fsolve
비선형 연립방정식 풀기
구문
설명
비선형 시스템 솔버
다음으로 지정된 문제를 풉니다.
F(x) = 0
x에 대한 문제이며, 여기서 F(x)는 벡터 값을 반환하는 함수입니다.
x는 벡터 또는 행렬입니다. 행렬 인수 항목을 참조하십시오.
x = fsolve(fun,x0)x0에서 시작하여 0으로 구성된 배열인 방정식 fun(x) = 0을 풀려고 시도합니다.
참고
추가 파라미터 전달하기에는 필요한 경우 추가 파라미터를 벡터 함수 fun(x)에 전달하는 방법이 설명되어 있습니다. 파라미터화된 방정식 풀기 항목을 참조하십시오.
예제
이 예제에서는 두 변수로 구성된 두 비선형 방정식을 푸는 방법을 보여줍니다. 방정식은 다음과 같습니다.
이 방정식을 형식으로 변환합니다.
이 예제를 실행할 때 제공되는 root2d.m 함수가 값을 계산합니다.
type root2d.mfunction F = root2d(x) F(1) = exp(-exp(-(x(1)+x(2)))) - x(2)*(1+x(1)^2); F(2) = x(1)*cos(x(2)) + x(2)*sin(x(1)) - 0.5;
점 [0,0]에서 시작하여 연립방정식을 풉니다.
fun = @root2d; x0 = [0,0]; x = fsolve(fun,x0)
Equation solved. fsolve completed because the vector of function values is near zero as measured by the value of the function tolerance, and the problem appears regular as measured by the gradient. <stopping criteria details>
x = 1×2
0.3532 0.6061
비선형 시스템의 풀이 과정을 검토합니다.
계산 과정은 표시하지 않되, 알고리즘이 반복됨에 따라 0으로 수렴되는 1차 최적성을 표시하는 플롯 함수는 포함하도록 옵션을 설정합니다.
options = optimoptions("fsolve",... Display="none",PlotFcn=@optimplotfirstorderopt);
비선형 시스템의 방정식은 다음과 같습니다.
이 방정식을 형식으로 변환합니다.
root2d 함수는 이 두 방정식의 좌변을 계산합니다.
function F = root2d(x) F(1) = exp(-exp(-(x(1)+x(2)))) - x(2)*(1+x(1)^2); F(2) = x(1)*cos(x(2)) + x(2)*sin(x(1)) - 0.5; end
점 [0,0]에서 시작하여 비선형 시스템을 푼 다음 풀이 과정을 살펴봅니다.
fun = @root2d; x0 = [0,0]; x = fsolve(fun,x0,options)
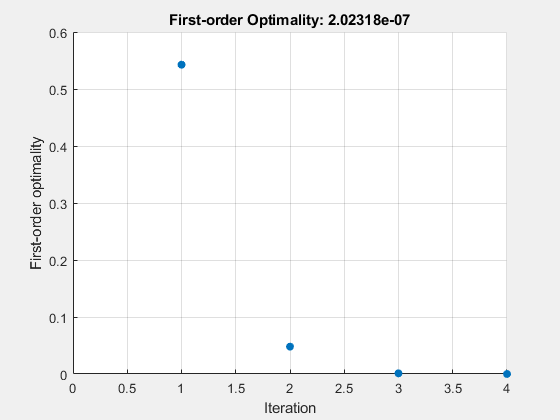
x = 1×2
0.3532 0.6061
추가 파라미터 전달하기 항목에 설명한 대로 방정식을 파라미터화할 수 있습니다. 예를 들어, 이 예제 마지막 부분에 있는 헬퍼 함수 paramfun은 로 파라미터화된 다음의 연립방정식을 만듭니다.
특정 값에 대한 연립방정식을 풀려면(이 경우 ), 작업 공간에 를 설정하고 paramfun으로부터 x의 익명 함수를 만듭니다.
c = -1; fun = @(x)paramfun(x,c);
점 x0 = [0 1]에서 시작하여 연립방정식을 풉니다.
x0 = [0 1]; x = fsolve(fun,x0)
Equation solved. fsolve completed because the vector of function values is near zero as measured by the value of the function tolerance, and the problem appears regular as measured by the gradient. <stopping criteria details>
x = 1×2
0.1976 0.4255
의 다른 값을 구하려면, 작업 공간에 를 입력하고 fun 함수를 다시 생성하십시오. 그러면 함수는 새로운 값을 갖게 됩니다.
c = -2;
fun = @(x)paramfun(x,c); % fun now has the new c value
x = fsolve(fun,x0)Equation solved. fsolve completed because the vector of function values is near zero as measured by the value of the function tolerance, and the problem appears regular as measured by the gradient. <stopping criteria details>
x = 1×2
0.1788 0.3418
헬퍼 함수
다음 코드는 paramfun 헬퍼 함수를 생성합니다.
function F = paramfun(x,c) F = [ 2*x(1) + x(2) - exp(c*x(1)) -x(1) + 2*x(2) - exp(c*x(2))]; end
fsolve에 대한 문제 구조체를 만들고 문제를 풉니다.
