ldaModel
LDA 모델
설명
LDA(잠재 디리클레 할당) 모델은 문서 모음에서 기저 토픽을 발견하고 토픽 내 단어 확률을 추정하는 토픽 모델입니다. 이 모델이 bag-of-n-grams 모델을 사용하여 피팅된 경우 소프트웨어는 n-gram을 개별 단어로 처리합니다.
생성
fitlda 함수를 사용하여 LDA 모델을 만듭니다.
속성
객체 함수
logp | Document log-probabilities and goodness of fit of LDA model |
predict | Predict top LDA topics of documents |
resume | Resume fitting LDA model |
topkwords | bag-of-words 모델 또는 LDA 토픽에서 가장 중요한 단어 |
transform | Transform documents into lower-dimensional space |
wordcloud | 텍스트, bag-of-words 모델, bag-of-n-grams 모델 또는 LDA 모델에서 워드 클라우드 차트 만들기 |
예제
이 예제에서 결과를 재현하기 위해 rng를 'default'로 설정합니다.
rng('default')예제 데이터를 불러옵니다. 파일 sonnetsPreprocessed.txt에는 셰익스피어 소네트의 전처리된 버전이 들어 있습니다. 파일에는 한 줄에 하나씩 소네트가 들어 있으며 단어가 공백으로 구분되어 있습니다. sonnetsPreprocessed.txt에서 텍스트를 추출하고, 추출한 텍스트를 새 줄 문자에서 문서로 분할한 후 그 문서를 토큰화합니다.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);bagOfWords를 사용하여 bag-of-words 모델을 만듭니다.
bag = bagOfWords(documents)
bag =
bagOfWords with properties:
Counts: [154×3092 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" "contracted" … ]
NumWords: 3092
NumDocuments: 154
4개 토픽으로 LDA 모델을 피팅합니다.
numTopics = 4; mdl = fitlda(bag,numTopics)
Initial topic assignments sampled in 0.263378 seconds. ===================================================================================== | Iteration | Time per | Relative | Training | Topic | Topic | | | iteration | change in | perplexity | concentration | concentration | | | (seconds) | log(L) | | | iterations | ===================================================================================== | 0 | 0.17 | | 1.215e+03 | 1.000 | 0 | | 1 | 0.02 | 1.0482e-02 | 1.128e+03 | 1.000 | 0 | | 2 | 0.02 | 1.7190e-03 | 1.115e+03 | 1.000 | 0 | | 3 | 0.01 | 4.3796e-04 | 1.118e+03 | 1.000 | 0 | | 4 | 0.01 | 9.4193e-04 | 1.111e+03 | 1.000 | 0 | | 5 | 0.01 | 3.7079e-04 | 1.108e+03 | 1.000 | 0 | | 6 | 0.01 | 9.5777e-05 | 1.107e+03 | 1.000 | 0 | =====================================================================================
mdl =
ldaModel with properties:
NumTopics: 4
WordConcentration: 1
TopicConcentration: 1
CorpusTopicProbabilities: [0.2500 0.2500 0.2500 0.2500]
DocumentTopicProbabilities: [154×4 double]
TopicWordProbabilities: [3092×4 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" … ]
TopicOrder: 'initial-fit-probability'
FitInfo: [1×1 struct]
워드 클라우드를 사용하여 토픽을 시각화합니다.
figure for topicIdx = 1:4 subplot(2,2,topicIdx) wordcloud(mdl,topicIdx); title("Topic: " + topicIdx) end
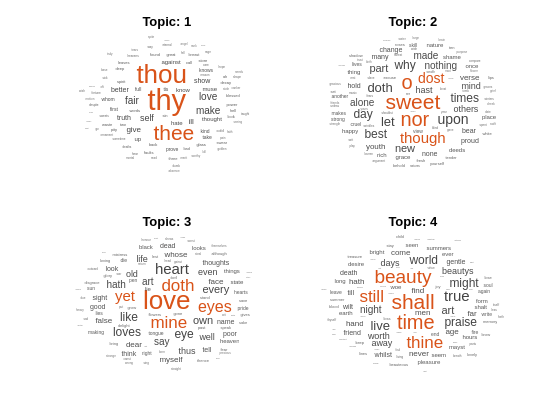
LDA 토픽에서 확률이 가장 높은 단어의 테이블을 만듭니다.
