장단기 기억 신경망
이 항목에서는 장단기 기억(LSTM) 신경망을 사용하여 분류 및 회귀 작업에 대해 시퀀스 및 시계열 데이터로 작업하는 방법을 설명합니다. LSTM 신경망을 사용하여 시퀀스 데이터를 분류하는 방법을 보여주는 예제는 딥러닝을 사용한 시퀀스 분류 항목을 참조하십시오.
LSTM 신경망은 시퀀스 데이터의 시간 스텝 간의 장기적인 종속성을 학습할 수 있는 순환 신경망(RNN)의 일종입니다.
LSTM 신경망 아키텍처
LSTM 신경망의 핵심 컴포넌트는 시퀀스 입력 계층과 LSTM 계층입니다. 시퀀스 입력 계층은 신경망에 시퀀스 또는 시계열 데이터를 입력합니다. LSTM 계층은 시퀀스 데이터의 시간 스텝 간의 장기 종속성을 학습합니다.
다음 도식은 분류를 위한 간단한 LSTM 신경망의 아키텍처를 보여줍니다. 이 신경망은 시퀀스 입력 계층으로 시작하고, 그 뒤에 LSTM 계층이 옵니다. 클래스 레이블을 예측하기 위해, 신경망의 끝부분에는 완전 연결 계층과 소프트맥스 계층이 옵니다.

다음 도식은 회귀를 위한 간단한 LSTM 신경망의 아키텍처를 보여줍니다. 이 신경망은 시퀀스 입력 계층으로 시작하고, 그 뒤에 LSTM 계층이 옵니다. 신경망의 끝부분에는 완전 연결 계층이 옵니다.

분류 LSTM 신경망
sequence-to-label 분류를 위한 LSTM 신경망을 만들려면 시퀀스 입력 계층, LSTM 계층, 완전 연결 계층, 소프트맥스 계층을 포함하는 계층 배열을 만듭니다.
시퀀스 입력 계층의 크기를 입력 데이터의 특징 개수로 설정합니다. 완전 연결 계층의 크기를 클래스 개수로 설정합니다. 시퀀스 길이는 지정할 필요가 없습니다.
LSTM 계층의 경우, 은닉 유닛의 개수와 출력 모드 "last"를 지정합니다.
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numClasses) softmaxLayer];
sequence-to-label 분류를 위한 LSTM 신경망을 훈련시키고 새 데이터를 분류하는 방법을 보여주는 예제는 딥러닝을 사용한 시퀀스 분류 항목을 참조하십시오.
sequence-to-sequence 분류를 위한 LSTM 신경망을 만들려면 sequence-to-label 분류와 동일한 아키텍처를 사용하되 LSTM 계층의 출력 모드를 "sequence"로 설정합니다.
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="sequence") fullyConnectedLayer(numClasses) softmaxLayer];
회귀 LSTM 신경망
sequence-to-one 회귀를 위한 LSTM 신경망을 만들려면 시퀀스 입력 계층, LSTM 계층, 완전 연결 계층을 포함하는 계층 배열을 만듭니다.
시퀀스 입력 계층의 크기를 입력 데이터의 특징 개수로 설정합니다. 완전 연결 계층의 크기를 응답 변수의 개수로 설정합니다. 시퀀스 길이는 지정할 필요가 없습니다.
신경망을 훈련시킬 때 NormalizeTargets 훈련 옵션(R2026a에서 추가됨)을 사용하여 훈련 목표값을 자동으로 정규화할 수 있습니다. 정규화된 목표값을 사용하면 훈련을 안정화하고 정규화된 목표값과 거의 일치하는 훈련 예측값을 얻는 데 도움이 됩니다. 신경망이 예측 시점에서만 정규화되지 않은 값의 공간에서 예측값을 출력하도록 하려면 역정규화 계층(R2026a에서 추가됨)을 포함하십시오. R2026a 이전: 훈련을 안정화하려면 목표값을 수동으로 정규화한 다음 신경망을 훈련시키십시오.
