lstmProjectedLayer
Long short-term memory (LSTM) projected layer for recurrent neural network (RNN)
Since R2022b
Description
An LSTM projected layer is an RNN layer that learns long-term dependencies between time steps in time-series and sequence data using projected learnable weights.
To compress a deep learning network, you can use projected layers. A projected layer is a type of deep learning layer that enables compression by reducing the number of stored learnable parameters. The layer introduces learnable projector matrices Q, replaces multiplications of the form , where W is a learnable matrix, with the multiplication , and stores Q and instead of storing W. Projecting x into a lower dimensional space using Q typically requires less memory to store the learnable parameters and can have similarly strong prediction accuracy.
Reducing the number of learnable parameters by projecting an LSTM layer rather than reducing the number of hidden units of the LSTM layer maintains the output size of the layer and, in turn, the sizes of the downstream layers, which can result in better prediction accuracy.
Creation
Syntax
Description
layer = lstmProjectedLayer(numHiddenUnits,outputProjectorSize,inputProjectorSize)NumHiddenUnits, OutputProjectorSize, and InputProjectorSize properties.
layer = lstmProjectedLayer(___,PropertyName=Value)OutputMode, HasStateInputs, HasStateOutputs, Activations, State, Parameters and Initialization, Learning Rate and Regularization, and Name properties using one or more name-value arguments.
Tip
To compress a neural network using projection, use the compressNetworkUsingProjection function.
Properties
Examples
Create an LSTM projected layer with 100 hidden units, an output projector size of 30, an input projector size of 16, and the name "lstmp".
layer = lstmProjectedLayer(100,30,16,Name="lstmp")layer =
LSTMProjectedLayer with properties:
Name: 'lstmp'
InputNames: {'in'}
OutputNames: {'out'}
NumInputs: 1
NumOutputs: 1
HasStateInputs: 0
HasStateOutputs: 0
Hyperparameters
InputSize: 'auto'
NumHiddenUnits: 100
InputProjectorSize: 16
OutputProjectorSize: 30
OutputMode: 'sequence'
StateActivationFunction: 'tanh'
GateActivationFunction: 'sigmoid'
Learnable Parameters
InputWeights: []
RecurrentWeights: []
Bias: []
InputProjector: []
OutputProjector: []
State Parameters
HiddenState: []
CellState: []
Show all properties
Include an LSTM projected layer in a layer array.
inputSize = 12;
numHiddenUnits = 100;
outputProjectorSize = max(1,floor(0.75*numHiddenUnits));
inputProjectorSize = max(1,floor(0.25*inputSize));
layers = [
sequenceInputLayer(inputSize)
lstmProjectedLayer(numHiddenUnits,outputProjectorSize,inputProjectorSize)
fullyConnectedLayer(10)
softmaxLayer];Compare the sizes of networks that do and do not contain projected layers.
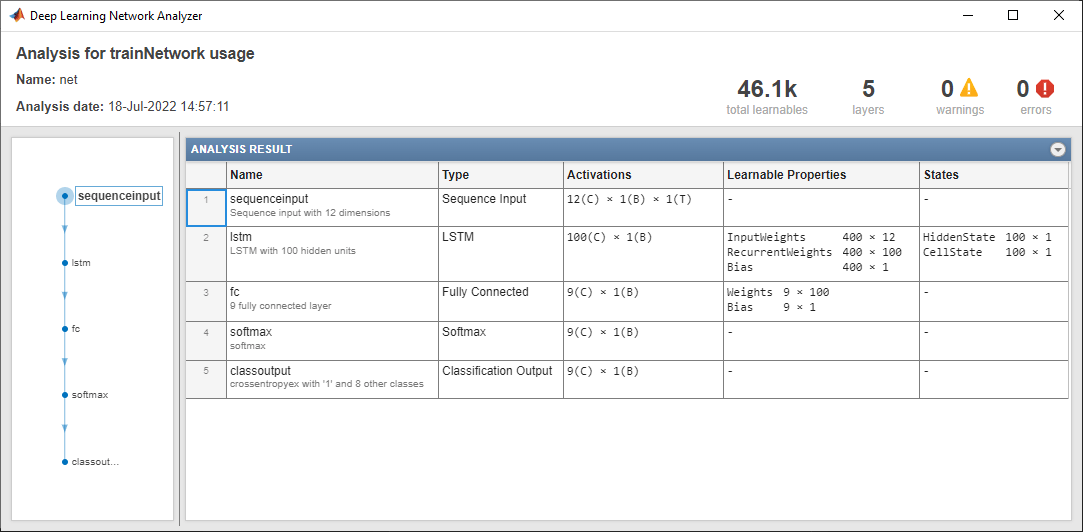
Define an LSTM network architecture. Specify the input size as 12, which corresponds to the number of features of the input data. Configure an LSTM layer with 100 hidden units that outputs the last element of the sequence. Finally, specify nine classes by including a fully connected layer of size 9, followed by a softmax layer and a classification layer.
