이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
gmdistribution
가우스 혼합 모델 생성
설명
gmdistribution 객체는 다변량 가우스 분포 성분으로 구성된 다변량 분포인 가우스 혼합 분포(가우스 혼합 모델 또는 GMM이라고도 함)를 저장합니다. 각 성분은 자체의 평균과 공분산으로 정의됩니다. 혼합은 혼합 비율로 구성된 벡터로 정의됩니다. 여기서 각 혼합 비율은 해당 성분을 설명하는 모집단 비율입니다.
생성
다음 두 가지 방법으로 gmdistribution 모델 객체를 생성할 수 있습니다.
여기서 다루는
gmdistribution함수를 사용하여 분포 모수를 지정하여gmdistribution모델 객체를 생성합니다.fitgmdist함수를 사용해, 고정된 개수의 성분이 주어진 경우에gmdistribution모델 객체를 데이터에 피팅합니다.
설명
입력 인수
속성
객체 함수
예제
gmdistribution 함수를 사용하여 두 개의 성분을 갖는 이변량 가우스 혼합 분포를 생성합니다.
두 개의 이변량 가우스 혼합 성분으로 구성된 분포 모수(평균 및 공분산)를 정의합니다.
mu = [1 2;-3 -5];
sigma = cat(3,[2 .5],[1 1]) % 1-by-2-by-2 arraysigma =
sigma(:,:,1) =
2.0000 0.5000
sigma(:,:,2) =
1 1
cat 함수는 세 번째 배열 차원을 따라 공분산을 결합합니다. 정의된 공분산 행렬은 대각 행렬입니다. sigma(1,:,i)는 성분 i의 공분산 행렬의 대각선 요소를 포함합니다.
gmdistribution 객체를 생성합니다. 기본적으로, gmdistribution 함수는 성분의 비율이 동일하도록 혼합합니다.
gm = gmdistribution(mu,sigma)
gm = Gaussian mixture distribution with 2 components in 2 dimensions Component 1: Mixing proportion: 0.500000 Mean: 1 2 Component 2: Mixing proportion: 0.500000 Mean: -3 -5
gm 객체의 속성을 나열합니다.
properties(gm)
Properties for class gmdistribution:
NumVariables
DistributionName
NumComponents
ComponentProportion
SharedCovariance
NumIterations
RegularizationValue
NegativeLogLikelihood
CovarianceType
mu
Sigma
AIC
BIC
Converged
ProbabilityTolerance
점 표기법을 사용하여 이러한 속성에 액세스할 수 있습니다. 예를 들어, 혼합 성분의 혼합 비율을 나타내는 ComponentProportion 속성에 액세스해 보겠습니다.
gm.ComponentProportion
ans = 1×2
0.5000 0.5000
gmdistribution 객체에는 피팅된 객체에만 적용되는 속성이 있습니다. 피팅된 객체 속성은 AIC, BIC, Converged, NegativeLogLikelihood, NumIterations, ProbabilityTolerance 및 RegularizationValue입니다. gmdistribution 함수를 사용하고 분포 모수를 지정하여 객체를 생성하는 경우 피팅된 객체 속성의 값은 비어 있습니다. 예를 들어, 점 표기법을 사용하여 NegativeLogLikelihood 속성에 액세스해 보십시오.
gm.NegativeLogLikelihood
ans =
[]
gmdistribution 객체를 생성한 후에는 객체 함수를 사용할 수 있습니다. 누적 분포 함수(cdf) 및 확률 밀도 함수(pdf)의 값을 계산하려면 cdf 및 pdf를 사용하십시오. 확률 벡터를 생성하려면 random을 사용하십시오. 군집 분석을 수행하려면 cluster, mahal, posterior를 사용하십시오.
