LDA 모델의 토픽 수 선택하기
이 예제에서는 LDA(잠재 디리클레 할당) 모델에 적합한 토픽 수를 결정하는 방법을 보여줍니다.
적합한 토픽 수를 결정하기 위해 다양한 수의 토픽을 사용한 LDA 모델 피팅의 적합도를 비교할 수 있습니다. 문서의 홀드아웃 세트에 대한 혼잡도(perplexity)를 계산하여 LDA 모델의 적합도를 평가할 수 있습니다. 혼잡도는 모델이 문서 세트를 얼마나 잘 설명하는지 나타냅니다. 혼잡도가 낮을수록 더 적합한 피팅이 제안됩니다.
텍스트 데이터 추출하기 및 전처리하기
예제 데이터를 불러옵니다. factoryReports.csv 파일에는 각 이벤트에 대한 텍스트 설명과 범주 레이블이 포함된 공장 보고서가 들어 있습니다. Description 필드에서 텍스트 데이터를 추출합니다.
filename = "factoryReports.csv"; data = readtable(filename,TextType="string"); textData = data.Description;
이 예제 끝부분에 나와 있는 함수 preprocessText를 사용하여 텍스트 데이터를 토큰화하고 전처리합니다.
documents = preprocessText(textData); documents(1:5)
ans =
5×1 tokenizedDocument:
6 tokens: item occasionally get stuck scanner spool
7 tokens: loud rattling bang sound come assembler piston
4 tokens: cut power start plant
3 tokens: fry capacitor assembler
3 tokens: mixer trip fuse
검증을 위해 무작위로 문서의 10%를 남겨 둡니다.
numDocuments = numel(documents); cvp = cvpartition(numDocuments,HoldOut=0.1); documentsTrain = documents(cvp.training); documentsValidation = documents(cvp.test);
훈련 문서에서 bag-of-words 모델을 만듭니다. 총 2회 이하로 나타나는 단어를 제거합니다. 단어를 포함하지 않는 모든 문서를 제거합니다.
bag = bagOfWords(documentsTrain); bag = removeInfrequentWords(bag,2); bag = removeEmptyDocuments(bag);
토픽 개수 선택하기
목표는 여러 다른 개수의 토픽에 비해 혼잡도를 최소화하는 토픽 개수를 선택하는 것입니다. 이것이 유일한 고려 사항은 아닙니다. 많은 수의 토픽을 사용한 모델 피팅은 수렴하는 데 시간이 오래 걸릴 수 있습니다. 절충 관계를 확인하기 위해 적합도와 피팅 시간을 둘 다 계산합니다. 최적의 토픽 수가 클 경우 피팅 과정의 속도를 높이기 위해 더 작은 값을 선택할 수 있습니다.
토픽 수에 일정 범위의 값을 지정하여 LDA 모델을 피팅합니다. 테스트 문서의 홀드아웃 세트에 대해 각 모델의 피팅 시간 및 혼잡도를 비교합니다. 혼잡도는 logp 함수의 두 번째 출력값입니다. 첫 번째 출력값은 할당하지 않고 두 번째 출력값만 구하려면 ~ 기호를 사용하십시오. 피팅 시간은 마지막 반복에 대한 TimeSinceStart 값입니다. 이 값은 LDA 모델 FitInfo 속성의 History 구조체에 있습니다.
빠른 피팅을 위해 'Solver'를 'savb'로 지정합니다. 세부 정보가 출력되지 않도록 하려면 'Verbose'를 0으로 설정하십시오. 이 작업은 실행하는 데 몇 분 정도 소요될 수 있습니다.
numTopicsRange = [5 10 15 20 40]; for i = 1:numel(numTopicsRange) numTopics = numTopicsRange(i); mdl = fitlda(bag,numTopics, ... Solver="savb", ... Verbose=0); [~,validationPerplexity(i)] = logp(mdl,documentsValidation); timeElapsed(i) = mdl.FitInfo.History.TimeSinceStart(end); end
플롯에 각 토픽 수에 대한 혼잡도와 경과 시간을 표시합니다. 왼쪽 축에는 혼잡도를 플로팅하고 오른쪽 축에는 경과된 시간을 플로팅합니다.
figure yyaxis left plot(numTopicsRange,validationPerplexity,"+-") ylabel("Validation Perplexity") yyaxis right plot(numTopicsRange,timeElapsed,"o-") ylabel("Time Elapsed (s)") legend(["Validation Perplexity" "Time Elapsed (s)"],Location="southeast") xlabel("Number of Topics")
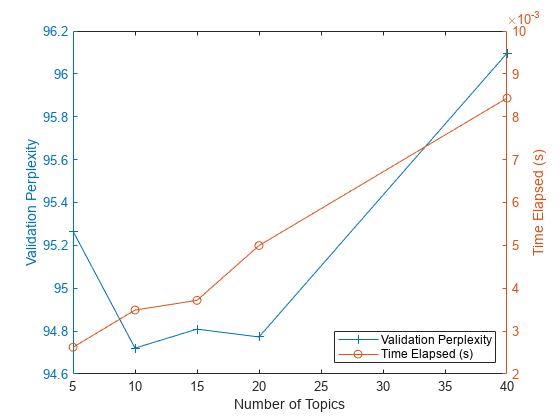
플롯을 보면 10~20개 토픽을 가진 모델을 피팅하는 것이 좋을 것 같습니다. 다른 토픽 개수의 모델에 비해 혼잡도가 낮습니다. 이 솔버에서는 이 정도의 토픽 수에 걸린 경과 시간 역시 적절합니다. 다른 솔버를 사용할 경우 토픽 수를 늘리면 더 적합한 피팅을 얻을 수도 있지만 모델 피팅이 수렴하는 데 더 오랜 시간이 걸릴 수 있습니다.
예제 전처리 함수
함수 preprocessText는 다음 단계를 순서대로 수행합니다.
tokenizedDocument를 사용하여 텍스트를 토큰화합니다.표제어 추출을 개선하기 위해
addPartOfSpeechDetails를 사용하여 품사 세부 정보를 추가합니다.normalizeWords를 사용하여 단어의 표제어를 추출합니다.removeShortWords를 사용하여 2자 이하로 이루어진 단어를 제거합니다.removeLongWords를 사용하여 15자 이상으로 이루어진 단어를 제거합니다.removeStopWords를 사용하여 불용어 목록(예: "and", "of", "the")을 제거합니다.erasePunctuation을 사용하여 문장 부호를 지웁니다.
텍스트 전처리 옵션을 대화형 방식으로 탐색하는 방법을 보여주는 예제는 Preprocess Text Data in Live Editor 항목을 참조하십시오.
function documents = preprocessText(textData) % Tokenize. documents = tokenizedDocument(textData); % Lemmatize. documents = addPartOfSpeechDetails(documents); documents = normalizeWords(documents,Style="lemma"); % Remove short and long words. documents = removeShortWords(documents,2); documents = removeLongWords(documents,15); % Remove stop words. documents = removeStopWords(documents,IgnoreCase=false); % Erase punctuation. documents = erasePunctuation(documents); end
참고 항목
tokenizedDocument | bagOfWords | removeStopWords | logp | bagOfWords | fitlda | ldaModel | erasePunctuation | removeShortWords | removeLongWords | normalizeWords | addPartOfSpeechDetails | removeInfrequentWords | removeEmptyDocuments