wordcloud
텍스트, bag-of-words 모델, bag-of-n-grams 모델 또는 LDA 모델에서 워드 클라우드 차트 만들기
구문
설명
Text Analytics Toolbox™에서는 wordcloud(MATLAB®) 함수의 기능을 확장해 사용할 수 있습니다. string형 배열에서 직접 워드 클라우드를 만들고 bag-of-words 모델, bag-of-n-gram 모델, LDA 토픽에서도 워드 클라우드를 만들 수 있습니다. Text Analytics Toolbox가 설치되어 있지 않은 경우 wordcloud 항목을 참조하십시오.
wordcloud(은 str)str의 텍스트를 토큰화하고 전처리한 후 단어 빈도 수에 해당하는 크기로 단어를 표시하여 워드 클라우드 차트를 만듭니다. 이 구문은 한국어, 영어, 일본어, 독일어 텍스트를 지원합니다.
wordcloud(는 빈도 수를 사용하여 categorical형 배열 C)C의 요소에서 워드 클라우드 차트를 만듭니다.
wordcloud(___,는 하나 이상의 이름-값 쌍의 인수를 사용하여 Name,Value)WordCloudChart 속성을 추가로 지정합니다.
wordcloud(는 parent,___)parent에 의해 지정된 Figure, 패널 또는 탭에 워드 클라우드를 만듭니다.
wc = wordcloud(___)WordCloudChart 객체를 반환합니다. 워드 클라우드를 만든 후에 워드 클라우드의 속성을 수정하려면 wc를 사용합니다. 속성 목록은 WordCloudChart Properties 항목을 참조하십시오.
예제
extractFileText를 사용하여 sonnets.txt에서 텍스트를 추출하고 첫 번째 소네트의 텍스트를 표시합니다.
str = extractFileText("sonnets.txt"); extractBefore(str,"II")
ans =
"THE SONNETS
by William Shakespeare
I
From fairest creatures we desire increase,
That thereby beauty's rose might never die,
But as the riper should by time decease,
His tender heir might bear his memory:
But thou, contracted to thine own bright eyes,
Feed'st thy light's flame with self-substantial fuel,
Making a famine where abundance lies,
Thy self thy foe, to thy sweet self too cruel:
Thou that art now the world's fresh ornament,
And only herald to the gaudy spring,
Within thine own bud buriest thy content,
And tender churl mak'st waste in niggarding:
Pity the world, or else this glutton be,
To eat the world's due, by the grave and thee.
"
소네트의 단어들을 워드 클라우드로 표시합니다.
figure wordcloud(str);

예제 데이터를 불러옵니다. 파일 sonnetsPreprocessed.txt에는 셰익스피어 소네트의 전처리된 버전이 들어 있습니다. 파일에는 한 줄에 하나씩 소네트가 들어 있으며 단어가 공백으로 구분되어 있습니다. sonnetsPreprocessed.txt에서 텍스트를 추출하고, 추출한 텍스트를 새 줄 문자에서 문서로 분할한 후 그 문서를 토큰화합니다.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);워드 클라우드를 사용하여 문서를 시각화합니다.
figure wordcloud(documents);

예제 데이터를 불러옵니다. 파일 sonnetsPreprocessed.txt에는 셰익스피어 소네트의 전처리된 버전이 들어 있습니다. 파일에는 한 줄에 하나씩 소네트가 들어 있으며 단어가 공백으로 구분되어 있습니다. sonnetsPreprocessed.txt에서 텍스트를 추출하고, 추출한 텍스트를 새 줄 문자에서 문서로 분할한 후 그 문서를 토큰화합니다.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);bagOfWords를 사용하여 bag-of-words 모델을 만듭니다.
bag = bagOfWords(documents)
bag =
bagOfWords with properties:
Counts: [154×3092 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" "contracted" … ]
NumWords: 3092
NumDocuments: 154
워드 클라우드를 사용하여 bag-of-words 모델을 시각화합니다.
figure wordcloud(bag);

예제 데이터 sonnetsTable을 불러옵니다. 테이블 tbl은 변수 Word에 단어 목록을 포함하고 변수 Count에 그에 대응하는 빈도 수를 포함합니다.
load sonnetsTable
head(tbl) Word Count
___________ _____
{'''tis' } 1
{''Amen'' } 1
{''Fair' } 2
{''Gainst'} 1
{''Since' } 1
{''This' } 2
{''Thou' } 1
{''Thus' } 1
wordcloud를 사용하여 테이블 데이터를 플로팅합니다. 단어와 그에 대응하는 단어 크기를 각각 Word 변수와 Count 변수로 지정합니다.
figure wordcloud(tbl,'Word','Count'); title("Sonnets Word Cloud")

