LDA 토픽과 문서 레이블 간의 상관 시각화하기
이 예제에서는 LDA(잠재 디리클레 할당) 토픽 모델을 피팅하고 LDA 토픽과 문서 레이블 간의 상관을 시각화하는 방법을 보여줍니다.
LDA(잠재 디리클레 할당) 모델은 문서 모음에서 기저 토픽을 발견하고 토픽 내 단어 확률을 추정하는 토픽 모델입니다. LDA 모델 피팅 시 레이블이 지정된 데이터가 필요하지 않습니다. 하지만 평행좌표 플롯을 사용하여 피팅된 LDA 토픽과 문서 레이블 간의 상관을 시각화할 수 있습니다.
이 예제에서는 다양한 고장 이벤트를 자세히 설명하는 공장 보고서의 모음인 공장 보고서 데이터 세트로 LDA 모델을 피팅하고 LDA 토픽과 이 보고서 범주 간의 상관을 식별합니다.
텍스트 데이터 불러오기 및 추출하기
예제 데이터를 불러옵니다. factoryReports.csv 파일에는 각 이벤트에 대한 텍스트 설명과 범주 레이블이 포함된 공장 보고서가 들어 있습니다.
data = readtable("factoryReports.csv",TextType="string"); head(data)
ans=8×5 table
"Items are occasionally getting stuck in the scanner spools." "Mechanical Failure" "Medium" "Readjust Machine" 45
"Loud rattling and banging sounds are coming from assembler pistons." "Mechanical Failure" "Medium" "Readjust Machine" 35
"There are cuts to the power when starting the plant." "Electronic Failure" "High" "Full Replacement" 16200
"Fried capacitors in the assembler." "Electronic Failure" "High" "Replace Components" 352
"Mixer tripped the fuses." "Electronic Failure" "Low" "Add to Watch List" 55
"Burst pipe in the constructing agent is spraying coolant." "Leak" "High" "Replace Components" 371
"A fuse is blown in the mixer." "Electronic Failure" "Low" "Replace Components" 441
"Things continue to tumble off of the belt." "Mechanical Failure" "Low" "Readjust Machine" 38
Description 필드에서 텍스트 데이터를 추출합니다.
textData = data.Description; textData(1:10)
ans = 10×1 string array
"Items are occasionally getting stuck in the scanner spools."
"Loud rattling and banging sounds are coming from assembler pistons."
"There are cuts to the power when starting the plant."
"Fried capacitors in the assembler."
"Mixer tripped the fuses."
"Burst pipe in the constructing agent is spraying coolant."
"A fuse is blown in the mixer."
"Things continue to tumble off of the belt."
"Falling items from the conveyor belt."
"The scanner reel is split, it will soon begin to curve."
Category 필드에서 레이블을 추출합니다.
labels = data.Category;
분석할 텍스트 데이터 준비하기
분석에 사용할 수 있도록 텍스트 데이터를 토큰화하고 전처리하는 함수를 만듭니다. 이 예제의 전처리 함수 섹션에 나오는 함수 preprocessText는 다음 단계를 순서대로 수행합니다.
tokenizedDocument를 사용하여 텍스트를 토큰화합니다.normalizeWords를 사용하여 단어의 표제어를 추출합니다.erasePunctuation을 사용하여 문장 부호를 지웁니다.removeStopWords를 사용하여 불용어 목록(예: "and", "of", "the")을 제거합니다.removeShortWords를 사용하여 2자 이하로 이루어진 단어를 제거합니다.removeLongWords를 사용하여 15자 이상으로 이루어진 단어를 제거합니다.
preprocessText 함수를 사용하여 분석할 텍스트 데이터를 준비합니다.
documents = preprocessText(textData); documents(1:5)
ans = 5×1 tokenizedDocument array with properties:
6 tokens: item occasionally get stuck scanner spool
7 tokens: loud rattling bang sound come assembler piston
4 tokens: cut power start plant
3 tokens: fry capacitor assembler
3 tokens: mixer trip fuse
토큰화된 문서에서 bag-of-words 모델을 만듭니다.
bag = bagOfWords(documents)
bag = bagOfWords with properties:
Counts: [480×338 double]
Vocabulary: [1×338 string]
NumWords: 338
NumDocuments: 480
총 2회 이하로 나타나는 단어를 bag-of-words 모델에서 제거합니다. bag-of-words 모델에서 단어를 포함하지 않는 모든 문서를 제거합니다.
bag = removeInfrequentWords(bag,2); bag = removeEmptyDocuments(bag)
bag = bagOfWords with properties:
Counts: [480×158 double]
Vocabulary: [1×158 string]
NumWords: 158
NumDocuments: 480
LDA 모델 피팅하기
7개 토픽으로 LDA 모델을 피팅합니다. 토픽 수를 선택하는 방법을 보여주는 예제는 LDA 모델의 토픽 수 선택하기 항목을 참조하십시오. 세부 정보가 출력되지 않도록 Verbose 옵션을 0으로 설정합니다. 재현성을 위해 rng를 "default"로 설정합니다.
rng("default")
numTopics = 7;
mdl = fitlda(bag,numTopics,Verbose=0);대규모 데이터 세트가 있는 경우 확률적 근사 변분 베이즈 솔버는 일반적으로 전달되는 데이터가 적을 때 양호한 모델을 피팅할 수 있으므로 더 적합합니다. fitlda(축소된 Gibbs 샘플링)용 디폴트 솔버는 더 정확하지만 실행 시간이 오래 걸릴 수 있습니다. 확률적 근사 변분 베이즈를 사용하려면 Solver 옵션을 "savb"로 설정하십시오. LDA 솔버 비교 방법을 보여주는 예제는 Compare LDA Solvers 항목을 참조하십시오.