inputSize = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(inputSize) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numClasses) softmaxLayer classificationLayer]
layers =
5×1 Layer array with layers:
1 '' Sequence Input Sequence input with 12 channels
2 '' LSTM LSTM with 100 hidden units
3 '' Fully Connected Fully connected layer with output size 9
4 '' Softmax Softmax
5 '' Classification Output crossentropyex
Analyze the network using the analyzeNetwork function. The network has approximately 46,100 learnable parameters.
analyzeNetwork(layers)
Create an identical network with an LSTM projected layer in place of the LSTM layer.
For the LSTM projected layer:
Specify the same number of hidden units as the LSTM layer
Specify an output projector size of 25% of the number of hidden units.
Specify an input projector size of 75% of the input size.
Ensure that the output and input projector sizes are positive by taking the maximum of the sizes and 1.
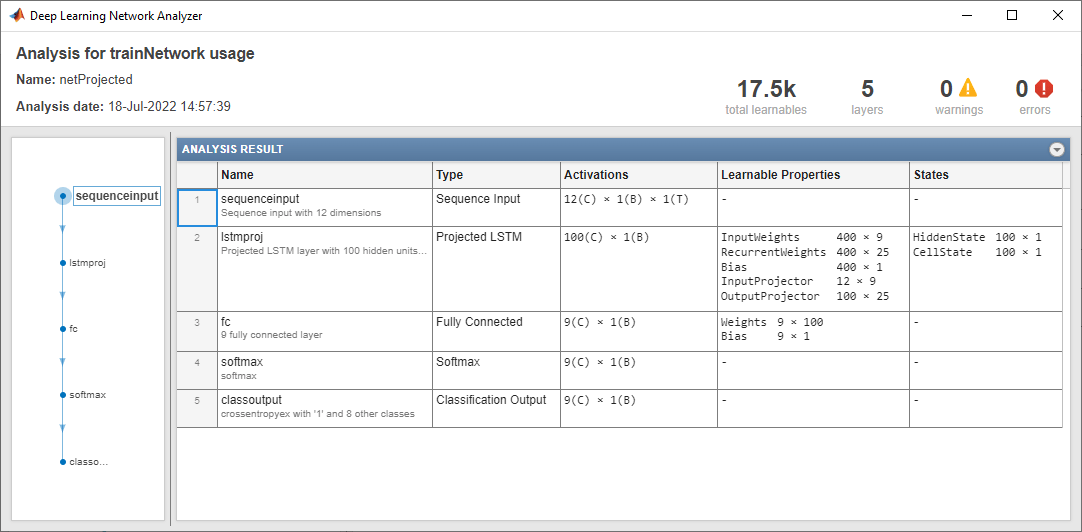
outputProjectorSize = max(1,floor(0.25*numHiddenUnits)); inputProjectorSize = max(1,floor(0.75*inputSize)); layersProjected = [ ... sequenceInputLayer(inputSize) lstmProjectedLayer(numHiddenUnits,outputProjectorSize,inputProjectorSize,OutputMode="last") fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
Analyze the network using the analyzeNetwork function. The network has approximately 17,500 learnable parameters, which is a reduction of more than half. The sizes of the learnable parameters of the layers following the projected layer have the same sizes as the network without the LSTM projected layer. Reducing the number of learnable parameters by projecting an LSTM layer rather than reducing the number of hidden units of the LSTM layer maintains the output size of the layer and, in turn, the sizes of the downstream layers, which can result in better prediction accuracy.