LSTM 계층의 경우, 은닉 유닛의 개수와 출력 모드 "last"를 지정합니다.
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numResponses) inverseNormalizationLayer];
sequence-to-sequence 회귀를 위한 LSTM 신경망을 만들려면 sequence-to-one 회귀와 동일한 아키텍처를 사용하되 LSTM 계층의 출력 모드를 "sequence"로 설정합니다.
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="sequence") fullyConnectedLayer(numResponses) inverseNormalizationLayer];
sequence-to-sequence 회귀를 위한 LSTM 신경망을 훈련시키고 새 데이터에 대해 예측하는 방법을 보여주는 예제는 딥러닝을 사용한 sequence-to-sequence 회귀 항목을 참조하십시오.
비디오 분류 신경망
비디오 데이터나 의료 영상과 같이 영상으로 구성된 시퀀스를 포함하는 데이터를 위한 딥러닝 신경망을 만들려면 시퀀스 입력 계층을 사용하여 영상 시퀀스 입력값을 지정합니다.
계층을 지정하고 dlnetwork 객체를 만듭니다.
inputSize = [64 64 3];
filterSize = 5;
numFilters = 20;
numHiddenUnits = 200;
numClasses = 10;
layers = [
sequenceInputLayer(inputSize)
convolution2dLayer(filterSize,numFilters)
batchNormalizationLayer
reluLayer
lstmLayer(numHiddenUnits,OutputMode="last")
fullyConnectedLayer(numClasses)
softmaxLayer];
net = dlnetwork(layers);딥러닝 신경망을 비디오 분류를 위해 훈련시키는 방법을 보여주는 예제는 딥러닝을 사용하여 비디오 분류하기 항목을 참조하십시오.
심층 LSTM 신경망
LSTM 계층 앞에 출력 모드가 "sequence"인 LSTM 계층을 추가로 삽입하여 LSTM 신경망의 심도를 높일 수 있습니다. 과적합을 방지하기 위해 LSTM 계층 뒤에 드롭아웃 계층을 삽입할 수 있습니다.
sequence-to-label 분류 신경망의 경우, 마지막 LSTM 계층의 출력 모드가 "last"가 되어야 합니다.
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,OutputMode="sequence") dropoutLayer(0.2) lstmLayer(numHiddenUnits2,OutputMode="last") dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer];
sequence-to-sequence 분류 신경망의 경우, 마지막 LSTM 계층의 출력 모드가 "sequence"가 되어야 합니다.
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,OutputMode="sequence") dropoutLayer(0.2) lstmLayer(numHiddenUnits2,OutputMode="sequence") dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer];
계층
| 아이콘 | 계층 | 설명 |
|---|---|---|
| 시퀀스 입력 계층은 신경망에 시퀀스 데이터를 입력하고 데이터 정규화를 적용합니다. | |
| 임베딩 계층은 숫자형 인덱스를 숫자형 벡터로 변환합니다. 여기서 인덱스는 이산 데이터에 대응됩니다. | |
| LSTM 계층은 시계열 및 시퀀스 데이터에서 시간 스텝 간의 장기 종속성을 학습하는 RNN 계층입니다. | ||
| 투영 LSTM 계층은 투영된 학습 가능 가중치를 사용하여 시계열 및 시퀀스 데이터에서 시간 스텝 간의 장기 종속성을 학습하는 RNN 계층입니다. | ||
