딥러닝을 사용한 sequence-to-sequence 분류
이 예제에서는 장단기 기억(LSTM) 신경망을 사용하여 시퀀스 데이터의 각 시간 스텝을 분류하는 방법을 보여줍니다.
시퀀스 데이터의 각 시간 스텝을 분류하도록 심층 신경망을 훈련시키기 위해 sequence-to-sequence LSTM 신경망을 사용할 수 있습니다. sequence-to-sequence LSTM 신경망을 사용하면 시퀀스 데이터의 개별 시간 스텝에 대해 각각 서로 다른 예측을 수행할 수 있습니다.
이 예제에서는 신체에 착용한 스마트폰으로부터 얻은 센서 데이터를 사용합니다. 이 예제에서는 서로 다른 세 방향의 가속도계 측정값을 나타내는 시계열 데이터에서 착용자의 활동을 인식하도록 LSTM 신경망을 훈련시킵니다.
시퀀스 데이터 불러오기
사람의 동작에 대한 인식 데이터를 불러옵니다. 훈련 데이터는 6명의 시계열 데이터를 포함합니다. 테스트 데이터에는 일곱 번째 사람에 대한 단일 시계열이 들어 있습니다. 각 시퀀스는 3개의 특징을 가지며 길이가 서로 다릅니다. 3개의 특징은 서로 다른 세 방향의 가속도계 측정값에 대응됩니다.
load HumanActivityTrain
XTrainXTrain=6×1 cell array
{3×64480 double}
{3×53696 double}
{3×56416 double}
{3×50688 double}
{3×51888 double}
{3×54256 double}
훈련 시퀀스 1개를 플롯으로 시각화합니다. 첫 번째 훈련 시퀀스의 첫 번째 특징을 플로팅하고 대응하는 동작에 따라 플롯에 색을 입힙니다.
X = XTrain{1}(1,:);
classes = categories(YTrain{1});
figure
for j = 1:numel(classes)
label = classes(j);
idx = find(YTrain{1} == label);
hold on
plot(idx,X(idx))
end
hold off
xlabel("Time Step")
ylabel("Acceleration")
title("Training Sequence 1, Feature 1")
legend(classes,Location="northwest")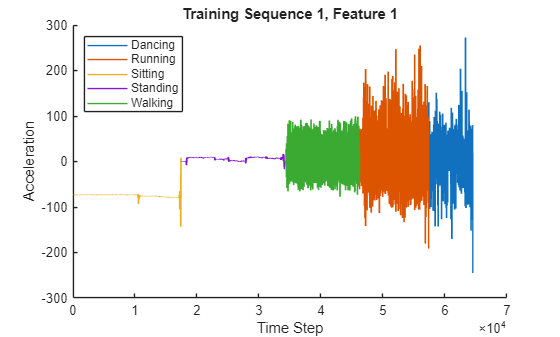
LSTM 신경망 아키텍처 정의하기
LSTM 신경망 아키텍처를 정의합니다. 입력값이 크기가 3(입력 데이터의 특징 개수)인 시퀀스가 되도록 지정합니다. 은닉 유닛 200개를 갖는 LSTM 계층을 지정하고 전체 시퀀스를 출력합니다. 마지막으로, 크기가 5인 완전 연결 계층을 포함하여 5개의 클래스를 지정하고, 이어서 소프트맥스 계층을 지정합니다.
numFeatures = 3; numHiddenUnits = 200; numClasses = 5; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="sequence") fullyConnectedLayer(numClasses) softmaxLayer];
훈련 옵션을 지정합니다.
Adam 솔버를 사용하여 훈련시킵니다.
훈련을 Epoch 60회 수행합니다.
훈련 데이터는 행과 열이 각각 채널과 시간 스텝에 대응하는 시퀀스를 가지므로 입력 데이터 형식
"CTB"(채널, 시간, 배치)를 지정합니다.기울기가 한없이 증가하지 않도록 하려면 기울기 임계값을 2로 설정하십시오.
