lsqcurvefit
최소제곱을 사용하여 비선형 곡선 피팅(데이터 피팅) 문제 풀기
구문
설명
비선형 최소제곱 솔버
다음 문제를 푸는 계수 x를 구합니다.
입력 데이터 xdata와 관측된 출력값 ydata가 주어지며, 여기서 xdata 및 ydata는 행렬 또는 벡터이고, F (x, xdata)는 ydata와 크기가 같은 행렬 값 또는 벡터 값을 갖는 함수입니다.
선택적으로 x의 성분이 다음 제약 조건에 적용됩니다.
인수 x, lb, ub는 벡터 또는 행렬일 수 있습니다. 행렬 인수 항목을 참조하십시오.
lsqcurvefit 함수는 lsqnonlin과 동일한 알고리즘을 사용합니다. lsqcurvefit은 데이터 피팅 문제를 위한 편리한 인터페이스를 제공합니다.
제곱합을 계산하는 대신 lsqcurvefit에서는 사용자 정의 함수가 다음과 같이 벡터 값을 갖는 함수를 계산해야 합니다.
예제
관측 시간 데이터 xdata와 관측된 응답 변수 데이터 ydata가 있고 파라미터 및 를 찾아 다음 형식의 모델을 피팅하기를 원한다고 가정하겠습니다.
관측 시간과 응답 변수를 입력합니다.
xdata = ... [0.9 1.5 13.8 19.8 24.1 28.2 35.2 60.3 74.6 81.3]; ydata = ... [455.2 428.6 124.1 67.3 43.2 28.1 13.1 -0.4 -1.3 -1.5];
단순한 지수 감쇠 모델을 만듭니다.
fun = @(x,xdata)x(1)*exp(x(2)*xdata);
시작점 x0 = [100,-1]을 사용하여 모델을 피팅합니다.
x0 = [100,-1]; x = lsqcurvefit(fun,x0,xdata,ydata)
Local minimum possible. lsqcurvefit stopped because the final change in the sum of squares relative to its initial value is less than the value of the function tolerance. <stopping criteria details>
x = 1×2
498.8309 -0.1013
데이터와 피팅된 곡선을 플로팅합니다.
times = linspace(xdata(1),xdata(end)); plot(xdata,ydata,"ko",times,fun(x,times),"b-") legend("Data","Fitted exponential") title("Data and Fitted Curve")
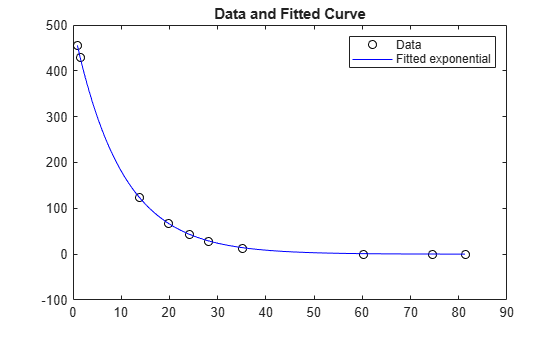
피팅 파라미터가 제한된 데이터에 대한 최적의 지수 피팅을 찾습니다.
잡음이 추가된 지수 감쇠 모델에서 데이터를 생성합니다. 모델은 다음과 같습니다.
의 범위는 0부터 3까지이며 은 평균이 0이고 표준편차가 0.05인 정규분포된 잡음입니다.
rng default % for reproducibility xdata = linspace(0,3); ydata = exp(-1.3*xdata) + 0.05*randn(size(xdata));
문제: 데이터(xdata, ydata)가 주어진 경우 파라미터의 범위가 다음과 같이 지정된 상태에서 데이터를 최적으로 피팅하는 지수 감쇠 모델 를 찾습니다.
lb = [0,-2]; ub = [3/4,-1];
모델을 만듭니다.
fun = @(x,xdata)x(1)*exp(x(2)*xdata);
초기 추측값을 만듭니다.