| BiLSTM(양방향 장단기 기억) 계층은 시계열 또는 시퀀스 데이터의 시간 스텝 간의 양방향 장기 종속성을 학습하는 RNN 계층입니다. 이러한 종속성은 RNN이 각 시간 스텝에서 전체 시계열로부터 학습하도록 하려는 경우에 유용할 수 있습니다. | ||
| GRU 계층은 시계열 및 시퀀스 데이터에서 시간 스텝 간의 종속성을 학습하는 RNN 계층입니다. | ||
| 투영 GRU 계층은 투영된 학습 가능 가중치를 사용하여 시계열 및 시퀀스 데이터에서 시간 스텝 간의 종속성을 학습하는 RNN 계층입니다. | ||
| 1차원 컨벌루션 계층은 1차원 입력에 슬라이딩 컨벌루션 필터를 적용합니다. | ||
| 전치 1차원 컨벌루션 계층은 1차원 특징 맵을 업샘플링합니다. | ||
| 1차원 최댓값 풀링 계층은 입력을 1차원 풀링 영역으로 나누어 다운샘플링을 수행한 다음 각 영역의 최댓값 계산을 수행합니다. | ||
| 1차원 평균값 풀링 계층은 입력을 1차원 풀링 영역으로 나누어 다운샘플링을 수행한 다음 각 영역의 평균값 계산을 수행합니다. | ||
| 1차원 전역 최댓값 풀링 계층은 입력의 시간 또는 공간 차원의 최댓값을 출력하여 다운샘플링을 수행합니다. | ||
| 평탄화 계층은 입력의 공간 차원을 채널 차원으로 축소합니다. | ||
| 단어 임베딩 계층은 단어 인덱스를 벡터로 매핑합니다. | |
| 핍홀 LSTM 계층은 LSTM 계층의 변형으로, 게이트 계산은 계층 셀 상태를 사용합니다. |

분류, 예측 및 전망
새 데이터를 사용하여 예측을 수행하려면 minibatchpredict 함수를 사용하십시오. 예측된 분류 점수를 레이블로 변환하려면 scores2label을 사용합니다.
LSTM 신경망은 각 예측 사이의 신경망 상태를 기억할 수 있습니다. RNN 상태는 전체 시계열을 미리 갖고 있지 않거나 긴 시계열에 대해 여러 예측을 수행하려는 경우에 유용합니다.
시계열의 각 부분을 예측 및 분류하고 RNN 상태를 업데이트하려면 predict 함수를 사용하고 신경망 상태도 반환 및 업데이트하십시오. 각 예측 사이의 RNN 상태를 재설정하려면 resetState를 사용하십시오.
시퀀스의 미래의 시간 스텝을 전망하는 방법을 보여주는 예제는 딥러닝을 사용한 시계열 전망 항목을 참조하십시오.
시퀀스 채우기와 줄이기
LSTM 신경망은 다양한 시퀀스 길이를 갖는 입력 데이터를 지원합니다. 신경망에 데이터를 통과시키면 각 미니 배치의 모든 시퀀스가 지정된 길이를 갖도록 시퀀스가 채워지거나 잘립니다. SequenceLength 및 SequencePaddingValue 훈련 옵션을 사용하여 시퀀스 길이와 시퀀스를 채우는 데 사용되는 값을 지정할 수 있습니다.
신경망을 훈련시킨 후에는 minibatchpredict 함수를 사용할 때와 동일한 미니 배치 크기와 채우기 옵션을 사용할 수 있습니다.
시퀀스를 길이로 정렬하기
시퀀스를 채우거나 자를 때 사용되는 채우기 양이나 버려지는 데이터를 줄이려면 시퀀스 길이를 기준으로 데이터를 정렬해 보십시오. 첫 번째 차원이 시간 스텝에 대응되는 시퀀스의 경우, 시퀀스 길이를 기준으로 데이터를 정렬하려면 먼저 cellfun을 사용하여 각 시퀀스에 size(X,1)을 적용하여 각 시퀀스의 열 개수를 가져옵니다. 그런 다음 sort를 사용하여 시퀀스 길이를 정렬하고, 두 번째 출력값을 사용하여 원래 시퀀스를 재정렬합니다.
sequenceLengths = cellfun(@(X) size(X,1), XTrain); [sequenceLengthsSorted,idx] = sort(sequenceLengths); XTrain = XTrain(idx);

시퀀스 채우기
SequenceLength 훈련 또는 예측 옵션이 "longest"인 경우, 미니 배치의 모든 시퀀스가 미니 배치에 있는 가장 긴 시퀀스와 동일한 길이를 갖도록 소프트웨어가 시퀀스를 채웁니다. 이는 디폴트 옵션입니다.

