이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
fitoptions
fit options 객체 생성 또는 수정
구문
설명
fitOptions = fitoptionsfitOptions를 만듭니다.
fitOptions = fitoptions(libraryModelName)
fitOptions = fitoptions(libraryModelName,Name,Value)Name,Value 쌍의 인수로 지정된 추가 옵션을 사용하여 만듭니다.
fitOptions = fitoptions(fitType)fitType에 대한 fit options 객체를 가져옵니다. 사용자 지정 모델의 피팅 옵션으로 작업하려면 이 구문을 사용하십시오.
fitOptions = fitoptions(Name,Value)Name,Value 쌍의 인수로 지정된 추가 옵션을 사용하여 피팅 옵션을 만듭니다.
newOptions = fitoptions(fitOptions,Name,Value)fitOptions를 수정하여 하나 이상의 Name,Value 쌍의 인수로 지정된 새로운 옵션을 적용하여 업데이트된 피팅 옵션을 newOptions에 반환합니다.
newOptions = fitoptions(options1,options2)options1과 options2를 newOptions로 결합합니다.
Method가 동일한 경우options2의 속성에 비어 있지 않은 값이 있으면options1의 대응하는 속성값이 재정의되어newOptions로 반환됩니다.Method가 다른 경우newOptions는Method에 대해서는options1의 값을,Normalize,Exclude,Weights에 대해서는options2의 값을 포함합니다.
예제
디폴트 fit options 객체를 만들고 피팅 전에 데이터를 정규화하도록 옵션을 설정합니다.
options = fitoptions;
options.Normal = 'on'options =
basefitoptions with properties:
Normalize: 'on'
Exclude: []
Weights: []
Method: 'None'
options = fitoptions('gauss2')options =
nlsqoptions with properties:
StartPoint: []
Algorithm: 'Trust-Region'
DiffMinChange: 1.0000e-08
DiffMaxChange: 0.1000
Display: 'Notify'
MaxFunEvals: 600
MaxIter: 400
TolFun: 1.0000e-06
TolX: 1.0000e-06
Lower: [-Inf -Inf 0 -Inf -Inf 0]
Upper: []
ConstraintPoints: []
TolCon: 1.0000e-06
Robust: 'Off'
Normalize: 'off'
Exclude: []
Weights: []
Method: 'NonlinearLeastSquares'
3차 다항식에 대한 피팅 옵션을 만들고 정규화 옵션과 로버스트 옵션을 설정합니다.
options = fitoptions('poly3', 'Normalize', 'on', 'Robust', 'Bisquare')
options =
llsqoptions with properties:
Lower: []
Upper: []
ConstraintPoints: []
TolCon: 1.0000e-06
Robust: 'Bisquare'
Normalize: 'on'
Exclude: []
Weights: []
Method: 'LinearLeastSquares'
options = fitoptions('Method', 'LinearLeastSquares')
options =
llsqoptions with properties:
Lower: []
Upper: []
ConstraintPoints: []
TolCon: 1.0000e-06
Robust: 'Off'
Normalize: 'off'
Exclude: []
Weights: []
Method: 'LinearLeastSquares'
최근접이웃 외삽으로 선형 보간에 대한 fitoptions 객체를 만듭니다.
linearoptions = fitoptions("linearinterp",ExtrapolationMethod="nearest")
linearoptions =
linearinterpoptions with properties:
ExtrapolationMethod: 'nearest'
Normalize: 'off'
Exclude: []
Weights: []
Method: 'LinearInterpolant'
최근접이웃 외삽으로 3차 보간 피팅에 대한 두 번째 fitoptions 객체를 만듭니다.
cubicoptions = fitoptions("cubicinterp",ExtrapolationMethod="nearest")
cubicoptions =
cubicsplineinterpoptions with properties:
ExtrapolationMethod: 'nearest'
Normalize: 'off'
Exclude: []
Weights: []
Method: 'CubicSplineInterpolant'
fit 함수를 사용하여 linearinterp 피팅 객체를 만들기 위해 linearoptions에 있는 피팅 옵션을 사용할 수 있습니다. cubicinterp 피팅을 만들려면 cubicoptions를 사용합니다.