x0 = [1/2,-2];
유계 피팅 문제를 풉니다.
x = lsqcurvefit(fun,x0,xdata,ydata,lb,ub)
Local minimum found. Optimization completed because the size of the gradient is less than the value of the optimality tolerance. <stopping criteria details>
x = 1×2
0.7500 -1.0000
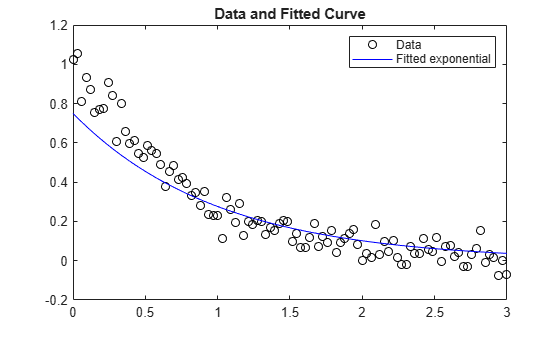
결과로 생성된 곡선이 얼마나 잘 데이터를 피팅하는지 검토합니다. 범위가 해를 실제 값에서 멀리 떨어지도록 하므로 피팅이 좋은 편은 아닙니다.
plot(xdata,ydata,"ko",xdata,fun(x,xdata),"b-") legend("Data","Fitted exponential") title("Data and Fitted Curve")
2에서 7까지의 시간 에 파라미터 , , , 를 사용하여 비선형 모델 에 사용할 인위적인 데이터를 만듭니다. randn을 사용하여 데이터에 잡음을 추가합니다.
a = 2; % x(1) b = 4; % x(2) t0 = 5; % x(3) c = 1/2; % x(4) xdata = linspace(2,7); rng default ydata = a + b*atan(xdata - t0) + c*xdata + 1/10*randn(size(xdata));
데이터를 플로팅합니다.
plot(xdata,ydata,"ro")
다음과 같은 제약 조건이 있는 데이터에 비선형 모델을 피팅합니다.
모든 계수는 0과 7 사이입니다.
.
A = [-1 -1 1 1]및b = 0을 사용하여A*x <= b형식으로 이 제약 조건을 작성할 수 있습니다.
lb = zeros(4,1); ub = 7*ones(4,1); A = [-1 -1 1 1]; b = 0;
이 예제의 마지막 부분에 있는 myfun 함수는 이 모델에 대한 목적 함수를 생성합니다.
점 [1 2 3 1]에서 시작하여 피팅 문제를 풉니다.
startpt = [1 2 3 1]; Aeq = []; beq = []; [x,res] = lsqcurvefit(@myfun,startpt,xdata,ydata,lb,ub,A,b,Aeq,beq)
Local minimum found that satisfies the constraints. Optimization completed because the objective function is non-decreasing in feasible directions, to within the value of the optimality tolerance, and constraints are satisfied to within the value of the constraint tolerance. <stopping criteria details>
x = 1×4
2.3447 4.0972 4.9979 0.4303
res = 1.2682
반환된 해는 원래 점 [2 4 5 1/2]에서 멀지 않습니다 해에 해당하는 점에서 곡선에 대해 데이터를 플로팅합니다.
plot(xdata,ydata,"ro",xdata,myfun(x,xdata),"b-")

반환된 해는 데이터와 상당히 일치합니다. 제약 조건이 활성 상태일까요?
A*x(:)
ans = -1.0137
A*x < 0이기 때문에 제약 조건은 활성 상태가 아닙니다.
function F = myfun(x,xdata) a = x(1); b = x(2); t0 = x(3); c = x(4); F = a + b*atan(xdata - t0) + c*xdata; end
2에서 7까지의 시간 에 파라미터 , , , 를 사용하여 비선형 모델 에 사용할 인위적인 데이터를 만듭니다. randn을 사용하여 데이터에 잡음을 추가합니다.
a = 2; % x(1) b = 4; % x(2) t0 = 5; % x(3) c = 1/2; % x(4) xdata = linspace(2,7); rng default ydata = a + b*atan(xdata - t0) + c*xdata + 1/10*randn(size(xdata));
데이터를 플로팅합니다.
plot(xdata,ydata,"ro")
다음과 같은 제약 조건이 있는 데이터에 비선형 모델을 피팅합니다.