이 결과를 재현하기 위해 rng를 'default'로 설정합니다.
rng('default')예제 데이터를 불러옵니다. 파일 sonnetsPreprocessed.txt에는 셰익스피어 소네트의 전처리된 버전이 들어 있습니다. 파일에는 한 줄에 하나씩 소네트가 들어 있으며 단어가 공백으로 구분되어 있습니다. sonnetsPreprocessed.txt에서 텍스트를 추출하고, 추출한 텍스트를 새 줄 문자에서 문서로 분할한 후 그 문서를 토큰화합니다.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);bagOfWords를 사용하여 bag-of-words 모델을 만듭니다.
bag = bagOfWords(documents);
20개 토픽으로 LDA 모델을 피팅합니다. 세부 정보가 출력되지 않도록 'Verbose'를 0으로 설정합니다.
numTopics = 20;
mdl = fitlda(bag,numTopics,'Verbose',0);첫 번째 토픽에서 상위 20개 단어를 찾습니다.
k = 20; topicIdx = 1; tbl = topkwords(mdl,k,topicIdx)
tbl=20×2 table
"eyes" 0.1116
"beauty" 0.0578
"hath" 0.0558
"still" 0.0498
"true" 0.0438
"mine" 0.0339
"find" 0.0319
"black" 0.0259
"look" 0.0239
"tis" 0.0239
"kind" 0.0219
"seen" 0.0219
"found" 0.0179
"sin" 0.0159
⋮
첫 번째 토픽에서 상위 20개 단어를 찾고 점수에 역 평균 스케일링을 사용합니다.
tbl = topkwords(mdl,k,topicIdx,'Scaling','inversemean')
tbl=20×2 table
"eyes" 1.2718
"beauty" 0.5902
"hath" 0.5692
"still" 0.5027
"true" 0.4372
"mine" 0.3276
"find" 0.3254
"black" 0.2593
"tis" 0.2375
"look" 0.2252
"kind" 0.2159
"seen" 0.2159
"found" 0.1733
"sin" 0.1522
⋮
스케일링된 점수를 크기 데이터로 사용하여 워드 클라우드를 만듭니다.
figure wordcloud(tbl.Word,tbl.Score);

문서에서 LDA 모델을 피팅하는 데 사용된 문서 토픽 확률(토픽 혼합이라고도 함)을 구합니다.
이 결과를 재현하기 위해 rng를 'default'로 설정합니다.
rng('default')예제 데이터를 불러옵니다. 파일 sonnetsPreprocessed.txt에는 셰익스피어 소네트의 전처리된 버전이 들어 있습니다. 파일에는 한 줄에 하나씩 소네트가 들어 있으며 단어가 공백으로 구분되어 있습니다. sonnetsPreprocessed.txt에서 텍스트를 추출하고, 추출한 텍스트를 새 줄 문자에서 문서로 분할한 후 그 문서를 토큰화합니다.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);bagOfWords를 사용하여 bag-of-words 모델을 만듭니다.
bag = bagOfWords(documents);
20개 토픽으로 LDA 모델을 피팅합니다. 세부 정보가 출력되지 않도록 'Verbose'를 0으로 설정합니다.
numTopics = 20;
mdl = fitlda(bag,numTopics,'Verbose',0)mdl =
ldaModel with properties:
NumTopics: 20
WordConcentration: 1
TopicConcentration: 5
CorpusTopicProbabilities: [0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500]
DocumentTopicProbabilities: [154×20 double]
TopicWordProbabilities: [3092×20 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" … ] (1×3092 string)
TopicOrder: 'initial-fit-probability'
FitInfo: [1×1 struct]
훈련 데이터에서 첫 번째 문서의 토픽 확률을 표시합니다.
topicMixtures = mdl.DocumentTopicProbabilities; figure bar(topicMixtures(1,:)) title("Document 1 Topic Probabilities") xlabel("Topic Index") ylabel("Probability")

이 예제에서 결과를 재현하기 위해 rng를 'default'로 설정합니다.
rng('default')예제 데이터를 불러옵니다. 파일 sonnetsPreprocessed.txt에는 셰익스피어 소네트의 전처리된 버전이 들어 있습니다. 파일에는 한 줄에 하나씩 소네트가 들어 있으며 단어가 공백으로 구분되어 있습니다. sonnetsPreprocessed.txt에서 텍스트를 추출하고, 추출한 텍스트를 새 줄 문자에서 문서로 분할한 후 그 문서를 토큰화합니다.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);bagOfWords를 사용하여 bag-of-words 모델을 만듭니다.
bag = bagOfWords(documents)
bag =
bagOfWords with properties:
Counts: [154×3092 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" "contracted" … ]
NumWords: 3092
NumDocuments: 154
20개 토픽으로 LDA 모델을 피팅합니다.
numTopics = 20; mdl = fitlda(bag,numTopics)
Initial topic assignments sampled in 0.513255 seconds. ===================================================================================== | Iteration | Time per | Relative | Training | Topic | Topic | | | iteration | change in | perplexity | concentration | concentration | | | (seconds) | log(L) | | | iterations | ===================================================================================== | 0 | 0.04 | | 1.159e+03 | 5.000 | 0 | | 1 | 0.05 | 5.4884e-02 | 8.028e+02 | 5.000 | 0 | | 2 | 0.04 | 4.7400e-03 | 7.778e+02 | 5.000 | 0 | | 3 | 0.04 | 3.4597e-03 | 7.602e+02 | 5.000 | 0 | | 4 | 0.03 | 3.4662e-03 | 7.430e+02 | 5.000 | 0 | | 5 | 0.03 | 2.9259e-03 | 7.288e+02 | 5.000 | 0 | | 6 | 0.03 | 6.4180e-05 | 7.291e+02 | 5.000 | 0 | =====================================================================================
mdl =
ldaModel with properties:
NumTopics: 20
WordConcentration: 1
TopicConcentration: 5
CorpusTopicProbabilities: [0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500]
DocumentTopicProbabilities: [154×20 double]
TopicWordProbabilities: [3092×20 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" … ]
TopicOrder: 'initial-fit-probability'
FitInfo: [1×1 struct]
새 문서로 구성된 배열의 상위 토픽을 예측합니다.
newDocuments = tokenizedDocument([
"what's in a name? a rose by any other name would smell as sweet."
