그리딩된 데이터 보간하기
그리딩된 데이터는 그리드를 구성하는 균일한 간격의 점에서 측정된 값 또는 기타 값으로 구성됩니다. 그리딩된 데이터는 기상학, 측량, 의료 영상 처리 등 다양한 분야에서 발생합니다. 이러한 분야에서는 주로 규칙적인 간격으로 측정이 이루어지며, 이는 시간에 따른 측정일 수 있습니다. 순서가 지정된 이러한 데이터 그리드는 1차원(단순 시계열의 경우)에서 4차원(시간에 따른 볼륨 측정의 경우) 또는 그 이상일 수 있습니다. 다음은 그리딩된 데이터의 몇 가지 예입니다.
1차원: 시간에 따른 주가
2차원: 곡면의 온도
3차원: 뇌 MRI 영상
4차원: 시간에 따른 해수 부피의 측정값
이러한 모든 응용 분야에서 그리드 기반 보간을 활용하면 유용한 데이터를 아무런 값이 측정되지 않은 점에도 효율적으로 확대 적용할 수 있습니다. 예를 들어, 시간별 주가 데이터가 있는 경우 보간을 사용하여 매 15분의 주가 근삿값을 계산할 수 있습니다.
MATLAB의 그리딩된 보간 함수
MATLAB®은 그리드 기반 보간을 수행하기 위한 몇 가지 툴을 제공합니다.
그리드 생성 함수
meshgrid와 ndgrid 함수는 다양한 차원의 그리드를 만듭니다. meshgrid는 2차원 또는 3차원 그리드를 만들 수 있고, ndgrid는 임의의 차원 수로 그리드를 만들 수 있습니다. 이러한 함수는 서로 다른 출력 형식을 사용하여 그리드를 반환합니다. 이들 그리드 형식은 pagetranspose(R2020b 이상) 또는 permute 함수를 사용하여 그리드의 처음 두 차원을 맞바꿈으로써 변환할 수 있습니다.
보간 함수
interp 함수군에는 interp1, interp2, interp3, interpn이 포함됩니다. 각 함수는 특정 차원 수에서 데이터를 보간하도록 설계되었습니다. interp2와 interp3은 meshgrid 형식의 그리드를 사용하고, interpn은 ndgrid 형식의 그리드를 사용합니다.
Interpolation 객체
griddedInterpolant 객체를 사용하면 ndgrid 형식의 데이터를 임의의 차원 수에서 보간할 수 있습니다. 이 객체는 다중 값 보간도 지원하며(R2021a부터), 이 경우 각 그리드 점에 여러 개의 값을 연결할 수 있습니다.
interp 함수보다 griddedInterpolant 객체를 사용하면 메모리와 성능 면에서 이점이 있습니다. griddedInterpolant는 interpolant 객체를 반복 쿼리할 때 성능을 크게 높이는 반면, interp 함수는 호출될 때마다 새로 계산을 수행합니다. 또한 griddedInterpolant는 샘플 점을 메모리 효율적인 형식(예: 간소 그리드)으로 저장하고, 멀티코어 컴퓨터 프로세서를 활용하도록 멀티스레딩됩니다.
그리드 표현
MATLAB에서는 그리드를 전체 그리드, 간소 그리드, 디폴트 그리드의 세 가지 표현 중 하나로 나타낼 수 있습니다. 디폴트 그리드와 간소 그리드는 주로 간편함과 효율성을 높일 목적으로 각각 사용됩니다.
전체 그리드
전체 그리드는 모든 점이 명시적으로 정의된 그리드입니다. ndgrid와 meshgrid의 출력값은 전체 그리드를 정의합니다. 전체 그리드는 각 차원의 점이 동일한 간격으로 지정되는 균일 그리드로 만들거나, 간격이 하나 이상의 차원에서 달라지는 비균일 그리드로 만들 수 있습니다. 균일 그리드는 각 차원 내에서의 간격이 균일하며, 차원마다의 간격은 같지 않아도 됩니다.
| 균일 | 균일 | 비균일 |
|---|---|---|
|
|
|



다음은 균일한 전체 그리드의 예입니다.
[X,Y] = meshgrid([1 2 3],[3 6 9 12])
X =
1 2 3
1 2 3
1 2 3
1 2 3
Y =
3 3 3
6 6 6
9 9 9
12 12 12간소 그리드
그리드의 모든 점을 명시적으로 정의하면 대형 그리드를 처리할 때 메모리 소모가 클 수 있습니다. 간소 그리드 표현은 전체 그리드의 메모리 오버헤드를 없앨 수 있는 한 방법입니다. 간소 그리드 표현에서는 전체 그리드 대신 그리드 벡터(차원마다 한 개씩)만 저장합니다. 동시에 그리드 벡터는 묵시적으로 그리드를 정의합니다. 사실상 meshgrid 및 ndgrid에 대한 입력값이 그리드 벡터이고, 이러한 함수는 그리드 벡터를 복제하여 전체 그리드를 만듭니다. 간소 그리드 표현을 사용하면 그리드 생성을 건너뛰고 그리드 벡터를 보간 함수에 바로 제공할 수 있습니다.