모든 계수는 0과 7 사이입니다.
lb = zeros(4,1); ub = 7*ones(4,1);
문제에 선형 제약 조건이 없습니다.
A = []; b = []; Aeq = []; beq = [];
이 예제의 마지막 부분에 있는 myfun 함수는 이 모델에 대한 목적 함수를 생성합니다. 이 예제의 마지막 부분에 있는 nlcon 함수는 비선형 제약 조건 함수를 생성합니다.
점 [1 2 3 1]에서 시작하여 피팅 문제를 풉니다.
startpt = [1 2 3 1]; [x,res] = lsqcurvefit(@myfun,startpt,xdata,ydata,lb,ub,A,b,Aeq,beq,@nlcon)
Feasible point with lower objective function value found, but optimality criteria not satisfied. See output.bestfeasible.. Local minimum found that satisfies the constraints. Optimization completed because the objective function is non-decreasing in feasible directions, to within the value of the optimality tolerance, and constraints are satisfied to within the value of the constraint tolerance. <stopping criteria details>
x = 1×4
1.3806 3.7542 5.0169 0.6337
res = 1.6018
원래 점 [2 4 5 1/2]에서 비선형 제약 조건을 위반했기 때문에 반환된 해 x는 이 원래 점에 없습니다. 해에 해당하는 점에서 곡선에 대해 데이터를 플로팅하고 제약 조건 함수를 계산합니다.
plot(xdata,ydata,"ro",xdata,myfun(x,xdata),"b-")

[ineqnonlin,eqnonlin] = nlcon(x)
ineqnonlin = -3.1307e-06
eqnonlin =
[]
해에서 ineqnonlin = 0이기 때문에 비선형 부등식 제약 조건은 활성 상태입니다.
해에 해당하는 점이 원래 점에 없지만 해 곡선은 데이터와 상당히 일치합니다.
function F = myfun(x,xdata) a = x(1); b = x(2); t0 = x(3); c = x(4); F = a + b*atan(xdata - t0) + c*xdata; end function [ineqnonlin,eqnonlin] = nlcon(x) eqnonlin = []; ineqnonlin = x(1)^2 + x(2)^2 - 4^2; end
디폴트 "trust-region-reflective" 알고리즘을 사용하는 경우와 "levenberg-marquardt" 알고리즘을 사용하는 경우의 피팅 결과를 비교합니다.
관측 시간 데이터 xdata와 관측된 응답 변수 데이터 ydata가 있고 파라미터 및 를 찾아 다음 형식의 모델을 피팅하기를 원한다고 가정하겠습니다.
관측 시간과 응답 변수를 입력합니다.
xdata = ... [0.9 1.5 13.8 19.8 24.1 28.2 35.2 60.3 74.6 81.3]; ydata = ... [455.2 428.6 124.1 67.3 43.2 28.1 13.1 -0.4 -1.3 -1.5];
단순한 지수 감쇠 모델을 만듭니다.
fun = @(x,xdata)x(1)*exp(x(2)*xdata);
시작점 x0 = [100,-1]을 사용하여 모델을 피팅합니다.
x0 = [100,-1]; x = lsqcurvefit(fun,x0,xdata,ydata)
Local minimum possible. lsqcurvefit stopped because the final change in the sum of squares relative to its initial value is less than the value of the function tolerance. <stopping criteria details>
x = 1×2
498.8309 -0.1013
해를 "levenberg-marquardt" 피팅의 해와 비교합니다.