디폴트가 아닌 옵션을 사용한 풀이에 나온 것과 동일한 문제를 풀되, 문제 구조체를 사용하여 문제를 정식화합니다.
계산 과정은 표시하지 않되, 알고리즘이 반복됨에 따라 0으로 수렴되는 1차 최적성을 표시하는 플롯 함수는 포함하도록 문제의 옵션을 설정합니다.
problem.options = optimoptions("fsolve",... Display="none",PlotFcn=@optimplotfirstorderopt);
비선형 시스템의 방정식은 다음과 같습니다.
이 방정식을 형식으로 변환합니다.
root2d 함수는 이 두 방정식의 좌변을 계산합니다.
function F = root2d(x) F(1) = exp(-exp(-(x(1)+x(2)))) - x(2)*(1+x(1)^2); F(2) = x(1)*cos(x(2)) + x(2)*sin(x(1)) - 0.5; end
문제 구조체의 나머지 필드를 만듭니다.
problem.objective = @root2d;
problem.x0 = [0,0];
problem.solver = "fsolve";문제를 풉니다.
x = fsolve(problem)
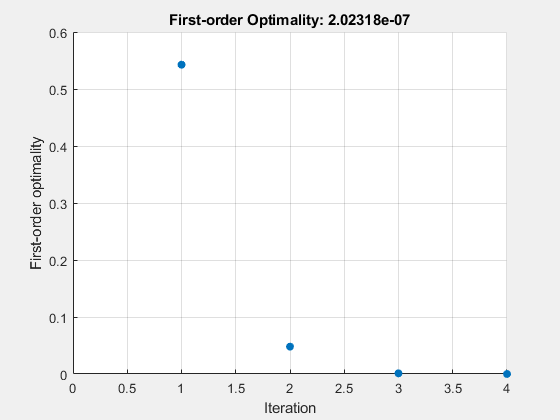
x = 1×2
0.3532 0.6061
이 예제에서는 다음과 같이 두 개의 방정식과 두 개의 미지수로 구성된 시스템에 대한 풀이의 반복 과정을 표시합니다.
이 방정식을 형식으로 다시 작성합니다.
x0 = [-5 -5]에서 해 탐색을 시작합니다.
먼저, x에서 방정식 값 F를 계산하는 함수를 작성합니다.
F = @(x) [2*x(1) - x(2) - exp(-x(1));
-x(1) + 2*x(2) - exp(-x(2))];초기점 x0을 만듭니다.
x0 = [-5;-5];
반복 과정을 표시하도록 옵션을 설정합니다.
options = optimoptions("fsolve",Display="iter");
방정식을 풉니다.
[x,fval] = fsolve(F,x0,options)
Norm of First-order Trust-region
Iteration Func-count ||f(x)||^2 step optimality radius
0 3 47071.2 2.29e+04 1
1 6 12003.4 1 5.75e+03 1
2 9 3147.02 1 1.47e+03 1
3 12 854.452 1 388 1
4 15 239.527 1 107 1
5 18 67.0412 1 30.8 1
6 21 16.7042 1 9.05 1
7 24 2.42788 1 2.26 1
8 27 0.032658 0.759511 0.206 2.5
9 30 7.03149e-06 0.111927 0.00294 2.5
10 33 3.29525e-13 0.00169132 6.36e-07 2.5
Equation solved.
fsolve completed because the vector of function values is near zero
as measured by the value of the function tolerance, and
the problem appears regular as measured by the gradient.
<stopping criteria details>
x = 2×1
0.5671
0.5671
fval = 2×1
10-6 ×
-0.4059
-0.4059
반복 과정에서 함수 F(x)의 노름에 대한 제곱인 f(x)가 표시됩니다. 이 값은 반복이 진행될 때마다 0에 가깝게 감소합니다. 마찬가지로 1차 최적성 측정값도 반복이 진행될 때마다 0에 가깝게 감소합니다. 이러한 요소가 해에 대한 반복 수렴을 나타냅니다. 다른 요소에 대한 의미는 반복 과정 표시 항목을 참조하십시오.
fval 출력값은 함수 값 F(x)를 제공하고, 이 값은 해(FunctionTolerance 허용오차 내에서)에서 0이어야 합니다.
다음을 충족하는 행렬 를 구합니다.
,
점 x0 = [1,1;1,1]에서 시작합니다. 행렬 방정식을 계산하는 익명 함수를 만들고 점 x0을 생성합니다.
fun = @(x)x*x*x - [1,2;3,4]; x0 = ones(2);
계산 과정을 표시하지 않도록 옵션을 설정합니다.
options = optimoptions("fsolve",Display="off");
fsolve 출력값을 검토하여 해의 품질과 풀이 과정을 확인합니다.