gmPDF = @(x,y) arrayfun(@(x0,y0) pdf(gm,[x0 y0]),x,y); fsurf(gmPDF,[-10 10])
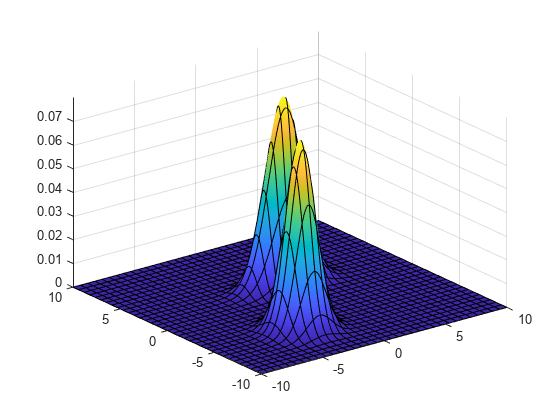
mvnrnd 함수를 사용하여 두 개의 혼합된 이변량 가우스 분포를 따르는 확률 변량을 생성합니다. fitgmdist 함수를 사용하여 가우스 혼합 모델(GMM)을 생성된 데이터에 피팅합니다.
두 개의 이변량 가우스 혼합 성분으로 구성된 분포 모수(평균 및 공분산)를 정의합니다.
mu1 = [1 2]; % Mean of the 1st component sigma1 = [2 0; 0 .5]; % Covariance of the 1st component mu2 = [-3 -5]; % Mean of the 2nd component sigma2 = [1 0; 0 1]; % Covariance of the 2nd component
각 성분에서 같은 개수의 확률 변량을 생성하여 이 두 확률 변량 집합을 결합합니다.
rng('default') % For reproducibility r1 = mvnrnd(mu1,sigma1,1000); r2 = mvnrnd(mu2,sigma2,1000); X = [r1; r2];
결합된 데이터 세트 X에는 두 개의 혼합된 이변량 가우스 분포를 따르는 확률 변량이 있습니다.
두 개의 성분을 갖는 GMM을 X에 피팅합니다.
gm = fitgmdist(X,2)
gm = Gaussian mixture distribution with 2 components in 2 dimensions Component 1: Mixing proportion: 0.500000 Mean: -2.9617 -4.9727 Component 2: Mixing proportion: 0.500000 Mean: 0.9539 2.0261
gm 객체의 속성을 나열합니다.
properties(gm)
Properties for class gmdistribution:
NumVariables
DistributionName
NumComponents
ComponentProportion
SharedCovariance
NumIterations
RegularizationValue
NegativeLogLikelihood
CovarianceType
mu
Sigma
AIC
BIC
Converged
ProbabilityTolerance
점 표기법을 사용하여 이러한 속성에 액세스할 수 있습니다. 예를 들어, 피팅된 모델이 주어진 경우 데이터 X에 대한 음의 로그 가능도를 나타내는 NegativeLogLikelihood 속성에 액세스해 보겠습니다.
gm.NegativeLogLikelihood
ans = 7.0584e+03
gmdistribution 객체를 생성한 후에는 객체 함수를 사용할 수 있습니다. 누적 분포 함수(cdf) 및 확률 밀도 함수(pdf)의 값을 계산하려면 cdf 및 pdf를 사용하십시오. 확률 변량을 생성하려면 random을 사용하십시오. 군집 분석을 수행하려면 cluster, mahal, posterior를 사용하십시오.
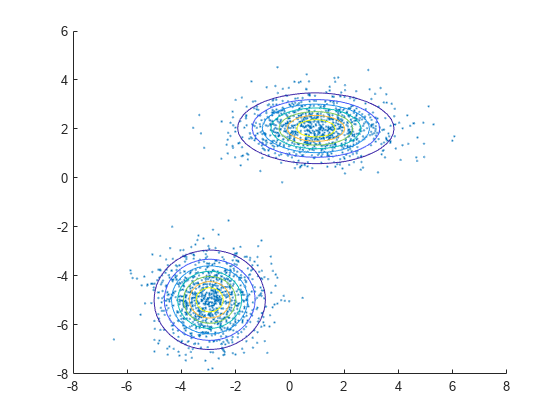
scatter를 사용하여 X를 플로팅합니다. pdf 및 fcontour를 사용하여 피팅된 모델 gm을 시각화합니다.
scatter(X(:,1),X(:,2),10,'.') % Scatter plot with points of size 10 hold on gmPDF = @(x,y) arrayfun(@(x0,y0) pdf(gm,[x0 y0]),x,y); fcontour(gmPDF,[-8 6])
참고 문헌
[1] McLachlan, G., and D. Peel. Finite Mixture Models. Hoboken, NJ: John Wiley & Sons, Inc., 2000.
버전 내역
R2007b에 개발됨