options = optimoptions("lsqcurvefit",Algorithm="levenberg-marquardt"); lb = []; ub = []; x = lsqcurvefit(fun,x0,xdata,ydata,lb,ub,options)
Local minimum possible. lsqcurvefit stopped because the relative size of the current step is less than the value of the step size tolerance. <stopping criteria details>
x = 1×2
498.8309 -0.1013
두 알고리즘 모두 동일한 해로 수렴되었습니다. 데이터와 피팅된 지수 모델을 플로팅합니다.
times = linspace(xdata(1),xdata(end)); plot(xdata,ydata,"ko",times,fun(x,times),"b-") legend("Data","Fitted exponential") title("Data and Fitted Curve")
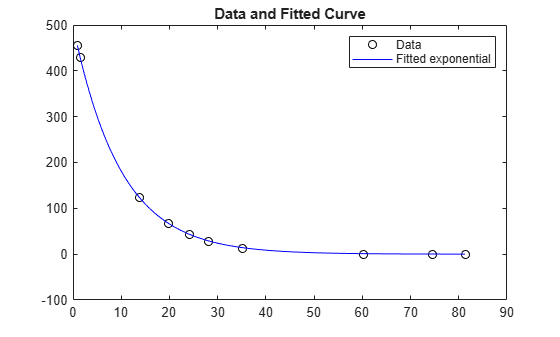
디폴트 "trust-region-reflective" 알고리즘을 사용하는 경우와 "levenberg-marquardt" 알고리즘을 사용하는 경우의 피팅 결과를 비교합니다. 풀이 과정을 검토하여 이 경우 무엇이 더 효율적인지 확인합니다.
관측 시간 데이터 xdata와 관측된 응답 변수 데이터 ydata가 있고 파라미터 및 를 찾아 다음 형식의 모델을 피팅하기를 원한다고 가정하겠습니다.
관측 시간과 응답 변수를 입력합니다.
xdata = ... [0.9 1.5 13.8 19.8 24.1 28.2 35.2 60.3 74.6 81.3]; ydata = ... [455.2 428.6 124.1 67.3 43.2 28.1 13.1 -0.4 -1.3 -1.5];
단순한 지수 감쇠 모델을 만듭니다.
fun = @(x,xdata)x(1)*exp(x(2)*xdata);
시작점 x0 = [100,-1]을 사용하여 모델을 피팅합니다.
x0 = [100,-1]; [x,resnorm,residual,exitflag,output] = lsqcurvefit(fun,x0,xdata,ydata);
Local minimum possible. lsqcurvefit stopped because the final change in the sum of squares relative to its initial value is less than the value of the function tolerance. <stopping criteria details>
해를 "levenberg-marquardt" 피팅의 해와 비교합니다.
options = optimoptions("lsqcurvefit",Algorithm="levenberg-marquardt"); lb = []; ub = []; [x2,resnorm2,residual2,exitflag2,output2] = lsqcurvefit(fun,x0,xdata,ydata,lb,ub,options);
Local minimum possible. lsqcurvefit stopped because the relative size of the current step is less than the value of the step size tolerance. <stopping criteria details>
해가 동일합니까?
norm(x-x2)
ans = 2.0642e-06
예, 해가 동일합니다.
어떤 알고리즘이 함수를 더 적게 실행하여 해에 도달했습니까?
fprintf(['The ''trust-region-reflective'' algorithm took %d function evaluations,\n',... 'and the ''levenberg-marquardt'' algorithm took %d function evaluations.\n'],... output.funcCount,output2.funcCount)
The 'trust-region-reflective' algorithm took 87 function evaluations, and the 'levenberg-marquardt' algorithm took 72 function evaluations.
