기값이 a = 1, b = 3, c = 5와 같이 할당됩니다.
또는 피팅 옵션을 가져와서 시작점과 하한을 설정하고 이 새로운 옵션을 사용하여 다시 피팅할 수도 있습니다.
options = fitoptions(ft)
options =
nlsqoptions with properties:
StartPoint: []
Algorithm: 'Trust-Region'
DiffMinChange: 1.0000e-08
DiffMaxChange: 0.1000
Display: 'Notify'
MaxFunEvals: 600
MaxIter: 400
TolFun: 1.0000e-06
TolX: 1.0000e-06
Lower: []
Upper: []
ConstraintPoints: []
TolCon: 1.0000e-06
Robust: 'Off'
Normalize: 'off'
Exclude: []
Weights: []
Method: 'NonlinearLeastSquares'
options.StartPoint = [10 1 3]; options.Lower = [0 -Inf 0]; fit(month,pressure,ft,options)
ans =
General model:
ans(x) = b*x^2+c*x+a
Coefficients (with 95% confidence bounds):
a = 10.23 (9.448, 11.01)
b = 4.335e-05 (-1.82e-05, 0.0001049)
c = 5.523e-12 (fixed at bound)