kfoldPredict
Predict labels for observations not used for training
Syntax
Description
Label = kfoldPredict(CVMdl)CVMdl. That is,
for every fold, kfoldPredict predicts class labels
for observations that it holds out when it trains using all other
observations. kfoldPredict applies the same data
used create CVMdl (see fitcecoc).
Also, Label contains class labels for each
regularization strength in the linear classification models that compose CVMdl.
Label = kfoldPredict(CVMdl,Name,Value)Name,Value pair arguments. For example,
specify the posterior probability estimation method, decoding scheme,
or verbosity level.
Input Arguments
Name-Value Arguments
Output Arguments
Examples
Load the NLP data set.
load nlpdataX is a sparse matrix of predictor data, and Y is a categorical vector of class labels.
Cross-validate an ECOC model of linear classification models.
rng(1); % For reproducibility CVMdl = fitcecoc(X,Y,'Learner','linear','CrossVal','on');
CVMdl is a ClassificationPartitionedLinearECOC model. By default, the software implements 10-fold cross validation.
Predict labels for the observations that fitcecoc did not use in training the folds.
label = kfoldPredict(CVMdl);
Because there is one regularization strength in CVMdl, label is a column vector of predictions containing as many rows as observations in X.
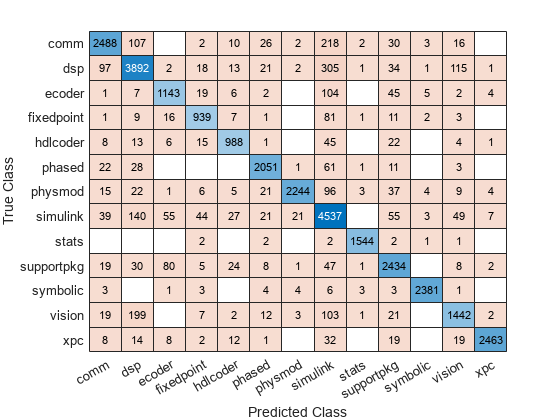
Construct a confusion matrix.
cm = confusionchart(Y,label);
Load the NLP data set. Transpose the predictor data.
load nlpdata
X = X';For simplicity, use the label 'others' for all observations in Y that are not 'simulink', 'dsp', or 'comm'.
Y(~(ismember(Y,{'simulink','dsp','comm'}))) = 'others';Create a linear classification model template that specifies optimizing the objective function using SpaRSA.
t = templateLinear('Solver','sparsa');
Cross-validate an ECOC model of linear classification models using 5-fold cross-validation. Specify that the predictor observations correspond to columns.
rng(1); % For reproducibility CVMdl = fitcecoc(X,Y,'Learners',t,'KFold',5,'ObservationsIn','columns'); CMdl1 = CVMdl.Trained{1}
CMdl1 =
CompactClassificationECOC
ResponseName: 'Y'
ClassNames: [comm dsp simulink others]
ScoreTransform: 'none'
BinaryLearners: {6×1 cell}
CodingMatrix: [4×6 double]
Properties, Methods
CVMdl is a ClassificationPartitionedLinearECOC model. It contains the property Trained, which is a 5-by-1 cell array holding a CompactClassificationECOC models that the software trained using the training set of each fold.
By default, the linear classification models that compose the ECOC models use SVMs. SVM scores are signed distances from the observation to the decision boundary. Therefore, the domain is . Create a custom binary loss function that:
Maps the coding design matrix (M) and positive-class classification scores (s) for each learner to the binary loss for each observation
Uses linear loss
Aggregates the binary learner loss using the median.
You can create a separate function for the binary loss function, and then save it on the MATLAB® path. Or, you can specify an anonymous binary loss function.
customBL = @(M,s)median(1 - (M.*s),2,'omitnan')/2;Predict cross-validation labels and estimate the median binary loss per class. Print the median negative binary losses per class for a random set of 10 out-of-fold observations.
