이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
가우스 혼합 모델을 사용하여 군집화하기
이 항목에서는 Statistics and Machine Learning Toolbox™ 함수 cluster를 사용하여 가우스 혼합 모델(GMM)로 군집화하는 방법을 소개하고, fitgmdist를 사용하여 GMM 모델을 피팅할 때 선택적 파라미터를 지정하면 어떠한 효과가 있는지 보여주는 예제를 살펴봅니다.
가우스 혼합 모델이 데이터를 군집화하는 방법
가우스 혼합 모델(GMM)은 데이터 군집화에 자주 사용됩니다. GMM을 사용하여, 쿼리 데이터에 대해 하드 군집화 또는 소프트 군집화를 수행할 수 있습니다.
GMM은 주어진 데이터에 대해 성분 사후 확률을 극대화하는 다변량 정규 성분에 쿼리 데이터 점을 할당하여 하드 군집화를 수행합니다. 즉, 피팅된 GMM이 주어진 경우, cluster는 가장 높은 사후 확률을 생성하는 성분에 쿼리 데이터를 할당합니다. 하드 군집화는 정확히 하나의 군집에 하나의 데이터 점을 할당합니다. GMM을 데이터에 피팅하고 피팅된 모델을 사용하여 군집화하며 성분 사후 확률을 추정하는 방법을 보여주는 예는 Cluster Gaussian Mixture Data Using Hard Clustering 항목을 참조하십시오.
또한 GMM을 사용하여 데이터에 대해 보다 유연한 군집화를 수행할 수 있는데, 이 방식을 소프트(또는 퍼지) 군집화라고 합니다. 소프트 군집화 방법은 각 군집에 대한 데이터 점에 점수를 할당합니다. 점수 값은 군집에 대한 데이터 점의 연결 강도를 나타냅니다. 하드 군집화 방법과 달리, 소프트 군집화 방법은 둘 이상의 군집에 데이터 점을 할당할 수 있기 때문에 유연합니다. GMM 군집화를 수행할 경우 점수는 사후 확률입니다. GMM을 사용한 소프트 군집화의 예는 Cluster Gaussian Mixture Data Using Soft Clustering 항목을 참조하십시오.
GMM 군집화는 크기와 상관관계 구조가 각기 다른 군집을 수용할 수 있습니다. 따라서 특정 응용 사례에서는 GMM 군집화가 k-평균 군집화 같은 방법보다 더 적합할 수 있습니다. 여러 군집화 방법과 마찬가지로, GMM 군집화를 수행하려면 모델 피팅 전에 군집 개수를 지정해야 합니다. 군집 개수에 따라 GMM의 성분 개수가 지정됩니다.
GMM을 수행할 경우 다음 모범 사례를 따르십시오.
성분 공분산 구조를 사용해 보십시오. 대각 공분산 행렬 또는 완전 공분산 행렬을 지정할 수 있고, 모든 성분이 동일한 공분산 행렬을 가지는지 여부를 지정할 수 있습니다.
초기 조건을 지정하십시오. 기대값 최대화(EM) 알고리즘은 GMM을 피팅합니다. k-평균 군집화 알고리즘에서와 같이 EM은 초기 조건에 민감하며 국소 최적해로 수렴할 수 있습니다. 모수에 대한 고유한 시작 값을 지정하거나 데이터 점에 대한 초기 군집 할당을 지정하거나 이러한 값을 임의로 선택되도록 하거나 k-평균++ 알고리즘을 사용하도록 지정할 수 있습니다.
정규화를 구현하십시오. 예를 들어, 데이터 점보다 예측 변수가 더 많은 경우 정규화하여 추정 안정성을 높일 수 있습니다.
다양한 공분산 옵션과 초기 조건을 사용하여 GMM 피팅하기
이 예제에서는 GMM 군집화를 수행할 때 공분산 구조에 대한 다양한 옵션과 초기 조건을 지정하면 어떠한 효과가 있는지 살펴봅니다.
