LDA 모델을 사용하여 문서 군집 시각화하기
이 예제에서는 LDA(잠재 디리클레 할당) 토픽 모델과 t-SNE 플롯을 사용하여 문서 군집을 시각화하는 방법을 보여줍니다.
LDA 모델은 문서 모음에서 기저 토픽을 발견하고 토픽 내 단어 확률을 추정하는 토픽 모델입니다. 토픽별 단어 확률로 구성된 벡터는 토픽의 특성을 나타냅니다. LDA 모델을 사용하여 토픽 혼합이라고도 하는 문서별 토픽 확률을 비교하면 문서 유사도를 평가할 수 있습니다.
LDA 모델 불러오기
다양한 고장 이벤트를 자세히 설명하는 공장 보고서 데이터 세트를 사용하여 훈련된 LDA 모델 factoryReportsLDAModel을 불러옵니다. LDA 모델을 텍스트 데이터 모음에 피팅하는 방법을 보여주는 예제는 토픽 모델을 사용하여 텍스트 데이터 분석하기 항목을 참조하십시오.
load factoryReportsLDAModel
mdlmdl =
ldaModel with properties:
NumTopics: 7
WordConcentration: 1
TopicConcentration: 0.5755
CorpusTopicProbabilities: [0.1587 0.1573 0.1551 0.1534 0.1340 0.1322 0.1093]
DocumentTopicProbabilities: [480×7 double]
TopicWordProbabilities: [158×7 double]
Vocabulary: [1×158 string]
TopicOrder: 'initial-fit-probability'
FitInfo: [1×1 struct]
워드 클라우드를 사용하여 토픽을 시각화합니다.
numTopics = mdl.NumTopics; figure tiledlayout("flow") title("LDA Topics") for i = 1:numTopics nexttile wordcloud(mdl,i); title("Topic " + i) end

t-SNE를 사용하여 문서 군집 시각화하기
t-SNE(t-분포 확률적 이웃 임베딩) 알고리즘은 고차원 벡터를 2차원 공간에 투영합니다. 이 임베딩을 통해 고차원 벡터 간의 유사도를 쉽게 시각화할 수 있습니다. t-SNE 알고리즘에 따라 문서 토픽 혼합을 플로팅함으로써 유사한 문서의 군집을 시각화할 수 있습니다.
tsne 함수를 사용하여 DocumentTopicProbabilties 속성의 토픽 혼합을 2차원 공간에 투영합니다.
XY = tsne(mdl.DocumentTopicProbabilities);
플롯 그룹을 위해 각 문서의 상위 토픽을 식별합니다.
[~,topTopics] = max(mdl.DocumentTopicProbabilities,[],2);
플롯 레이블을 위해 각 토픽의 상위 3개 단어를 찾습니다.
for i = 1:numTopics top = topkwords(mdl,3,i); topWords(i) = join(top.Word,", "); end
gscatter 함수를 사용하여 투영된 토픽 혼합을 플로팅합니다. 상위 토픽을 그룹화 변수로 지정하고 각 토픽에 대한 상위 단어로 범례를 표시합니다.
figure gscatter(XY(:,1),XY(:,2),topTopics) title("Topic Mixtures") legend(topWords, ... Location="southoutside", ... NumColumns=2)
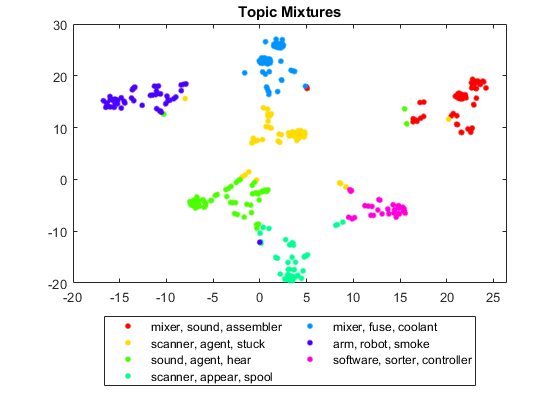
t-SNE 플롯은 원래의 고차원 데이터에서 발생하는 군집을 강조 표시합니다.
참고 항목
tokenizedDocument | fitlda | ldaModel | wordcloud | documentEmbedding