[label,NegLoss] = kfoldPredict(CVMdl,'BinaryLoss',customBL); idx = randsample(numel(label),10); table(Y(idx),label(idx),NegLoss(idx,1),NegLoss(idx,2),NegLoss(idx,3),... NegLoss(idx,4),'VariableNames',[{'True'};{'Predicted'};... categories(CVMdl.ClassNames)])
ans=10×6 table
True Predicted comm dsp simulink others
________ _________ _________ ________ ________ _______
others others -1.2319 -1.0488 0.048758 1.6175
simulink simulink -16.407 -12.218 21.531 11.218
dsp dsp -0.7387 -0.11534 -0.88466 -0.2613
others others -0.1251 -0.8749 -0.99766 0.14517
dsp dsp 2.5867 6.4187 -3.5867 -4.4165
others others -0.025358 -1.2287 -0.97464 0.19747
others others -2.6725 -0.56708 -0.51092 2.7453
others others -1.1605 -0.88321 -0.11679 0.43504
others others -1.9511 -1.3175 0.24735 0.95111
simulink others -7.848 -5.8203 4.8203 6.8457
The software predicts the label based on the maximum negated loss.
ECOC models composed of linear classification models return posterior probabilities for logistic regression learners only. This example requires the Parallel Computing Toolbox™ and the Optimization Toolbox™
Load the NLP data set and preprocess the data as in Specify Custom Binary Loss.
load nlpdata X = X'; Y(~(ismember(Y,{'simulink','dsp','comm'}))) = 'others';
Create a set of 5 logarithmically-spaced regularization strengths from 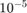 through
through 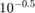 .
.
Lambda = logspace(-6,-0.5,5);
Create a linear classification model template that specifies optimizing the objective function using SpaRSA and to use logistic regression learners.
t = templateLinear('Solver','sparsa','Learner','logistic','Lambda',Lambda);
Cross-validate an ECOC model of linear classification models using 5-fold cross-validation. Specify that the predictor observations correspond to columns, and to use parallel computing.
rng(1); % For reproducibility Options = statset('UseParallel',true); CVMdl = fitcecoc(X,Y,'Learners',t,'KFold',5,'ObservationsIn','columns',... 'Options',Options);
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 6).
Predict the cross-validated posterior class probabilities. Specify to use parallel computing and to estimate posterior probabilities using quadratic programming.
[label,~,~,Posterior] = kfoldPredict(CVMdl,'Options',Options,... 'PosteriorMethod','qp'); size(label) label(3,4) size(Posterior) Posterior(3,:,4)
ans =
31572 5
ans =
categorical
others
ans =
31572 4 5
ans =
0.0285 0.0373 0.1714 0.7627
Because there are five regularization strengths:
labelis a 31572-by-5 categorical array.label(3,4)is the predicted, cross-validated label for observation 3 using the model trained with regularization strengthLambda(4).Posterioris a 31572-by-4-by-5 matrix.Posterior(3,:,4)is the vector of all estimated, posterior class probabilities for observation 3 using the model trained with regularization strengthLambda(4). The order of the second dimension corresponds toCVMdl.ClassNames. Display a random set of 10 posterior class probabilities.
Display a random sample of cross-validated labels and posterior probabilities for the model trained using Lambda(4).
idx = randsample(size(label,1),10); table(Y(idx),label(idx,4),Posterior(idx,1,4),Posterior(idx,2,4),... Posterior(idx,3,4),Posterior(idx,4,4),... 'VariableNames',[{'True'};{'Predicted'};categories(CVMdl.ClassNames)])
ans =
10×6 table
True Predicted comm dsp simulink others
________ _________ __________ __________ ________ _________
others others 0.030275 0.022142 0.10416 0.84342
simulink simulink 3.4954e-05 4.2982e-05 0.99832 0.0016016
dsp others 0.15787 0.25718 0.18848 0.39647
others others 0.094177 0.062712 0.12921 0.71391
dsp dsp 0.0057979 0.89703 0.015098 0.082072
others others 0.086084 0.054836 0.086165 0.77292
others others 0.0062338 0.0060492 0.023816 0.9639
others others 0.06543 0.075097 0.17136 0.68812
others others 0.051843 0.025566 0.13299 0.7896
simulink simulink 0.00044059 0.00049753 0.70958 0.28948