피셔(Fisher)의 붓꽃 데이터 세트를 불러옵니다. 꽃받침 측정값을 군집화해 보고, 꽃받침 측정값을 사용하여 데이터를 2차원으로 시각화합니다.
load fisheriris; X = meas(:,1:2); [n,p] = size(X); plot(X(:,1),X(:,2),'.','MarkerSize',15); title('Fisher''s Iris Data Set'); xlabel('Sepal length (cm)'); ylabel('Sepal width (cm)');
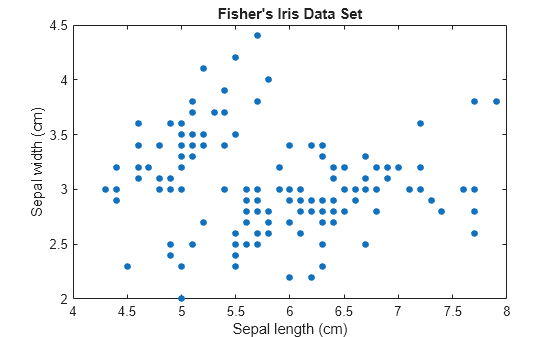
GMM의 성분 개수 k는 부모집단 또는 군집 개수를 결정합니다. 이 그림에서는 2개, 3개 또는 더 많은 가우스 성분이 적합한지 여부를 판단하기가 어렵습니다. k가 증가함에 따라 GMM의 복잡도가 증가합니다.
다양한 공분산 구조 옵션 지정하기
각 가우스 성분에는 공분산 행렬이 있습니다. 기하학적으로, 공분산 구조는 군집에 그려지는 타원체 모양을 띠는 신뢰 영역의 형태를 결정합니다. 모든 성분에 대한 공분산 행렬이 대각 공분산 행렬인지 아니면 완전 공분산 행렬인지를 지정할 수 있고, 모든 성분에 동일한 공분산 행렬이 있는지 여부를 지정할 수 있습니다. 각각의 지정 조합에 따라 타원체의 형태와 방향이 결정됩니다.
3개의 GMM 성분을 지정하고, EM 알고리즘의 최대 반복 횟수를 1000으로 지정합니다. 재현이 가능하도록 난수 시드값을 설정합니다.
rng(3); k = 3; % Number of GMM components options = statset('MaxIter',1000);
공분산 구조 옵션을 지정합니다.
Sigma = {'diagonal','full'}; % Options for covariance matrix type
nSigma = numel(Sigma);
SharedCovariance = {true,false}; % Indicator for identical or nonidentical covariance matrices
SCtext = {'true','false'};
nSC = numel(SharedCovariance);측정값의 극값으로 구성된 평면을 포함하는 2차원 그리드를 생성합니다. 이 그리드는 나중에 군집에 타원체 모양을 띠는 신뢰 영역을 그릴 때 사용됩니다.
d = 500; % Grid length
x1 = linspace(min(X(:,1))-2, max(X(:,1))+2, d);
x2 = linspace(min(X(:,2))-2, max(X(:,2))+2, d);
[x1grid,x2grid] = meshgrid(x1,x2);
X0 = [x1grid(:) x2grid(:)];다음과 같이 지정합니다.
공분산 구조 옵션으로 가능한 모든 조합에 대해 3개의 성분으로 GMM을 피팅하십시오.
피팅된 GMM을 사용하여 2차원 그리드를 군집화하십시오.
각 신뢰영역에 대한 99%의 확률 분계점을 지정하는 점수를 구하십시오. 이렇게 지정된 값에 따라 타원체의 장축과 단축의 길이가 결정됩니다.
군집과 유사한 색으로 각 타원체에 색을 칠하십시오.
threshold = sqrt(chi2inv(0.99,2)); count = 1; for i = 1:nSigma for j = 1:nSC gmfit = fitgmdist(X,k,'CovarianceType',Sigma{i}, ... 'SharedCovariance',SharedCovariance{j},'Options',options); % Fitted GMM clusterX = cluster(gmfit,X); % Cluster index mahalDist = mahal(gmfit,X0); % Distance from each grid point to each GMM component % Draw ellipsoids over each GMM component and show clustering result. subplot(2,2,count); h1 = gscatter(X(:,1),X(:,2),clusterX); hold on for m = 1:k idx = mahalDist(:,m)<=threshold; Color = h1(m).Color*0.75 - 0.5*(h1(m).Color - 1); h2 = plot(X0(idx,1),X0(idx,2),'.','Color',Color,'MarkerSize',1); uistack(h2,'bottom'); end plot(gmfit.mu(:,1),gmfit.mu(:,2),'kx','LineWidth',2,'MarkerSize',10) title(sprintf('Sigma is %s\nSharedCovariance = %s',Sigma{i},SCtext{j}),'FontSize',8) legend(h1,{'1','2','3'}) hold off count = count + 1; end end
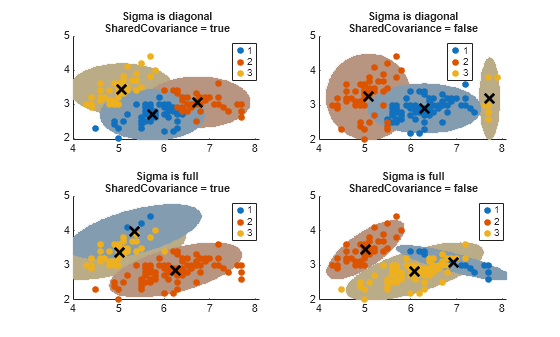
신뢰영역에 대한 확률 분계점은 장축과 단축의 길이를 결정하고, 공분산 유형은 좌표축의 방향을 결정합니다. 공분산 행렬 옵션과 관련해 다음 사항을 유의합니다.