이 예제에서 결과를 재현하기 위해 rng를 'default'로 설정합니다.
rng('default')예제 데이터를 불러옵니다. 파일 sonnetsPreprocessed.txt에는 셰익스피어 소네트의 전처리된 버전이 들어 있습니다. 파일에는 한 줄에 하나씩 소네트가 들어 있으며 단어가 공백으로 구분되어 있습니다. sonnetsPreprocessed.txt에서 텍스트를 추출하고, 추출한 텍스트를 새 줄 문자에서 문서로 분할한 후 그 문서를 토큰화합니다.
filename = "sonnetsPreprocessed.txt";
str = extractFileText(filename);
textData = split(str,newline);
documents = tokenizedDocument(textData);bagOfWords를 사용하여 bag-of-words 모델을 만듭니다.
bag = bagOfWords(documents)
bag =
bagOfWords with properties:
Counts: [154×3092 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" "contracted" … ]
NumWords: 3092
NumDocuments: 154
20개 토픽으로 LDA 모델을 피팅합니다. 세부 정보가 출력되지 않도록 'Verbose'를 0으로 설정합니다.
mdl = fitlda(bag,20,'Verbose',0)mdl =
ldaModel with properties:
NumTopics: 20
WordConcentration: 1
TopicConcentration: 5
CorpusTopicProbabilities: [0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500 0.0500]
DocumentTopicProbabilities: [154×20 double]
TopicWordProbabilities: [3092×20 double]
Vocabulary: ["fairest" "creatures" "desire" "increase" "thereby" "beautys" "rose" "might" "never" "die" "riper" "time" "decease" "tender" "heir" "bear" "memory" "thou" … ]
TopicOrder: 'initial-fit-probability'
FitInfo: [1×1 struct]
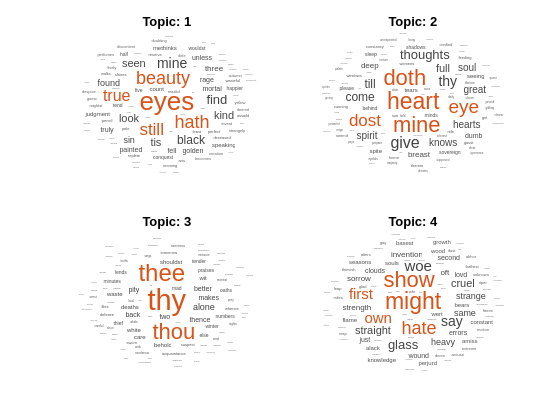
워드 클라우드를 사용하여 처음 4개 토픽을 시각화합니다.
figure for topicIdx = 1:4 subplot(2,2,topicIdx) wordcloud(mdl,topicIdx); title("Topic: " + topicIdx) end
입력 인수
이름-값 인수
선택적 인수 쌍을 Name1=Value1,...,NameN=ValueN으로 지정합니다. 여기서 Name은 인수 이름이고 Value는 대응값입니다. 이름-값 인수는 다른 인수 뒤에 와야 하지만, 인수 쌍의 순서는 상관없습니다.
R2021a 이전 릴리스에서는 각 이름과 값을 쉼표로 구분하고 Name을 따옴표로 묶으십시오.
예: 'HighlightColor','blue'는 강조 표시 색을 파란색으로 지정합니다.
여기에 나와 있는 WordCloudChart 속성은 일부에 불과합니다. 전체 목록은 WordCloudChart Properties 항목을 참조하십시오.
표시할 단어의 최대 개수로, 음이 아닌 정수로 지정됩니다. 가장 큰 MaxDisplayWords개의 단어가 표시됩니다.
단어 색으로, RGB 3색, 색 이름을 포함하는 문자형 벡터 또는 N×3 행렬로 지정됩니다. 여기서 N은 WordData의 길이입니다. Color가 행렬이면 각 행은 WordData의 대응하는 단어의 RGB 3색에 해당합니다.
RGB 3색과 16진수 색 코드는 사용자 지정 색을 지정하는 데 유용합니다.
RGB 3색은 빨간색, 녹색, 파란색 성분의 농도를 지정하는 3개 요소로 구성된 행 벡터입니다. 농도는
[0,1]범위여야 합니다(예:[0.4 0.6 0.7]).16진수 색 코드는 문자형 벡터 또는 string형 스칼라로, 해시 기호(
#)로 시작하고 그 뒤에 3자리 또는 6자리의 16진수 숫자(0~F사이일 수 있음)가 옵니다. 이 값은 대/소문자를 구분하지 않습니다. 따라서 색 코드"#FF8800","#ff8800","#F80","#f80"은 모두 동일합니다.
몇몇 흔한 색은 이름으로 지정할 수도 있습니다. 다음 표에는 명명된 색 옵션과 그에 해당하는 RGB 3색 및 16진수 색 코드가 나와 있습니다.
| 색 이름 | 짧은 이름 | RGB 3색 | 16진수 색 코드 | 모양 |
|---|---|---|---|---|
"red" | "r" | [1 0 0] | "#FF0000" |
|
"green" | "g" | [0 1 0] | "#00FF00" |
|
"blue" | "b" | [0 0 1] | "#0000FF" |
|
"cyan" | "c" | [0 1 1] | "#00FFFF" |
|
"magenta" | "m" | [1 0 1] | "#FF00FF" |
|
"yellow" | "y" | [1 1 0] | "#FFFF00" |
|
"black" | "k" | [0 0 0] | "#000000" |
|
"white" | "w" | [1 1 1] | "#FFFFFF" |
|








