이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
곡선 피팅 및 분포 피팅
이 예제에서는 곡선 피팅 및 분포 피팅을 수행하는 방법을 보여주고 각 방법을 사용하는 것이 적절한 경우에 대해 설명합니다.
곡선 피팅과 분포 피팅 중 선택하기
곡선 피팅과 분포 피팅은 서로 다른 데이터 분석 유형입니다.
예측 변수의 함수로 응답 변수를 모델링하려면 곡선 피팅을 사용하십시오.
단일 변수의 확률 분포를 모델링하려면 분포 피팅을 사용하십시오.
곡선 피팅
다음 실험 데이터에서 예측 변수는 약물을 복용한 후의 시간인 time입니다. 응답 변수는 혈류 내 약물 농도인 conc입니다. 응답 변수 데이터 conc만 실험 오차의 영향을 받는 것으로 가정합니다.
time = [ 0.1 0.1 0.3 0.3 1.3 1.7 2.1 2.6 3.9 3.9 ... 5.1 5.6 6.2 6.4 7.7 8.1 8.2 8.9 9.0 9.5 ... 9.6 10.2 10.3 10.8 11.2 11.2 11.2 11.7 12.1 12.3 ... 12.3 13.1 13.2 13.4 13.7 14.0 14.3 15.4 16.1 16.1 ... 16.4 16.4 16.7 16.7 17.5 17.6 18.1 18.5 19.3 19.7]'; conc = [0.01 0.08 0.13 0.16 0.55 0.90 1.11 1.62 1.79 1.59 ... 1.83 1.68 2.09 2.17 2.66 2.08 2.26 1.65 1.70 2.39 ... 2.08 2.02 1.65 1.96 1.91 1.30 1.62 1.57 1.32 1.56 ... 1.36 1.05 1.29 1.32 1.20 1.10 0.88 0.63 0.69 0.69 ... 0.49 0.53 0.42 0.48 0.41 0.27 0.36 0.33 0.17 0.20]';
혈액 농도를 시간의 함수로 모델링하고자 한다고 가정하겠습니다. time에 대해 conc를 플로팅합니다.
plot(time,conc,'o'); xlabel('Time'); ylabel('Blood Concentration');

conc는 time의 함수로서 2-모수 베이불 곡선을 따른다고 가정합니다. 베이불 곡선은 다음과 같은 형식과 모수를 갖습니다.
여기서 는 가로 스케일링이고 는 형태 모수이고 는 세로 스케일링입니다.
비선형 최소제곱을 사용하여 베이불 모델을 피팅합니다.
modelFun = @(p,x) p(3) .* (x./p(1)).^(p(2)-1) .* exp(-(x./p(1)).^p(2)); startingVals = [10 2 5]; nlModel = fitnlm(time,conc,modelFun,startingVals);
데이터 위에 베이불 곡선을 플로팅합니다.
xgrid = linspace(0,20,100)'; line(xgrid,predict(nlModel,xgrid),'Color','r');

피팅된 베이불 모델에는 문제가 있습니다. fitnlm은 실험 오차가 가산적이며 일정한 분산을 갖는 대칭 분포에서 추출된 것으로 가정합니다. 그러나 산점도 플롯은 오차 분산이 곡선의 높이에 비례함을 보여줍니다. 또한, 가산성 대칭 오차는 음의 혈액 농도 측정값이 가능함을 암시합니다.
로그 스케일에서 대칭인 승산식 오차를 가정하는 것이 더 현실적입니다. 이 가정을 바탕으로, 양쪽 모두에 대해 로그 연산을 수행하여 데이터에 베이불 곡선을 피팅합니다. 다음과 같이 비선형 최소제곱을 사용하여 곡선을 피팅합니다.
nlModel2 = fitnlm(time,log(conc),@(p,x) log(modelFun(p,x)),startingVals);
기존 플롯에 새 곡선을 추가합니다.