Normalize, Exclude 또는 Weights 속성을 설정한 후 다른 피팅 방법에서 동일한 옵션을 사용하여 데이터를 피팅하려는 경우 디폴트 fit options 객체를 수정하는 것이 유용합니다. 예를 들어, 아래에서는 동일한 피팅 옵션을 사용하여 여러 라이브러리 모델 유형을 피팅합니다.
load census options = fitoptions; options.Normalize = 'on'; f1 = fit(cdate,pop,'poly3',options); f2 = fit(cdate,pop,'exp1',options); f3 = fit(cdate,pop,'cubicspline',options)
f3 =
Cubic interpolating spline:
f3(x) = piecewise polynomial computed from p
with cubic extrapolation
where x is normalized by mean 1890 and std 62.05
Coefficients:
p = coefficient structure
평활화 파라미터를 찾습니다. fit 함수의 세 번째 출력 인수로 데이터 관련 피팅 옵션(예: smooth 파라미터)이 반환됩니다.
load census [f,gof,out] = fit(cdate,pop,'SmoothingSpline'); smoothparam = out.p
smoothparam = 0.0089
새 피팅을 위해 디폴트 평활화 파라미터를 수정합니다.
options = fitoptions('Method','SmoothingSpline',... 'SmoothingParam',0.0098); [f,gof,out] = fit(cdate,pop,'SmoothingSpline',options);
가우스 피팅을 만들고, 신뢰구간을 조사하고, 알고리즘에 도움이 되도록 하한 피팅 옵션을 지정합니다.
하나는 너비가 작고 다른 하나는 너비가 큰 두 개의 가우스 피크를 합하여 잡음을 만듭니다.
a1 = 1; b1 = -1; c1 = 0.05; a2 = 1; b2 = 1; c2 = 50; x = (-10:0.02:10)'; gdata = a1*exp(-((x-b1)/c1).^2) + ... a2*exp(-((x-b2)/c2).^2) + ... 0.1*(rand(size(x))-.5); plot(x,gdata)
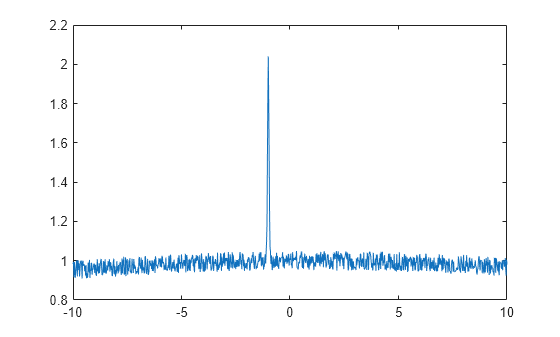
2항 가우스 라이브러리 모델을 사용하여 데이터를 피팅합니다.
gfit = fit(x,gdata,'gauss2') gfit =
General model Gauss2:
gfit(x) = a1*exp(-((x-b1)/c1)^2) + a2*exp(-((x-b2)/c2)^2)
Coefficients (with 95% confidence bounds):
a1 = -0.1451 (-1.485, 1.195)
b1 = 9.725 (-14.7, 34.15)
c1 = 7.117 (-15.84, 30.07)
a2 = 14.08 (-1.962e+04, 1.965e+04)
b2 = 607.4 (-3.197e+05, 3.209e+05)
c2 = 376 (-9.745e+04, 9.82e+04)
plot(gfit,x,gdata)

여러 계수의 신뢰구간이 넓어 알고리즘이 문제를 겪고 있습니다.
알고리즘에 도움이 되도록 하려면 음이 아닌 진폭 a1, a2와 너비 c1, c2에 대해 하한을 지정하십시오.
options = fitoptions('gauss2', 'Lower', [0 -Inf 0 0 -Inf 0]);
또는 options.Property = NewPropertyValue 형식을 사용하여 피팅 옵션의 속성을 설정할 수도 있습니다.
options = fitoptions('gauss2');
options.Lower = [0 -Inf 0 0 -Inf 0];계수에 대한 한계값 제약 조건을 사용하여 피팅을 다시 계산합니다.