다음 표에는 라이트 테마와 다크 테마에서 플롯의 디폴트 색 팔레트가 나와 있습니다.
| 팔레트 | 팔레트 색 |
|---|---|
R2025a 이전: 대부분의 플롯이 기본적으로 이 색상을 사용합니다. |
|
|
|


orderedcolors 함수와 rgb2hex 함수를 사용하여 이 팔레트의 RGB 3색 및 16진수 색 코드를 구할 수 있습니다. 예를 들어, "gem" 팔레트의 RGB 3색을 구한 다음 16진수 색 코드로 변환합니다.
RGB = orderedcolors("gem");
H = rgb2hex(RGB);R2023b 이전: RGB = get(groot,"FactoryAxesColorOrder")를 사용하여 RGB 3색을 구합니다.
R2024a 이전: H = compose("#%02X%02X%02X",round(RGB*255))를 사용하여 16진수 색 코드를 구합니다.
예: 'blue'
예: [0 0 1]
단어 강조 표시 색으로, RGB 3색 또는 색 이름을 포함하는 문자형 벡터로 지정됩니다. 가장 큰 단어가 이 색으로 강조 표시됩니다.
RGB 3색과 16진수 색 코드는 사용자 지정 색을 지정하는 데 유용합니다.
RGB 3색은 빨간색, 녹색, 파란색 성분의 농도를 지정하는 3개 요소로 구성된 행 벡터입니다. 농도는
[0,1]범위여야 합니다(예:[0.4 0.6 0.7]).16진수 색 코드는 문자형 벡터 또는 string형 스칼라로, 해시 기호(
#)로 시작하고 그 뒤에 3자리 또는 6자리의 16진수 숫자(0~F사이일 수 있음)가 옵니다. 이 값은 대/소문자를 구분하지 않습니다. 따라서 색 코드"#FF8800","#ff8800","#F80","#f80"은 모두 동일합니다.
몇몇 흔한 색은 이름으로 지정할 수도 있습니다. 다음 표에는 명명된 색 옵션과 그에 해당하는 RGB 3색 및 16진수 색 코드가 나와 있습니다.
| 색 이름 | 짧은 이름 | RGB 3색 | 16진수 색 코드 | 모양 |
|---|---|---|---|---|
"red" | "r" | [1 0 0] | "#FF0000" |
|
"green" | "g" | [0 1 0] | "#00FF00" |
|
"blue" | "b" | [0 0 1] | "#0000FF" |
|
"cyan" | "c" | [0 1 1] | "#00FFFF" |
|
"magenta" | "m" | [1 0 1] | "#FF00FF" |
|
"yellow" | "y" | [1 1 0] | "#FFFF00" |
|
"black" | "k" | [0 0 0] | "#000000" |
|
"white" | "w" | [1 1 1] | "#FFFFFF" |
|
다음 표에는 라이트 테마와 다크 테마에서 플롯의 디폴트 색 팔레트가 나와 있습니다.
| 팔레트 | 팔레트 색 |
|---|---|
R2025a 이전: 대부분의 플롯이 기본적으로 이 색상을 사용합니다. |
|
|
|
orderedcolors 함수와 rgb2hex 함수를 사용하여 이 팔레트의 RGB 3색 및 16진수 색 코드를 구할 수 있습니다. 예를 들어, "gem" 팔레트의 RGB 3색을 구한 다음 16진수 색 코드로 변환합니다.
RGB = orderedcolors("gem");
H = rgb2hex(RGB);R2023b 이전: RGB = get(groot,"FactoryAxesColorOrder")를 사용하여 RGB 3색을 구합니다.
R2024a 이전: H = compose("#%02X%02X%02X",round(RGB*255))를 사용하여 16진수 색 코드를 구합니다.
예: 'blue'
예: [0 0 1]
워드 클라우드 차트의 형태로, 'oval' 또는 'rectangle'로 지정됩니다.
예: 'rectangle'
출력 인수
세부 정보
버전 내역
R2017b에 개발됨