훈련 진행 상황을 플롯에 표시하고 세부 정보가 출력되지 않도록 합니다.
훈련 중에 신경망의 정확도를 모니터링합니다.
options = trainingOptions("adam", ... MaxEpochs=60, ... InputDataFormats="CTB", ... GradientThreshold=2, ... Plots="training-progress", ... Verbose=false, ... Metrics="accuracy");
trainnet 함수를 사용하여 LSTM 신경망을 훈련시킵니다. 분류에는 교차 엔트로피 손실을 사용합니다. 기본적으로 trainnet 함수는 GPU를 사용할 수 있으면 GPU를 사용합니다. GPU에서 훈련시키려면 Parallel Computing Toolbox™ 라이선스와 지원되는 GPU 장치가 필요합니다. 지원되는 장치에 대한 자세한 내용은 GPU 연산 요구 사항을 참조하십시오. GPU를 사용할 수 없는 경우, trainnet 함수는 CPU를 사용합니다. 실행 환경을 수동으로 선택하려면 ExecutionEnvironment 훈련 옵션을 사용하십시오. 각 미니 배치는 전체 훈련 세트를 포함하므로 Epoch당 한 번씩 플롯이 업데이트됩니다. 시퀀스가 매우 길기 때문에 각 미니 배치를 처리하고 플롯을 업데이트하는 데 시간이 걸릴 수 있습니다.
net = trainnet(XTrain,YTrain,layers,"crossentropy",options);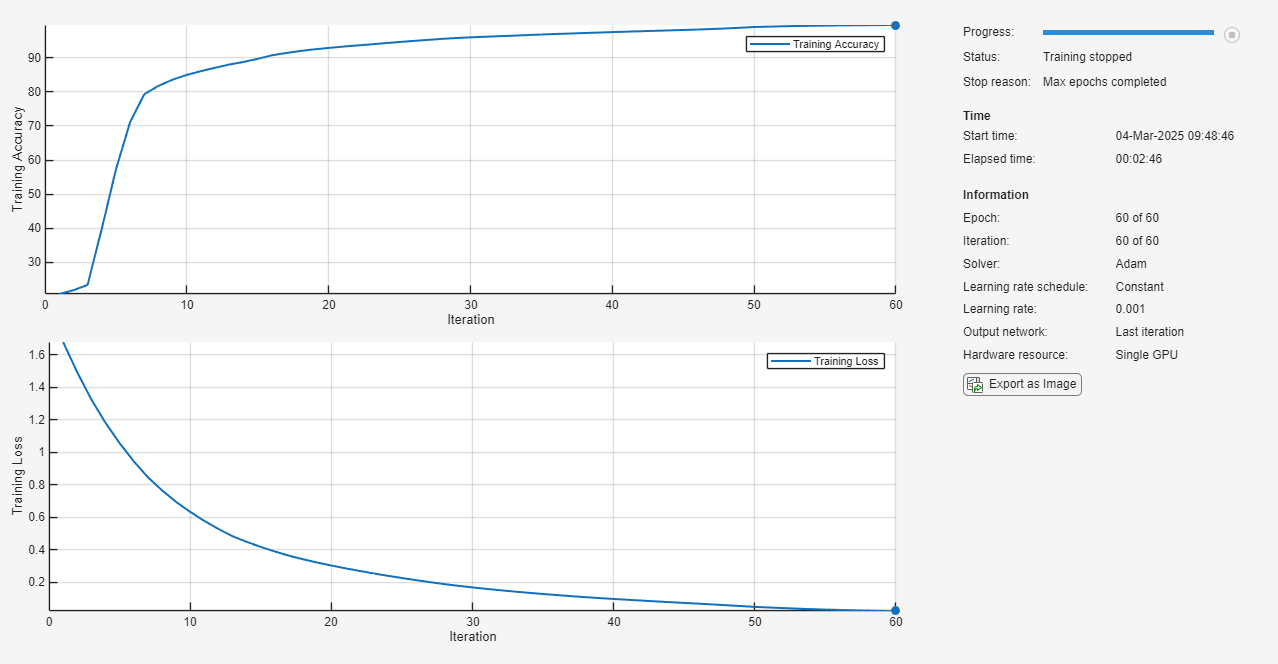
LSTM 신경망 테스트하기
테스트 데이터를 불러오고 각 시간 스텝마다 동작을 분류합니다.