analyzeNetwork(layersProjected)
Algorithms
An LSTM layer is an RNN layer that learns long-term dependencies between time steps in time-series and sequence data.
The state of the layer consists of the hidden state (also known as the output state) and the cell state. The hidden state at time step t contains the output of the LSTM layer for this time step. The cell state contains information learned from the previous time steps. At each time step, the layer adds information to or removes information from the cell state. The layer controls these updates using gates.
These components control the cell state and hidden state of the layer.
| Component | Purpose |
|---|---|
| Input gate (i) | Control level of cell state update |
| Forget gate (f) | Control level of cell state reset (forget) |
| Cell candidate (g) | Add information to cell state |
| Output gate (o) | Control level of cell state added to hidden state |
This diagram illustrates the flow of data at time step t. This diagram shows how the gates forget, update, and output the cell and hidden states.

The learnable weights of an LSTM layer are the input weights W
(InputWeights), the recurrent weights R
(RecurrentWeights), and the bias b
(Bias). The matrices W, R,
and b are concatenations of the input weights, the recurrent weights, and
the bias of each component, respectively. The layer concatenates the matrices according to
these equations:
where i, f, g, and o denote the input gate, forget gate, cell candidate, and output gate, respectively.
The cell state at time step t is given by
where denotes the Hadamard product (element-wise multiplication of vectors).
The hidden state at time step t is given by
where denotes the state activation function. By default, the
lstmLayer function uses the hyperbolic tangent function (tanh) to
compute the state activation function.
These formulas describe the components at time step t.
| Component | Formula |
|---|---|
| Input gate | |
| Forget gate | |
| Cell candidate | |
| Output gate |
In these calculations, denotes the gate activation function. By default, the
lstmLayer function, uses the sigmoid function, given by , to compute the gate activation function.
References
[1] Glorot, Xavier, and Yoshua Bengio. "Understanding the Difficulty of Training Deep Feedforward Neural Networks." In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, 249–356. Sardinia, Italy: AISTATS, 2010. https://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf
[2] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification." In 2015 IEEE International Conference on Computer Vision (ICCV), 1026–34. Santiago, Chile: IEEE, 2015. https://doi.org/10.1109/ICCV.2015.123
[3] Saxe, Andrew M., James L. McClelland, and Surya Ganguli. "Exact Solutions to the Nonlinear Dynamics of Learning in Deep Linear Neural Networks.” Preprint, submitted February 19, 2014. https://arxiv.org/abs/1312.6120.
Extended Capabilities
Version History
Introduced in R2022bSee Also
compressNetworkUsingProjection | neuronPCA | trainingOptions | trainnet | ProjectedLayer | gruProjectedLayer | lstmLayer | exportNetworkToSimulink | LSTM Projected Layer
Topics
- Train Network with LSTM Projected Layer
- Compress Neural Network Using Projection
- Sequence Classification Using Deep Learning
- Sequence Classification Using 1-D Convolutions
- Time Series Forecasting Using Deep Learning
- Sequence-to-Sequence Classification Using Deep Learning
- Sequence-to-Sequence Regression Using Deep Learning
- Sequence-to-One Regression Using Deep Learning
- Classify Videos Using Deep Learning
- Long Short-Term Memory Neural Networks
- List of Deep Learning Layers
- Deep Learning Tips and Tricks