시퀀스 자르기
SequenceLength 훈련 또는 예측 옵션이 "shortest"인 경우, 미니 배치의 모든 시퀀스가 미니 배치에 있는 가장 짧은 시퀀스와 동일한 길이를 갖도록 소프트웨어가 시퀀스를 자릅니다. 시퀀스의 나머지 데이터는 버려집니다.

채우기 방향 지정하기
채우기와 자르기의 위치는 훈련, 분류 및 예측 정확도에 영향을 줄 수 있습니다. SequencePaddingDirection 훈련 옵션을 "left" 또는 "right"로 설정해 보고 무엇이 데이터에 가장 적합한지 살펴보십시오.
순환 계층은 시퀀스 데이터를 한 번에 하나의 시간 스텝씩 처리합니다. 따라서 순환 계층의 OutputMode 속성이 "last"인 경우 마지막 시간 스텝에서의 채우기가 계층 출력에 부정적인 영향을 줄 수 있습니다. 시퀀스 데이터를 왼쪽에서 채우거나 자르려면 SequencePaddingDirection 이름-값 인수를 "left"로 설정하십시오.
sequence-to-sequence 신경망의 경우(각 순환 계층의 OutputMode 속성이 "sequence"인 경우), 첫 시간 스텝들에서의 채우기가 앞쪽에 있는 시간 스텝들의 예측에 부정적인 영향을 줄 수 있습니다. 시퀀스 데이터를 오른쪽에서 채우거나 자르려면 SequencePaddingDirection 이름-값 인수를 "right"로 설정하십시오.


시퀀스 데이터 정규화하기
0이 중심이 되는 정규화를 사용하여 훈련 시점에 자동으로 훈련 데이터의 중심을 조정하려면 sequenceInputLayer의 Normalization 옵션을 "zerocenter"로 설정하십시오. 또는 먼저 모든 시퀀스의 특징별 평균값과 표준편차를 계산하여 시퀀스 데이터를 정규화할 수도 있습니다. 그런 다음 각 훈련 관측값에서 평균값을 빼고 표준편차로 나눕니다.
mu = mean([XTrain{:}],1);
sigma = std([XTrain{:}],0,1);
XTrain = cellfun(@(X) (X-mu)./sigma,XTrain,UniformOutput=false);메모리에 담을 수 없는 큰 데이터
데이터가 너무 커서 메모리에 담을 수 없거나 데이터 배치를 읽을 때 특정 연산을 수행하려면 시퀀스, 시계열 및 신호 데이터를 위한 데이터저장소를 사용합니다.
자세한 내용은 메모리에 다 담을 수 없는 큰 시퀀스 데이터를 사용하여 신경망 훈련시키기 항목과 Classify Out-of-Memory Text Data Using Deep Learning 항목을 참조하십시오.
시각화
minibatchpredict 함수를 사용하여 활성화를 추출하고 Outputs 인수를 설정하여, LSTM 신경망이 시퀀스 데이터와 시계열 데이터에서 학습한 특징을 검사하고 시각화합니다. 자세한 내용은 LSTM 신경망의 활성화 시각화 항목을 참조하십시오.
LSTM 계층 아키텍처
다음 도식은 입력값 와 출력값 를 갖고 시간 스텝이 T인 LSTM 계층을 통과하는 데이터 흐름을 보여줍니다. 이 도식에서 는 출력값(은닉 상태라고도 함)을 나타내고 는 시간 스텝 t에서의 셀 상태를 나타냅니다.
전체 시퀀스를 출력하는 경우 계층은 , …, 를 출력하며 이는 , …, 와 동일합니다. 마지막 시간 스텝만 출력하는 경우 계층은 를 출력하여 이는 와 동일합니다. 출력값에 있는 채널의 개수는 LSTM 계층의 은닉 유닛의 개수와 일치합니다.