예를 들어, 두 개의 벡터 x1 = 1:3과 x2 = 1:5가 있다고 가정해 보겠습니다. 다음과 같이 이러한 벡터를 x1 방향의 좌표의 집합과 x2 방향의 좌표의 집합으로 생각해 볼 수 있습니다.
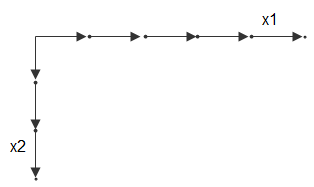
각 화살표는 위치를 가리킵니다. 이러한 두 벡터를 사용하여 그리드 점 집합을 정의할 수 있습니다. 여기서 한 좌표 집합은 x1에 의해 지정되고 다른 좌표 집합은 x2에 의해 지정됩니다. 그리드 벡터를 복제할 경우 이들은 전체 그리드를 구성하는 두 개의 좌표 배열을 형성합니다.
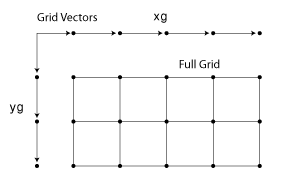
입력 그리드 벡터는 단조적이거나 비단조적일 수 있습니다. 단조 벡터는 해당 차원에서 증가하거나 감소하는 값을 포함합니다. 반대로, 비단조 벡터는 오르내리는 값을 포함합니다. [2 4 6 3 1]과 같이 입력 그리드 벡터가 비단조적이면 [X1,X2] = ndgrid([2 4 6 3 1])은 비단조적 그리드를 출력합니다. 그리드를 다른 MATLAB 함수에 전달하려는 경우 그리드 벡터는 단조적이어야 합니다. sort 함수는 단조성을 보장하는 데 유용합니다.
디폴트 그리드
일부 응용 분야에서는 그리드 점 간의 거리가 아닌 그리드 점에서의 값만 중요한 경우가 있습니다. 예를 들어, 대부분의 MRI 검사에서는 모든 방향에서 간격이 균일한 데이터를 수집합니다. 이 같은 경우에는 보간 함수가 데이터에 사용할 디폴트 그리드 표현을 자동으로 생성하도록 허용할 수 있습니다. 이렇게 하려면 보간 함수에 대한 그리드 입력값을 생략하십시오. 그리드 입력값을 생략하면 보간 함수는 데이터가 자동으로 단위 간격의 그리드에 위치할 것이라고 간주합니다. 실행 시 보간 함수가 이 단위 간격의 그리드를 생성하기 때문에, 직접 그리드를 생성해야 하는 수고를 덜게 됩니다.
예제: 2차원 그리드에 대한 온도 보간
곡면에서 5cm의 규칙적인 간격으로 각 방향의 20cm 영역에서 온도 데이터를 수집했다고 가정하겠습니다. meshgrid를 사용하여 전체 그리드를 만듭니다.
[X,Y] = meshgrid(0:5:20)
X =
0 5 10 15 20
0 5 10 15 20
0 5 10 15 20
0 5 10 15 20
0 5 10 15 20
Y =
0 0 0 0 0
5 5 5 5 5
10 10 10 10 10
15 15 15 15 15
20 20 20 20 20각 그리드 점의 (x,y) 좌표는 X와 Y 행렬의 대응 요소로 표현됩니다. 첫 번째 그리드 점은 [X(1) Y(1)]로 지정되어 [0 0]이 되고, 그다음 그리드 점은 [X(2) Y(2)]로 지정되어 [0 5]가 되는 식입니다.
이제 그리드에 온도 측정값을 표현하기 위한 행렬을 만든 다음 데이터를 곡면으로 플로팅합니다.