line(xgrid,exp(predict(nlModel2,xgrid)),'Color',[0 .5 0],'LineStyle','--'); legend({'Raw Data','Additive Errors Model','Multiplicative Errors Model'});
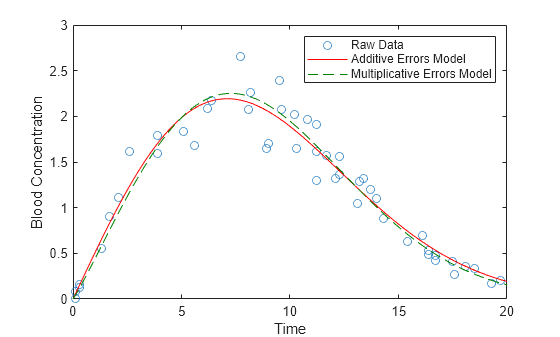
모델 객체 nlModel2는 정밀도에 대한 추정값을 포함합니다. 모델의 피팅 적합도를 확인하는 것이 가장 좋습니다. 예를 들어, 로그 스케일에서 잔차 플롯을 생성하여 승산식 오차의 분산이 일정하다는 가정을 확인합니다.
이 예제에서는 승산식 오차 모델을 사용한 것이 모델의 예측에 큰 영향을 주지 않았습니다. 모델의 유형이 보다 큰 영향을 미치는 예제는 Pitfalls in Fitting Nonlinear Models by Transforming to Linearity 항목을 참조하십시오.
곡선 피팅을 위한 함수
Statistics and Machine Learning Toolbox™에는 비선형 최소제곱 모델을 위한
fitnlm함수, 일반화 선형 모델을 위한fitglm함수, 가우스 과정 회귀 모델을 위한fitrgp함수, 서포트 벡터 머신 회귀 모델을 위한fitrsvm함수 등 모델 피팅을 위한 함수가 포함되어 있습니다.Curve Fitting Toolbox™는 곡선 피팅의 작업을 간소화하는 명령줄과 그래픽 툴을 제공합니다. 예를 들어, 로버스트 피팅과 비모수적 피팅뿐 아니라 다양한 모델에서 시작 계수 값을 자동 선택하는 기능을 제공합니다.
Optimization Toolbox™에는 계수에 대한 제약 조건이 있는 모델을 분석하는 등 복잡한 유형의 곡선 피팅 분석을 수행하기 위한 함수가 포함되어 있습니다.
MATLAB® 함수
polyfit은 다항식 모델을 피팅하고, MATLAB 함수fminsearch는 다른 종류의 곡선 피팅에 유용합니다.
분포 피팅
전기 부품의 수명 분포를 모델링하고자 한다고 가정하겠습니다. 변수 life는 50개의 동일한 전기 부품에 대한 고장 수명을 측정합니다.
life = [ 6.2 16.1 16.3 19.0 12.2 8.1 8.8 5.9 7.3 8.2 ... 16.1 12.8 9.8 11.3 5.1 10.8 6.7 1.2 8.3 2.3 ... 4.3 2.9 14.8 4.6 3.1 13.6 14.5 5.2 5.7 6.5 ... 5.3 6.4 3.5 11.4 9.3 12.4 18.3 15.9 4.0 10.4 ... 8.7 3.0 12.1 3.9 6.5 3.4 8.5 0.9 9.9 7.9]';
히스토그램을 사용하여 데이터를 시각화합니다.
binWidth = 2; lastVal = ceil(max(life)); binEdges = 0:binWidth:lastVal+1; h = histogram(life,binEdges); xlabel('Time to Failure'); ylabel('Frequency'); ylim([0 10]);
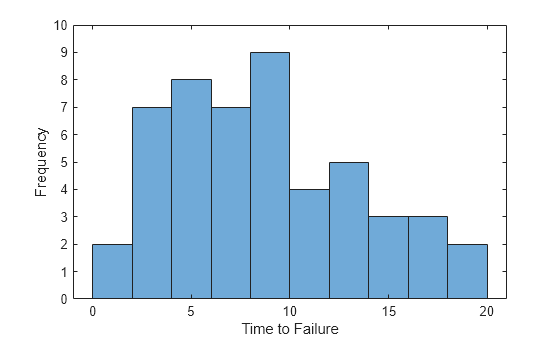
수명 데이터는 대개 베이불 분포를 따르므로, 위의 곡선 피팅 예제에서 설명한 베이불 곡선을 사용하여 히스토그램을 피팅하는 것이 한 가지 방법이 될 수 있습니다. 이 방법을 사용해 보기 위해, 히스토그램을 x가 Bin 중심값이고 y가 Bin 높이인 일련의 점 (x, y)로 변환한 다음 이 점들에 곡선을 피팅합니다.
counts = histcounts(life,binEdges); binCtrs = binEdges(1:end-1) + binWidth/2; h.FaceColor = [.9 .9 .9]; hold on plot(binCtrs,counts,'o'); hold off

하지만 곡선을 히스토그램에 피팅할 경우 몇 가지 문제가 발생할 가능성이 있으므로 일반적으로는 권장되지 않습니다.