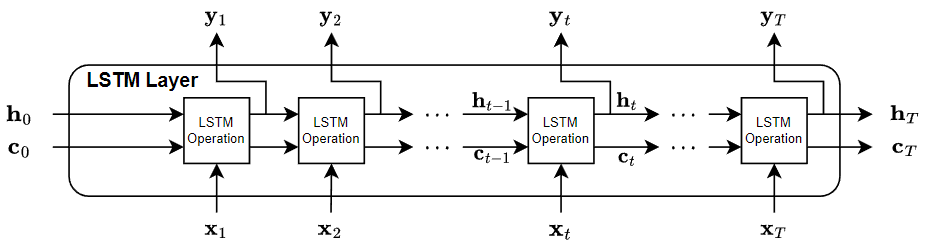
첫 번째 LSTM 연산은 RNN의 초기 상태와 시퀀스의 첫 번째 시간 스텝을 사용하여 첫 번째 출력값과 업데이트된 셀 상태를 계산합니다. 시간 스텝 t에서, 이 연산은 RNN 의 현재 상태와 시퀀스의 다음 시간 스텝을 사용하여 출력값과 업데이트된 셀 상태 를 계산합니다.
계층의 상태는 은닉 상태(출력 상태)와 셀 상태로 구성됩니다. 시간 스텝 t에서의 은닉 상태는 이 시간 스텝에 대한 LSTM 계층의 출력값을 포함합니다. 셀 상태는 이전 시간 스텝에서 학습한 정보를 포함합니다. 이 계층은 각 시간 스텝에서 셀 상태에 정보를 추가하거나 셀 상태로부터 정보를 제거합니다. 계층은 게이트를 사용하여 이러한 업데이트를 제어합니다.
다음 컴포넌트는 계층의 셀 상태와 은닉 상태를 제어합니다.
| 컴포넌트 | 목적 |
|---|---|
| 입력 게이트(i) | 셀 상태 업데이트의 수준 제어 |
| 망각 게이트(f) | 셀 상태 재설정(망각)의 수준 제어 |
| 셀 후보(g) | 셀 상태에 정보 추가 |
| 출력 게이트(o) | 은닉 상태에 추가되는 셀 상태의 수준 제어 |
다음 도식은 시간 스텝 t에서의 데이터 흐름을 보여줍니다. 이 도식은 게이트가 셀 상태와 은닉 상태를 망각, 업데이트, 출력하는 방식을 보여줍니다.

LSTM 계층의 학습 가능한 가중치는 입력 가중치 W(InputWeights), 순환 가중치 R(RecurrentWeights), 편향 b(Bias)입니다. 행렬 W, R, b는 각각 각 컴포넌트의 입력 가중치 결합, 순환 가중치 결합, 편향 결합입니다. 계층은 다음 수식에 따라 행렬을 결합합니다.
여기서 i, f, g, o는 입력 게이트, 망각 게이트, 셀 후보, 출력 게이트를 나타냅니다.
시간 스텝 t에서의 셀 상태는 다음과 같이 표현됩니다.
여기서 는 아다마르 곱(벡터의 요소별 곱셈)을 나타냅니다.
시간 스텝 t에서의 은닉 상태는 다음과 같이 표현됩니다.
여기서 는 상태 활성화 함수를 나타냅니다. 기본적으로 lstmLayer 함수는 쌍곡탄젠트 함수(tanh)를 사용하여 상태 활성화 함수를 계산합니다.
다음 수식은 시간 스텝 t에서의 컴포넌트를 설명합니다.
| 컴포넌트 | 식 |
|---|---|
| 입력 게이트 | |
| 망각 게이트 | |
| 셀 후보 | |
| 출력 게이트 |
위 식에서 는 게이트 활성화 함수를 나타냅니다. 기본적으로 lstmLayer 함수는 으로 표현되는 시그모이드 함수를 사용하여 게이트 활성화 함수를 계산합니다.
참고 문헌
[1] Hochreiter, S., and J. Schmidhuber. "Long short-term memory." Neural computation. Vol. 9, Number 8, 1997, pp.1735–1780.
참고 항목
sequenceInputLayer | lstmLayer | bilstmLayer | gruLayer | dlnetwork | minibatchpredict | predict | scores2label | flattenLayer | wordEmbeddingLayer (Text Analytics Toolbox)