문서의 LDA 토픽 확률 시각화하기
이 예제에서는 LDA(잠재 디리클레 할당) 토픽 모델을 사용하여 문서의 토픽 확률을 시각화하는 방법을 보여줍니다.
LDA 모델은 문서 모음에서 기저 토픽을 발견하고 토픽 내 단어 확률을 추정하는 토픽 모델입니다. LDA 모델을 사용하여 문서를 토픽 확률로 구성된 벡터(토픽 혼합이라고도 함)로 변환할 수 있습니다. 누적형 막대 차트를 사용하여 LDA 토픽을 시각화할 수 있습니다.
LDA 모델 불러오기
다양한 고장 이벤트를 자세히 설명하는 공장 보고서 데이터 세트를 사용하여 훈련된 LDA 모델 factoryReportsLDAModel을 불러옵니다. LDA 모델을 텍스트 데이터 모음에 피팅하는 방법을 보여주는 예제는 토픽 모델을 사용하여 텍스트 데이터 분석하기 항목을 참조하십시오.
load factoryReportsLDAModel
mdlmdl =
ldaModel with properties:
NumTopics: 7
WordConcentration: 1
TopicConcentration: 0.5755
CorpusTopicProbabilities: [0.1587 0.1573 0.1551 0.1534 0.1340 0.1322 0.1093]
DocumentTopicProbabilities: [480×7 double]
TopicWordProbabilities: [158×7 double]
Vocabulary: ["item" "occasionally" "get" "stuck" "scanner" "spool" "loud" "rattling" "sound" "come" "assembler" "piston" "cut" "power" "start" "plant" "capacitor" "mixer" … ]
TopicOrder: 'initial-fit-probability'
FitInfo: [1×1 struct]
워드 클라우드를 사용하여 토픽 시각화하기
wordcloud 함수를 사용하여 토픽을 시각화합니다.
numTopics = mdl.NumTopics; figure t = tiledlayout("flow"); title(t,"LDA Topics") for i = 1:numTopics nexttile wordcloud(mdl,i); title("Topic " + i) end

문서의 토픽 혼합 보기
모델을 피팅할 때 사용한 것과 동일한 전처리 함수를 사용하여 앞에서 나오지 않은 문서 세트에 대해 토큰화된 문서로 구성된 배열을 만듭니다.
이 예제의 전처리 함수 섹션에 나오는 함수 preprocessText는 다음 단계를 순서대로 수행합니다.
tokenizedDocument를 사용하여 텍스트를 토큰화합니다.normalizeWords를 사용하여 단어의 표제어를 추출합니다.erasePunctuation을 사용하여 문장 부호를 지웁니다.removeStopWords를 사용하여 불용어 목록(예: "and", "of", "the")을 제거합니다.removeShortWords를 사용하여 2자 이하로 이루어진 단어를 제거합니다.removeLongWords를 사용하여 15자 이상으로 이루어진 단어를 제거합니다.
preprocessText 함수를 사용하여 분석할 텍스트 데이터를 준비합니다.
str = [
"Coolant is pooling underneath assembler."
"Sorter blows fuses at start up."
"There are some very loud rattling sounds coming from the assembler."];
documents = preprocessText(str);transform 함수를 사용하여 문서를 토픽 확률로 구성된 벡터로 변환합니다. 매우 짧은 문서에서는 토픽 혼합이 문서 내용을 강하게 표현하지 못할 수 있습니다.
topicMixtures = transform(mdl,documents);
첫 번째 토픽 혼합을 막대 차트에 시각화하고 각 토픽에서 상위 3개 단어를 사용하여 막대에 레이블을 지정합니다.
numTopics = mdl.NumTopics; for i = 1:numTopics top = topkwords(mdl,3,i); topWords(i) = join(top.Word,", "); end figure bar(categorical(topWords),topicMixtures(1,:)) xlabel("Topic") ylabel("Probability") title("Document Topic Probabilities")
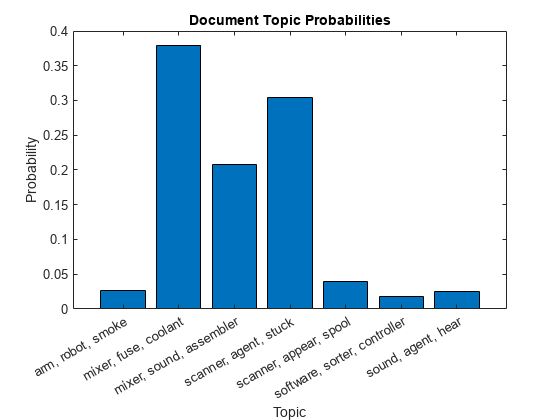
각 문서의 토픽 비율을 시각화하거나 여러 토픽 혼합을 시각화하려면 누적형 막대 차트를 사용합니다.
figure barh(topicMixtures,"stacked") title("Topic Mixtures") xlabel("Topic Probability") ylabel("Document") legend(topWords, ... Location="southoutside", ... NumColumns=2)
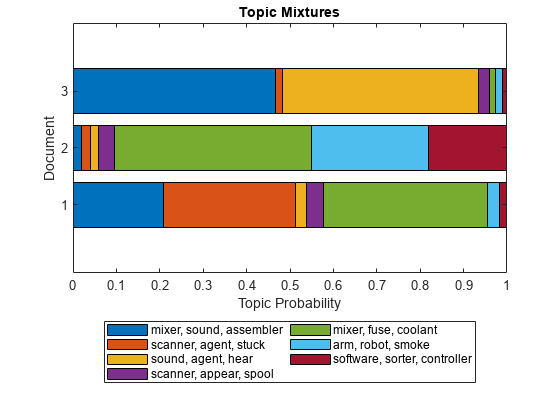
누적형 막대 차트의 영역은 해당 토픽에 속하는 문서의 비율을 나타냅니다.
전처리 함수
함수 preprocessText는 다음 단계를 순서대로 수행합니다.
tokenizedDocument를 사용하여 텍스트를 토큰화합니다.normalizeWords를 사용하여 단어의 표제어를 추출합니다.erasePunctuation을 사용하여 문장 부호를 지웁니다.removeStopWords를 사용하여 불용어 목록(예: "and", "of", "the")을 제거합니다.removeShortWords를 사용하여 2자 이하로 이루어진 단어를 제거합니다.removeLongWords를 사용하여 15자 이상으로 이루어진 단어를 제거합니다.
function documents = preprocessText(textData) % Tokenize the text. documents = tokenizedDocument(textData); % Lemmatize the words. documents = addPartOfSpeechDetails(documents); documents = normalizeWords(documents,Style="lemma"); % Erase punctuation. documents = erasePunctuation(documents); % Remove a list of stop words. documents = removeStopWords(documents); % Remove words with 2 or fewer characters, and words with 15 or greater % characters. documents = removeShortWords(documents,2); documents = removeLongWords(documents,15); end
참고 항목
tokenizedDocument | fitlda | ldaModel | wordcloud