T = [1 1 10 1 1;
1 10 10 10 10;
100 100 1000 100 100;
10 10 10 10 1;
1 1 10 1 1];
surf(X,Y,T)
view(2)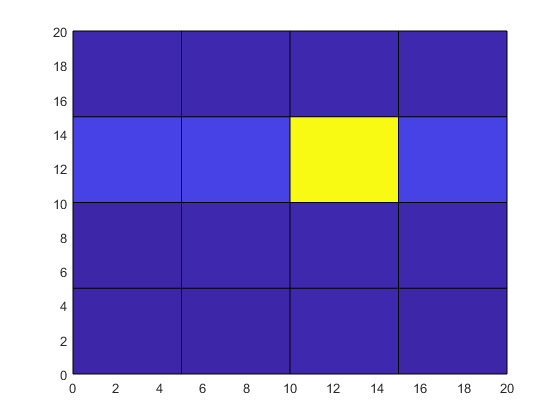
중앙에 있는 그리드 점의 온도가 높지만, 그 위치와 주변 그리드 점에 미치는 영향이 원시 데이터에서 분명히 드러나지 않습니다.
데이터 해상도를 10배로 높이기 위해, interp2를 사용하여 0.5cm 간격의 미세 그리드로 온도 데이터를 보간합니다. 다시 meshgrid를 사용하여, 행렬 Xq와 Yq로 표현되는 미세 그리드를 만듭니다. 그런 다음 interp2에 원래 그리드, 온도 데이터, 새 그리드 점을 사용하고 그 결과로 만들어진 데이터를 플로팅합니다. 기본적으로, interp2는 각 차원에 선형 보간을 사용합니다.
[Xq,Yq] = meshgrid(0:0.5:20); Tq = interp2(X,Y,T,Xq,Yq); surf(Xq,Yq,Tq) view(2)
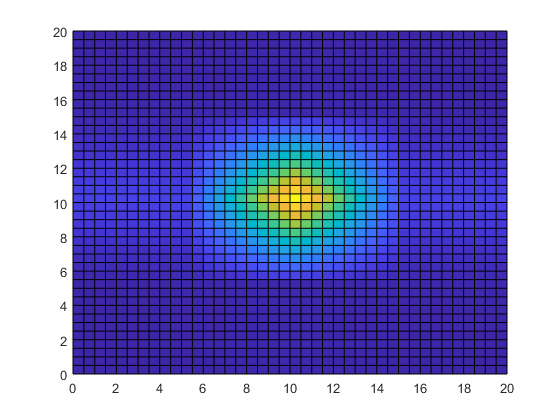
온도 데이터를 보간하면 이미지에 세부 정보를 추가하고, 측정값 영역 내의 데이터를 더 유용하게 사용할 수 있습니다.
그리딩된 보간 방법
MATLAB의 그리드 기반 보간 함수와 객체는 여러 가지 보간 방법을 제공합니다. 보간 방법을 선택할 때는 보간 방법에 따라 메모리 사용량이 더 많거나 계산 시간이 더 길어질 수 있다는 것에 유의하십시오. 원하는 매끄러운 결과를 얻으려면 이러한 리소스 요구 사항을 절충해야 할 수 있습니다. 다음 표에는 동일한 1차원 데이터에 각 보간 방법을 적용한 미리보기가 나와 있고, 각 보간 방법의 장단점과 요구 사항이 간략히 설명되어 있습니다.
| 방법 | 설명 |
|---|---|
|
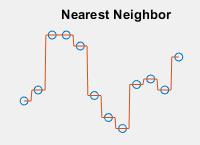
| 쿼리 점에서 보간된 값은 가장 근접한 샘플 그리드 점에서의 값입니다.
|
|
| 쿼리 점에서 보간된 값은 그다음 샘플 그리드 점에서의 값입니다.
|
|
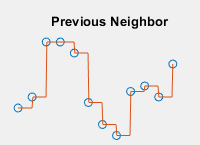
| 쿼리 점에서 보간된 값은 이전 샘플 그리드 점에서의 값입니다.
|
|
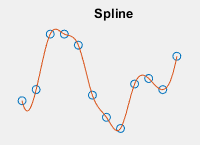
| 쿼리 점에서 보간된 값은 각 차원의 인접 그리드 점에서 값이 선형 보간된 것입니다.
|
|
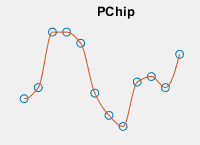
| 쿼리 점에서 보간된 값은 인접 그리드 점에서 값이 형태 보존 조각별 3차 보간된 것입니다.
|
|
| 쿼리 점에서 보간된 값은 각 차원의 인접 그리드 점에서 값이 3차 보간된 것입니다.
|
|
| 쿼리 점에서 보간된 값은 각 차원의 인접 그리드 점 값을 사용하여 계산된, 차수가 최대 3인 다항식의 조각별 함수를 기반으로 합니다. 오버슈트를 방지하도록 아키마 수식이 수정되었습니다.
|
|
| 쿼리 점에서 보간된 값은 각 차원의 인접 그리드 점에서 값이 3차 보간된 것입니다.
|




참고 항목
interp1 | interp2 | interp3 | interpn | griddedInterpolant