데이터와 피팅된 지수 모델을 플로팅합니다.
times = linspace(xdata(1),xdata(end)); plot(xdata,ydata,"ko",times,fun(x,times),"b-") legend("Data","Fitted exponential") title("Data and Fitted Curve")
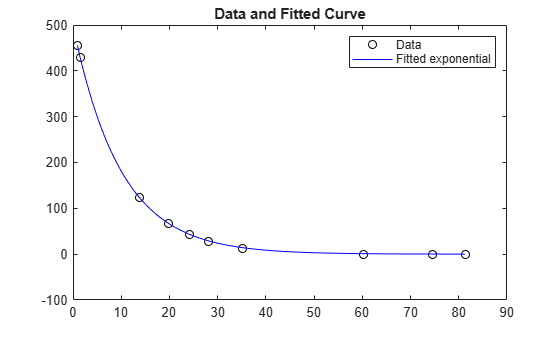
피팅이 좋아 보입니다. 잔차는 얼마나 큽니까?
fprintf(['The ''trust-region-reflective'' algorithm has residual norm %f,\n',... 'and the ''levenberg-marquardt'' algorithm has residual norm %f.\n'],... resnorm,resnorm2)
The 'trust-region-reflective' algorithm has residual norm 9.504887, and the 'levenberg-marquardt' algorithm has residual norm 9.504887.
입력 인수
출력 인수
제한 사항
trust-region-reflective 알고리즘은 부족 결정 시스템을 풀지 않습니다. 이 알고리즘을 사용하려면 방정식 개수, 즉 F의 행 차원이 최소한 변수 개수여야 합니다. 부족 결정 시스템의 경우
lsqcurvefit은 Levenberg-Marquardt 알고리즘을 사용합니다.lsqcurvefit은 복소수 값을 갖는 문제를 직접 풀 수 있습니다. 제약 조건은 복소수 값에 적합하지 않다는 점에 유의하십시오. 복소수는 순서대로 정렬될 수 없기 때문에 한 복소수 값이 다른 복소수 값보다 크거나 작은지 여부를 요구하는 것은 무의미합니다. 범위 제약 조건이 있는 복소수 문제의 경우 변수를 실수부와 허수부로 분리하십시오. 복소수 데이터로'interior-point'알고리즘을 사용하지 마십시오. 복소수 값 데이터에 모델 피팅하기 항목을 참조하십시오.trust-region-reflective 방법의 선조건 적용 켤레 기울기 부분에 사용되는 선조건자 계산은 선조건자를 계산하기 전에 JTJ(여기서 J는 야코비 행렬임)를 형성합니다. 따라서, 0이 아닌 요소를 많이 포함하는 J의 행은 거의 조밀한 곱 JTJ를 생성하며, 이는 대규모 문제에서 비용이 많이 드는 풀이 과정을 초래할 수 있습니다.
x의 성분에 상한(또는 하한)이 없는 경우
lsqcurvefit은 기본적으로ub(또는lb)의 대응하는 성분을 임의적이지만 매우 큰 양수(또는 하한의 경우 음수)로 설정하는 대신inf(또는 하한의 경우-inf)로 설정합니다.
중소 규모 문제에서는 fun에서 야코비 행렬을 계산하거나 야코비 행렬의 희소성 패턴을 제공하지 않고 lsqnonlin, lsqcurvefit, fsolve에 trust-region reflective 알고리즘을 사용할 수 있습니다. 이는 헤세 행렬을 계산하거나 헤세 행렬의 희소성 패턴을 제공하지 않고 fmincon 또는 fminunc를 사용하는 경우에도 적용됩니다. 중소 규모는 얼마나 작은가요? 절대적인 답은 없습니다. 컴퓨터 시스템 구성의 가상 메모리 크기에 따라 달라지기 때문입니다.