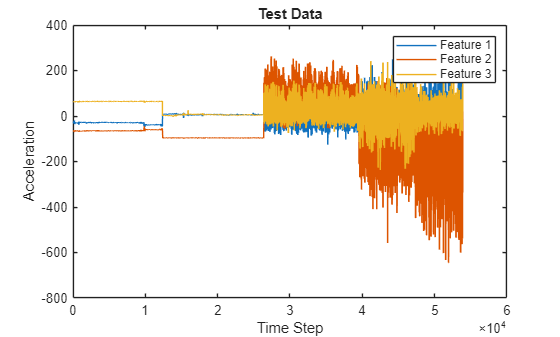
사람의 동작에 대한 테스트 데이터를 불러옵니다. XTest는 차원이 3인 단일 시퀀스를 포함합니다. YTest는 각 시간 스텝에서의 동작에 대응하는 categorical형 레이블로 구성된 시퀀스를 포함합니다.
load HumanActivityTest figure XTest = XTest{1}'; plot(XTest) xlabel("Time Step") ylabel("Acceleration") legend("Feature " + (1:numFeatures)) title("Test Data")
단일 관측값 입력에 대해 predict 함수를 사용하여 예측을 수행합니다. GPU를 사용하여 예측을 수행하려면 먼저 데이터를 gpuArray로 변환합니다.
if canUseGPU XTest = gpuArray(XTest); end scores = predict(net,XTest);
예측 점수를 레이블로 변환하려면 scores2label 함수를 사용합니다.
Y = scores2label(scores,classes);
또는 predict 함수를 사용하여 한 번에 시간 스텝 하나씩 예측을 수행하여 업데이트된 신경망 상태를 출력값으로 반환할 수 있습니다. 그런 다음 상태 출력값을 사용하여 신경망의 State 속성을 업데이트합니다. 이 방법은 시간 스텝의 값이 스트림으로 수신되는 경우에 유용합니다. 일반적으로 한 번에 시간 스텝 하나씩 예측을 수행하는 것보다 전체 시퀀스에 대해 예측을 수행하는 것이 빠릅니다. 단일 시간 스텝 예측들 사이에서 신경망을 업데이트하여 미래의 시간 스텝을 전망하는 방법에 대한 예제는 딥러닝을 사용한 시계열 전망 항목을 참조하십시오.
예측의 정확도를 계산합니다.
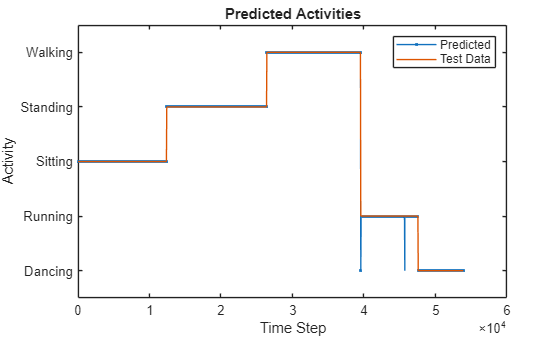
acc = sum(Y == YTest{1}')./numel(YTest{1})acc = 0.9983
플롯을 사용하여 예측을 테스트 데이터와 비교합니다.
figure plot(Y,".-") hold on plot(YTest{1}) hold off xlabel("Time Step") ylabel("Activity") title("Predicted Activities") legend(["Predicted" "Test Data"])
참고 항목
trainnet | trainingOptions | dlnetwork | lstmLayer | sequenceInputLayer