[x,fval,exitflag,output] = fsolve(fun,x0,options)
x = 2×2
-0.1291 0.8602
1.2903 1.1612
fval = 2×2
10-9 ×
-0.2740 0.1257
0.1884 -0.0858
exitflag = 1
output = struct with fields:
iterations: 11
funcCount: 52
algorithm: 'trust-region-dogleg'
firstorderopt: 4.0012e-10
message: 'Equation solved.↵↵fsolve completed because the vector of function values is near zero↵as measured by the value of the function tolerance, and↵the problem appears regular as measured by the gradient.↵↵<stopping criteria details>↵↵Equation solved. The sum of squared function values, r = 1.337650e-19, is less than↵sqrt(options.FunctionTolerance) = 1.000000e-03. The relative norm of the gradient of r,↵4.001213e-10, is less than options.OptimalityTolerance = 1.000000e-06.'
종료 플래그 값 1은 해를 신뢰할 수 있음을 나타냅니다. 잔차(fval의 제곱합)를 계산하여 0에 얼마나 가까운지 살펴봄으로써 이를 수동으로 확인할 수 있습니다.
sum(sum(fval.*fval))
ans = 1.3376e-19
이렇게 잔차가 작을 경우 x가 해라는 것을 확인할 수 있습니다.
output 구조체에서 해를 구하기 위해 fsolve가 수행한 반복 횟수와 함수 실행 횟수를 확인할 수 있습니다.
입력 인수
출력 인수
제한 사항
풀려는 함수는 연속 함수여야 합니다.
성공할 경우
fsolve는 하나의 근만 제공합니다.디폴트 값인 trust-region dogleg 방법은 연립방정식이 정사각 행렬인 경우(즉, 방정식 개수가 미지수 개수와 같음)에만 사용할 수 있습니다. Levenberg-Marquardt 방법을 사용하는 경우 연립방정식이 정사각 행렬일 필요가 없습니다.
세부 정보

팁
변수가 수천 개 이상 있는 큰 문제의 경우,
Algorithm옵션을'trust-region'으로 설정하고SubproblemAlgorithm옵션을'cg'로 설정하면 메모리를 절약할 수 있으며 시간도 절약할 수 있습니다.
알고리즘
Levenberg-Marquardt 방법과 trust-region 방법은 lsqnonlin에도 사용된 비선형 최소제곱 알고리즘을 기반으로 합니다. 시스템이 0을 가지지 않을 가능성이 있는 경우 이 방법 중 하나를 사용하십시오. 알고리즘은 여전히 잔차가 작은 점을 반환합니다. 하지만, 시스템의 야코비 행렬이 특이 행렬인 경우 알고리즘이 연립방정식의 해가 아닌 점으로 수렴할 수 있습니다(제한 사항 참조).
기본적으로
fsolve는 trust-region dogleg 알고리즘을 선택합니다. 이 알고리즘은 파월(Powell)의 dogleg 방법([8]에 설명되어 있음)의 변형입니다. 이는 [7]에 구현된 알고리즘과 성격이 비슷합니다. Trust-Region-Dogleg 알고리즘 항목을 참조하십시오.trust-region 알고리즘은 부분공간 trust-region 방법이며 interior-reflective 뉴턴 방법([1] 및 [2]에 설명되어 있음)을 기반으로 합니다. 각 반복에는 선조건 적용 켤레 기울기(PCG) 방법을 사용한 대규모 선형 시스템의 근사해 풀이 작업이 포함됩니다. Trust-Region 알고리즘 항목을 참조하십시오.
Levenberg-Marquardt 방법은 참고 문헌 [4], [5], [6]에 설명되어 있습니다. Levenberg-Marquardt 방법 항목을 참조하십시오.
대체 기능
앱
최적화 라이브 편집기 작업은 fsolve에 대한 시각적 인터페이스를 제공합니다.
참고 문헌
[1] Coleman, T.F. and Y. Li, “An Interior, Trust Region Approach for Nonlinear Minimization Subject to Bounds,” SIAM Journal on Optimization, Vol. 6, pp. 418-445, 1996.
[2] Coleman, T.F. and Y. Li, “On the Convergence of Reflective Newton Methods for Large-Scale Nonlinear Minimization Subject to Bounds,” Mathematical Programming, Vol. 67, Number 2, pp. 189-224, 1994.
[3] Dennis, J. E. Jr., “Nonlinear Least-Squares,” State of the Art in Numerical Analysis, ed. D. Jacobs, Academic Press, pp. 269-312.
[4] Levenberg, K., “A Method for the Solution of Certain Problems in Least-Squares,” Quarterly Applied Mathematics 2, pp. 164-168, 1944.
[5] Marquardt, D., “An Algorithm for Least-squares Estimation of Nonlinear Parameters,” SIAM Journal Applied Mathematics, Vol. 11, pp. 431-441, 1963.
[6] Moré, J. J., “The Levenberg-Marquardt Algorithm: Implementation and Theory,” Numerical Analysis, ed. G. A. Watson, Lecture Notes in Mathematics 630, Springer Verlag, pp. 105-116, 1977.
[7] Moré, J. J., B. S. Garbow, and K. E. Hillstrom, User Guide for MINPACK 1, Argonne National Laboratory, Rept. ANL-80-74, 1980.
[8] Powell, M. J. D., “A Fortran Subroutine for Solving Systems of Nonlinear Algebraic Equations,” Numerical Methods for Nonlinear Algebraic Equations, P. Rabinowitz, ed., Ch.7, 1970.