대각 공분산 행렬은 예측 변수 간에 상관관계가 없다는 것을 나타냅니다. 타원의 장축과 단축은 x축과 y축에 대해 평행이거나 수직입니다. 이렇게 지정하면 각 성분에 대해 예측 변수의 개수 만큼 모수의 총 개수가 증가하지만, 완전 공분산 행렬을 지정하는 것보다 더욱 간결합니다.
완전 공분산 행렬에는 x축 및 y축에 대한 타원 방향의 제한 없이 상관관계가 있는 예측 변수가 허용됩니다. 각 성분은 만큼 모수의 총 개수를 증가시키지만 예측 변수 간 상관관계 구조를 포착합니다. 이렇게 지정될 경우 과적합이 발생할 수 있습니다.
공유 공분산 행렬은 모든 성분이 동일한 공분산 행렬을 가진다는 것을 나타냅니다. 모든 타원은 크기가 동일하며 동일한 방향을 갖습니다. 이렇게 지정될 경우 오직 하나의 성분에 대한 공분산 모수의 개수만큼 모수의 총 개수가 증가하므로 비공유 행렬을 지정하는 것보다 더욱 간결합니다.
비공유 공분산 행렬은 성분이 각각 고유한 공분산 행렬을 가진다는 것을 나타냅니다. 타원의 크기와 방향은 서로 다를 수 있습니다. 이렇게 지정되면 한 성분에 대해 공분산 모수 개수의 k배만큼 모수 개수가 증가하지만 성분 간 공분산 차이를 포착할 수 있습니다.
또한, 이 그림에서는 cluster가 군집 순서를 유지하지 않을 수도 있음을 보여줍니다. 여러 개의 피팅된 gmdistribution 모델을 군집화하는 경우 cluster는 유사한 성분에 다른 군집 레이블을 할당할 수 있습니다.
다양한 초기 조건 지정하기
GMM을 데이터에 피팅하는 알고리즘은 초기 조건에 민감할 수 있습니다. 이러한 민감도를 살펴보기 위해 다음과 같이 서로 다른 4개의 GMM을 피팅합니다.
첫 번째 GMM에서는 대부분의 데이터 점을 첫 번째 군집에 할당합니다.
두 번째 GMM에서는 데이터 점을 임의로 군집에 할당합니다.
세 번째 GMM에서는 데이터 점을 군집에 임의로 한 번 더 할당합니다.
네 번째 GMM에서는 k-평균++를 사용하여 초기 군집 중심을 구합니다.
initialCond1 = [ones(n-8,1); [2; 2; 2; 2]; [3; 3; 3; 3]]; % For the first GMM initialCond2 = randsample(1:k,n,true); % For the second GMM initialCond3 = randsample(1:k,n,true); % For the third GMM initialCond4 = 'plus'; % For the fourth GMM cluster0 = {initialCond1; initialCond2; initialCond3; initialCond4};
모든 경우에 대해 3개 성분(k = 3), 비공유 공분산 행렬과 완전 공분산 행렬, 동일한 초기 혼합 비율, 동일한 초기 공분산 행렬을 사용합니다. 여러 초기값 세트를 사용할 때 안정성을 높이려면 EM 알고리즘 반복 횟수를 늘리십시오. 또한, 군집에 타원체 모양을 띠는 신뢰 영역을 그립니다.