gfit = fit(x,gdata,'gauss2',options) gfit =
General model Gauss2:
gfit(x) = a1*exp(-((x-b1)/c1)^2) + a2*exp(-((x-b2)/c2)^2)
Coefficients (with 95% confidence bounds):
a1 = 1.005 (0.966, 1.044)
b1 = -1 (-1.002, -0.9988)
c1 = 0.0491 (0.0469, 0.0513)
a2 = 0.9985 (0.9958, 1.001)
b2 = 0.8059 (0.3879, 1.224)
c2 = 50.6 (46.68, 54.52)
plot(gfit,x,gdata)
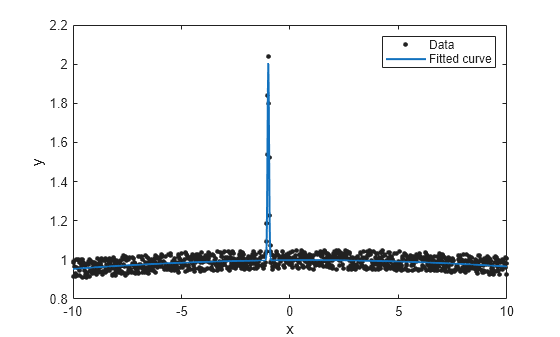
피팅이 훨씬 더 나아졌습니다. fit options 객체의 다른 속성에 합리적인 값을 할당하여 피팅을 더 개선할 수 있습니다.
피팅 옵션을 만들고 하한을 설정합니다.
options = fitoptions('gauss2', 'Lower', [0 -Inf 0 0 -Inf 0])
options =
nlsqoptions with properties:
StartPoint: []
Algorithm: 'Trust-Region'
DiffMinChange: 1.0000e-08
DiffMaxChange: 0.1000
Display: 'Notify'
MaxFunEvals: 600
MaxIter: 400
TolFun: 1.0000e-06
TolX: 1.0000e-06
Lower: [0 -Inf 0 0 -Inf 0]
Upper: []
ConstraintPoints: []
TolCon: 1.0000e-06
Robust: 'Off'
Normalize: 'off'
Exclude: []
Weights: []
Method: 'NonlinearLeastSquares'
피팅 옵션의 새 복사본을 만들고 로버스트 파라미터를 수정합니다.
newoptions = fitoptions(options, 'Robust','Bisquare')
newoptions =
nlsqoptions with properties:
StartPoint: []
Algorithm: 'Trust-Region'
DiffMinChange: 1.0000e-08
DiffMaxChange: 0.1000
Display: 'Notify'
MaxFunEvals: 600
MaxIter: 400
TolFun: 1.0000e-06
TolX: 1.0000e-06
Lower: [0 -Inf 0 0 -Inf 0]
Upper: []
ConstraintPoints: []
TolCon: 1.0000e-06
Robust: 'Bisquare'
Normalize: 'off'
Exclude: []
Weights: []
Method: 'NonlinearLeastSquares'
피팅 옵션을 결합합니다.
options2 = fitoptions(options, newoptions)
options2 =
nlsqoptions with properties:
StartPoint: []
Algorithm: 'Trust-Region'
DiffMinChange: 1.0000e-08
DiffMaxChange: 0.1000
Display: 'Notify'
MaxFunEvals: 600
MaxIter: 400
TolFun: 1.0000e-06
TolX: 1.0000e-06
Lower: [0 -Inf 0 0 -Inf 0]
Upper: []
ConstraintPoints: []
TolCon: 1.0000e-06
Robust: 'Bisquare'
Normalize: 'off'
Exclude: []
Weights: []
Method: 'NonlinearLeastSquares'
선형 모델 피팅 유형을 만듭니다.
lft = fittype({'x','sin(x)','1'})lft =
Linear model:
lft(a,b,c,x) = a*x + b*sin(x) + c
피팅 유형 lft에 대한 피팅 옵션을 가져옵니다.
fo = fitoptions(lft)
fo =
llsqoptions with properties:
Lower: []
Upper: []
ConstraintPoints: []
TolCon: 1.0000e-06
Robust: 'Off'
Normalize: 'off'
Exclude: []
Weights: []
Method: 'LinearLeastSquares'
정규화 피팅 옵션을 설정합니다.
fo.Normalize = 'on'fo =
llsqoptions with properties:
Lower: []
Upper: []
ConstraintPoints: []
TolCon: 1.0000e-06
Robust: 'Off'
Normalize: 'on'
Exclude: []
Weights: []
Method: 'LinearLeastSquares'