이 과정은 최소제곱 피팅에 대한 기본 가정을 위반합니다. Bin 도수가 음이 아니며, 이는 계측 오차가 대칭이 될 수 없음을 의미합니다. 뿐만 아니라, 분포의 중앙부와 꼬리에서 Bin 도수의 변동성이 다릅니다. 또한 Bin 도수가 고정된 합을 가지며, 이는 독립적인 측정값이 아님을 의미합니다.
히스토그램이 경험적 확률 밀도 함수(pdf)의 스케일링된 버전이므로 베이불 곡선을 막대 높이에 피팅하려면 곡선에 제약 조건을 적용해야 합니다.
연속 데이터의 경우, 데이터가 아니라 히스토그램에 곡선을 피팅하면 정보가 버려집니다.
히스토그램의 막대 높이는 Bin 경계값과 Bin 너비의 선택에 따라 달라집니다.
많은 경우 모수 분포에서는 최대가능도를 사용하여 모수를 추정하는 것이 이러한 문제를 방지하기 때문에 훨씬 효과적입니다. 베이불 pdf의 형식은 베이불 곡선과 거의 동일합니다.
하지만 함수가 1로 적분되어야 하므로 가 스케일 모수 를 대체합니다. 최대가능도를 사용하여 데이터에 베이불 분포를 피팅하려면 fitdist를 사용하고 분포 이름으로 'Weibull'을 지정하십시오. 최대가능도는 최소제곱법과 달리 베이불 pdf와 막대 높이 사이의 제곱 차이 합을 최소화하지 않으면서 스케일링된 히스토그램과 가장 잘 맞는 베이불 pdf를 구합니다.
pd = fitdist(life,'Weibull');데이터에 대한 스케일링된 히스토그램을 플로팅한 다음 피팅된 pdf를 겹쳐 놓습니다.
h = histogram(life,binEdges,'Normalization','pdf','FaceColor',[.9 .9 .9]); xlabel('Time to Failure'); ylabel('Probability Density'); ylim([0 0.1]); xgrid = linspace(0,20,100)'; pdfEst = pdf(pd,xgrid); line(xgrid,pdfEst)

모델의 피팅 적합도를 확인하는 것이 가장 좋습니다.
히스토그램에 곡선을 피팅하는 것은 일반적으로 권장되지 않지만 이 과정이 적절한 경우가 있습니다. 예제는 Fit Custom Distributions 항목을 참조하십시오.
분포 피팅을 위한 함수
Statistics and Machine Learning Toolbox™에는 데이터에 확률 분포 객체를 피팅하기 위한 함수
fitdist가 포함되어 있습니다. 또한, 최대가능도를 사용하여 모수 분포를 피팅하기 위한 함수(예:wblfit), 정해진 피팅 함수 없이 사용자 지정 분포를 피팅하기 위한 함수mle, 데이터에 비모수 분포를 피팅하기 위한 함수ksdensity도 포함되어 있습니다.Statistics and Machine Learning Toolbox는 시각화 및 진단 플롯의 생성 등 분포 피팅의 다양한 작업을 간소화하는 분포 피팅기 앱도 제공합니다.
모수에 대한 제약 조건이 있는 분포를 포함하여 복잡한 분포를 Optimization Toolbox™에서 제공되는 함수를 사용하여 피팅할 수 있습니다.
MATLAB® 함수
fminsearch는 최대가능도 분포 피팅을 제공합니다.
참고 항목
fitnlm | fitglm | fitrgp | fitrsvm | polyfit | fminsearch | fitdist | mle | ksdensity | 분포 피팅기