"if music be the food of love, play on."]);
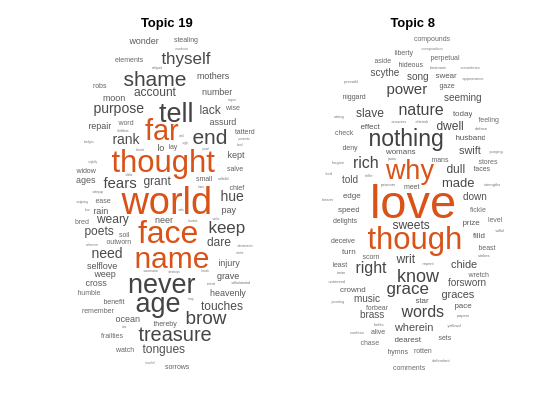
topicIdx = predict(mdl,newDocuments)topicIdx = 2×1
19
8
워드 클라우드를 사용하여 예측된 토픽을 시각화합니다.
figure subplot(1,2,1) wordcloud(mdl,topicIdx(1)); title("Topic " + topicIdx(1)) subplot(1,2,2) wordcloud(mdl,topicIdx(2)); title("Topic " + topicIdx(2))
세부 정보
LDA(잠재 디리클레 할당) 모델은 문서 모음에서 기저 토픽을 발견하고 토픽 내 단어 확률을 추정하는 문서 토픽 모델입니다. LDA는 단어 확률로 구성된 벡터 로 특징지어진 K개의 토픽에 대해 D개의 문서 모음을 토픽 혼합 로 모델링합니다. 이 모델은 토픽 혼합 , 토픽 가 각각 집중도 파라미터 와 를 포함하는 디리클레 분포를 따른다고 가정합니다.
토픽 혼합 는 길이가 K인 확률 벡터이며, 여기서 K는 토픽 개수입니다. 요소 는 토픽 i가 d번째 문서에서 나타날 확률입니다. 토픽 혼합은 ldaModel 객체의 DocumentTopicProbabilities 속성 행에 대응됩니다.
토픽 는 길이가 V인 확률 벡터이며, 여기서 V는 단어집의 단어 개수입니다. 요소 는 단어집의 v번째 단어가 i번째 토픽에 나타날 확률에 대응됩니다. 토픽 는 ldaModel 객체의 TopicWordProbabilities 속성 열에 대응됩니다.
토픽 와 토픽 혼합에 대한 디리클레 사전 확률 가 주어지면, LDA는 문서에 대해 다음과 같은 생성적 프로세스를 가정합니다.
토픽 혼합 를 샘플링합니다. 확률 변수 는 길이가 K인 확률 벡터이며, 여기서 K는 토픽 개수입니다.
문서 내 각 단어에 대해 다음이 적용됩니다.
토픽 인덱스 를 샘플링합니다. 확률 변수 z는 1부터 K까지의 정수이며, 여기서 K는 토픽 개수입니다.
단어 를 샘플링합니다. 확률 변수 w는 1부터 V까지의 정수이며, 여기서 V는 단어집의 단어 개수이고 단어집에서 대응되는 단어를 나타냅니다.
이 생성적 프로세스에서 단어 과 토픽 혼합 , 토픽 인덱스 가 있는 문서의 결합 분포는 다음에 의해 지정됩니다.
여기서 N은 문서의 단어 개수입니다. z에 대한 결합 분포를 합산한 다음 에 대해 적분하면 문서 w의 주변 분포가 다음과 같이 생성됩니다.
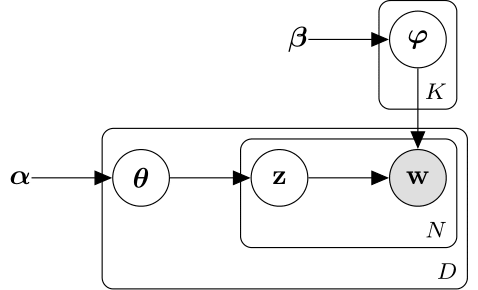
다음 도식은 LDA 모델을 확률적 그래픽 모델로 보여줍니다. 음영 처리된 노드는 관찰된 변수이고 음영 처리되지 않은 노드는 잠재 변수이며 윤곽선이 없는 노드는 모델 파라미터입니다. 화살표는 확률 변수 간의 종속성을 강조 표시하고 플레이트는 반복된 노드를 나타냅니다.
버전 내역
R2017b에 개발됨