문제에 m개의 방정식과 n개의 미지수가 있다고 가정하겠습니다. 명령 J = sparse(ones(m,n))을 실행할 때 컴퓨터에 Out of memory 오류가 발생한다면 이 문제는 확실히 너무 큰 문제입니다. 오류가 발생하지 않은 경우에도 여전히 너무 큰 문제일 수 있습니다. 이를 확인할 수 있는 유일한 방법은 문제를 실행하고 MATLAB이 시스템에서 사용할 수 있는 가상 메모리 크기 내에서 실행되는지 확인하는 것입니다.
세부 정보
함수의 국소 최솟값이란 함수 값이 인근 점에서보다는 더 작지만 멀리 있는 점에서보다는 더 클 수 있는 점을 말합니다.
전역 최솟값이란 함수 값이 다른 모든 실현가능점에서보다 작은 점을 말합니다.

솔버는 국소 최솟값을 구하려고 합니다. 그 결과는 전역 최솟값일 수 있습니다. 자세한 내용은 국소 최적해와 전역 최적해 항목을 참조하십시오.
FunctionTolerance라고 하는 함수 허용오차는 목적 함수 값의 최근 변화량의 크기와 관련이 있습니다.

알고리즘
Levenberg-Marquardt 방법과 trust-region-reflective 방법은 fsolve에도 사용된 동일한 비선형 최소제곱 알고리즘을 기반으로 합니다.
디폴트 trust-region-reflective 알고리즘은 부분공간 trust-region 방법이며 interior-reflective 뉴턴 방법([1] 및 [2]에 설명되어 있음)을 기반으로 합니다. 각 반복에는 선조건 적용 켤레 기울기(PCG) 방법을 사용한 대규모 선형 시스템의 근사해 풀이 작업이 포함됩니다. Trust-Region-Reflective 최소제곱 항목을 참조하십시오.
Levenberg-Marquardt 방법은 참고 문헌 [4], [5], [6]에 설명되어 있습니다. Levenberg-Marquardt 방법 항목을 참조하십시오.
'interior-point' 알고리즘은 몇 가지 수정 사항이 적용된 fmincon 'interior-point' 알고리즘을 사용합니다. 자세한 내용은 제약 조건이 있는 최소제곱에 대해 수정된 fmincon 알고리즘 항목을 참조하십시오.
대체 기능
앱
최적화 라이브 편집기 작업은 lsqcurvefit에 대한 시각적 인터페이스를 제공합니다.
참고 문헌
[1] Coleman, T.F. and Y. Li. “An Interior, Trust Region Approach for Nonlinear Minimization Subject to Bounds.” SIAM Journal on Optimization, Vol. 6, 1996, pp. 418–445.
[2] Coleman, T.F. and Y. Li. “On the Convergence of Reflective Newton Methods for Large-Scale Nonlinear Minimization Subject to Bounds.” Mathematical Programming, Vol. 67, Number 2, 1994, pp. 189–224.
[3] Dennis, J. E. Jr. “Nonlinear Least-Squares.” State of the Art in Numerical Analysis, ed. D. Jacobs, Academic Press, pp. 269–312.
[4] Levenberg, K. “A Method for the Solution of Certain Problems in Least-Squares.” Quarterly Applied Mathematics 2, 1944, pp. 164–168.
[5] Marquardt, D. “An Algorithm for Least-squares Estimation of Nonlinear Parameters.” SIAM Journal Applied Mathematics, Vol. 11, 1963, pp. 431–441.
[6] Moré, J. J. “The Levenberg-Marquardt Algorithm: Implementation and Theory.” Numerical Analysis, ed. G. A. Watson, Lecture Notes in Mathematics 630, Springer Verlag, 1977, pp. 105–116.
[7] Moré, J. J., B. S. Garbow, and K. E. Hillstrom. User Guide for MINPACK 1. Argonne National Laboratory, Rept. ANL–80–74, 1980.
[8] Powell, M. J. D. “A Fortran Subroutine for Solving Systems of Nonlinear Algebraic Equations.” Numerical Methods for Nonlinear Algebraic Equations, P. Rabinowitz, ed., Ch.7, 1970.