워드 클라우드를 사용하여 토픽을 시각화합니다.
figure t = tiledlayout("flow"); title(t,"LDA Topics") for i = 1:numTopics nexttile wordcloud(mdl,i); title("Topic " + i) end

토픽과 문서 레이블 간의 상관 시각화하기
각 문서 레이블에 대한 평균 토픽 확률을 플로팅하여 LDA 토픽과 문서 레이블 간의 상관을 시각화합니다.
LDA 모델의 DocumentTopicProbabilities 속성에서 문서 토픽 혼합을 추출합니다.
topicMixtures = mdl.DocumentTopicProbabilities;
각 레이블이 있는 문서에 대해 평균 토픽 확률을 계산합니다.
[groups,groupNames] = findgroups(labels); numGroups = numel(groupNames); for i = 1:numGroups idx = groups == i; meanTopicProbabilities(i,:) = mean(topicMixtures(idx,:)); end
각 토픽에 대해 상위 3개 단어를 찾습니다.
numTopics = mdl.NumTopics; for i = 1:numTopics top = topkwords(mdl,3,i); topWords(i) = join(top.Word,", "); end
평행좌표 플롯을 사용하여 범주별 평균 토픽 확률을 플로팅합니다. 가독성을 위해 Figure를 만들고 Position 속성을 사용하여 Figure 너비를 늘립니다.
f = figure; f.Position(3) = 2*f.Position(3);
parallelplot 함수를 사용하여 범주별 평균 토픽 확률을 플로팅합니다. 입력 데이터를 정규화하지 않고 범주를 그룹으로 지정합니다. 좌표 눈금 레이블을 각 토픽의 상위 3개 단어로 설정합니다.
p = parallelplot(meanTopicProbabilities, ... GroupData=groupNames, ... DataNormalization="none"); p.CoordinateTickLabels = topWords; xlabel("LDA Topic") ylabel("Mean Topic Probability") title("LDA Topic and Document Label Correlations")
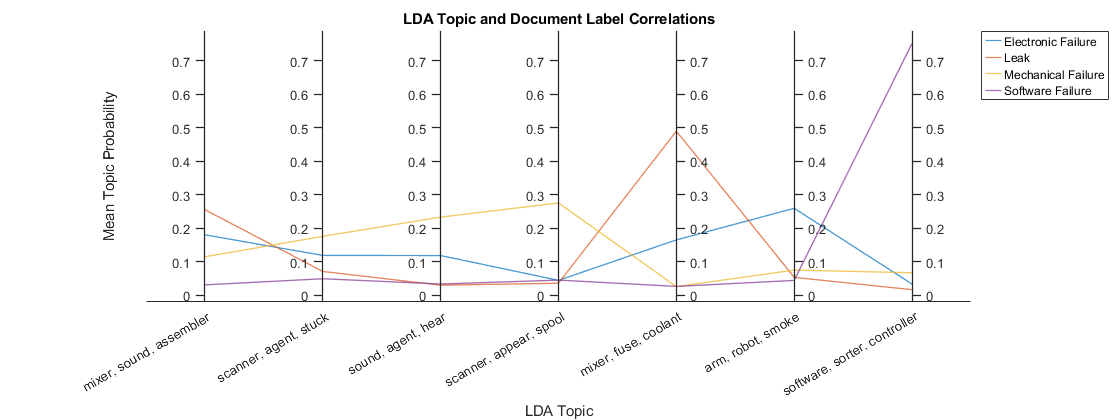
평행좌표 플롯에서 LDA 토픽과 문서 레이블 간의 상관을 강조 표시합니다. 높은 피크는 해당 토픽과 문서 레이블 간의 강한 상관을 나타냅니다.
전처리 함수
함수 preprocessText는 다음 단계를 순서대로 수행합니다.
tokenizedDocument를 사용하여 텍스트를 토큰화합니다.normalizeWords를 사용하여 단어의 표제어를 추출합니다.erasePunctuation을 사용하여 문장 부호를 지웁니다.removeStopWords를 사용하여 불용어 목록(예: "and", "of", "the")을 제거합니다.removeShortWords를 사용하여 2자 이하로 이루어진 단어를 제거합니다.removeLongWords를 사용하여 15자 이상으로 이루어진 단어를 제거합니다.
function documents = preprocessText(textData) % Tokenize the text. documents = tokenizedDocument(textData); % Lemmatize the words. documents = addPartOfSpeechDetails(documents); documents = normalizeWords(documents,'Style','lemma'); % Erase punctuation. documents = erasePunctuation(documents); % Remove a list of stop words. documents = removeStopWords(documents); % Remove words with 2 or fewer characters, and words with 15 or greater % characters. documents = removeShortWords(documents,2); documents = removeLongWords(documents,15); end
참고 항목
tokenizedDocument | fitlda | ldaModel | wordcloud