converged = nan(4,1); for j = 1:4 gmfit = fitgmdist(X,k,'CovarianceType','full', ... 'SharedCovariance',false,'Start',cluster0{j}, ... 'Options',options); clusterX = cluster(gmfit,X); % Cluster index mahalDist = mahal(gmfit,X0); % Distance from each grid point to each GMM component % Draw ellipsoids over each GMM component and show clustering result. subplot(2,2,j); h1 = gscatter(X(:,1),X(:,2),clusterX); % Distance from each grid point to each GMM component hold on; nK = numel(unique(clusterX)); for m = 1:nK idx = mahalDist(:,m)<=threshold; Color = h1(m).Color*0.75 + -0.5*(h1(m).Color - 1); h2 = plot(X0(idx,1),X0(idx,2),'.','Color',Color,'MarkerSize',1); uistack(h2,'bottom'); end plot(gmfit.mu(:,1),gmfit.mu(:,2),'kx','LineWidth',2,'MarkerSize',10) legend(h1,{'1','2','3'}); hold off converged(j) = gmfit.Converged; % Indicator for convergence end
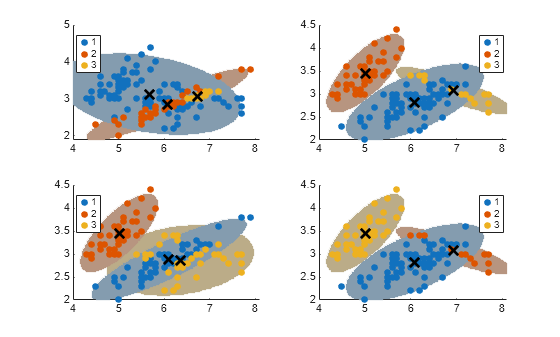
sum(converged)
ans = 4
모든 알고리즘이 수렴되었습니다. 데이터 점에 대해 각각 다르게 할당된 시작 군집 조건마다 각각 다르게 피팅된 군집 할당이 구현됩니다. 이름-값 쌍의 인수 Replicates에 양의 정수를 지정할 수 있으며, 여기에 지정된 횟수만큼 알고리즘이 실행됩니다. 그러면, fitgmdist는 가장 큰 가능도를 생성하는 피팅을 선택합니다.
정규화가 필요한 경우
EM 알고리즘 반복 중에 피팅된 공분산 행렬이 종종 조건이 나쁜 상태, 즉 가능도가 무한대가 되는 상태가 될 수 있습니다. 이 문제는 다음 조건 중 하나 이상에 해당하는 경우 발생할 수 있습니다.
데이터 점보다 예측 변수가 더 많은 경우.
너무 많은 성분에 대해 피팅하도록 지정한 경우.
변수가 밀접한 상관관계를 가질 경우.
이러한 문제를 해결하려면 'RegularizationValue' 이름-값 쌍의 인수를 사용하여 작은 양수를 지정하십시오. fitgmdist는 이 값을 전체 공분산 행렬의 대각선 요소에 추가하여 모든 행렬이 양의 정부호 행렬이 되도록 합니다. 정규화를 수행하면 최대가능도 값을 줄일 수 있습니다.
모델 피팅 통계량
대부분의 경우, 성분 개수 k와 적합한 공분산 구조 Σ는 알 수 없습니다. GMM을 조정할 수 있는 한 가지 방법은 정보 기준을 비교하는 것입니다. 많이 사용되는 두 가지 정보 기준은 아카이케 정보 기준(AIC: Akaike Information Criterion)과 베이즈 정보 기준(BIC: Bayesian Information Criterion)입니다.
AIC와 BIC 모두 최적화된 음의 로그 가능도를 취한 후 모델에 포함된 모수 개수로 벌점을 적용합니다(모델 복잡도). 그러나 BIC가 AIC에 비해 더 엄격하게 복잡도에 대해 벌점을 적용합니다. 따라서, AIC는 과적합될 수 있는 더 복잡한 모델을 선택하는 경향이 있고 BIC는 과소적합될 수 있는 더 단순한 모델을 선택하는 경향이 있습니다. 그러므로 모델을 평가할 때 두 기준을 모두 검토하는 것이 좋습니다. AIC 값이나 BIC 값이 낮을수록 더 나은 피팅 모델임을 나타냅니다. 또한 k에 대해 선택한 값과 공분산 행렬 구조가 현재 응용 사례에 적합한지도 확인해야 합니다. fitgmdist는 피팅된 gmdistribution 모델 객체의 AIC와 BIC를 속성 AIC와 BIC에 저장합니다. 점 표기법을 사용하여 이러한 속성에 액세스할 수 있습니다. 적합한 모수를 선택하는 방법을 보여주는 예제는 Tune Gaussian Mixture Models항목을 참조하십시오.
참고 항목
fitgmdist | gmdistribution | cluster
도움말 항목
- Cluster Gaussian Mixture Data Using Hard Clustering
- Cluster Gaussian Mixture Data Using Soft Clustering
- Tune Gaussian Mixture Models
- Choose Cluster Analysis Method