ClassificationNeuralNetwork
Neural network model for classification
Description
A ClassificationNeuralNetwork object is a trained neural
network for classification, such as a feedforward, fully connected network. In a
feedforward, fully connected network, the first fully connected layer of has a
connection from the network input (predictor data X), and
each subsequent layer has a connection from the previous layer. Each fully connected
layer multiplies the input by a weight matrix (LayerWeights) and then adds a bias vector (LayerBiases). An activation function follows each fully connected layer
(Activations
and OutputLayerActivation). The final fully connected layer and the
subsequent softmax activation function produce the network's output, namely
classification scores (posterior probabilities) and predicted labels. For more
information, see Neural Network Structure.
Creation
Create a ClassificationNeuralNetwork object by using fitcnet.
Properties
Object Functions
Examples
Train a neural network classifier, and assess the performance of the classifier on a test set.
Read the sample file CreditRating_Historical.dat into a table. The predictor data consists of financial ratios and industry sector information for a list of corporate customers. The response variable consists of credit ratings assigned by a rating agency. Preview the first few rows of the data set.
creditrating = readtable("CreditRating_Historical.dat");
head(creditrating) ID WC_TA RE_TA EBIT_TA MVE_BVTD S_TA Industry Rating
_____ ______ ______ _______ ________ _____ ________ _______
62394 0.013 0.104 0.036 0.447 0.142 3 {'BB' }
48608 0.232 0.335 0.062 1.969 0.281 8 {'A' }
42444 0.311 0.367 0.074 1.935 0.366 1 {'A' }
48631 0.194 0.263 0.062 1.017 0.228 4 {'BBB'}
43768 0.121 0.413 0.057 3.647 0.466 12 {'AAA'}
39255 -0.117 -0.799 0.01 0.179 0.082 4 {'CCC'}
62236 0.087 0.158 0.049 0.816 0.324 2 {'BBB'}
39354 0.005 0.181 0.034 2.597 0.388 7 {'AA' }
Because each value in the ID variable is a unique customer ID, that is, length(unique(creditrating.ID)) is equal to the number of observations in creditrating, the ID variable is a poor predictor. Remove the ID variable from the table, and convert the Industry variable to a categorical variable.
creditrating = removevars(creditrating,"ID");
creditrating.Industry = categorical(creditrating.Industry);Convert the Rating response variable to a categorical variable.
creditrating.Rating = categorical(creditrating.Rating, ... ["AAA","AA","A","BBB","BB","B","CCC"]);
Partition the data into training and test sets. Use approximately 80% of the observations to train a neural network model, and 20% of the observations to test the performance of the trained model on new data. Use cvpartition to partition the data.
rng("default") % For reproducibility of the partition c = cvpartition(creditrating.Rating,"Holdout",0.20); trainingIndices = training(c); % Indices for the training set testIndices = test(c); % Indices for the test set creditTrain = creditrating(trainingIndices,:); creditTest = creditrating(testIndices,:);
Train a neural network classifier by passing the training data creditTrain to the fitcnet function.
Mdl = fitcnet(creditTrain,"Rating")Mdl =
ClassificationNeuralNetwork
PredictorNames: {'WC_TA' 'RE_TA' 'EBIT_TA' 'MVE_BVTD' 'S_TA' 'Industry'}
ResponseName: 'Rating'
CategoricalPredictors: 6
ClassNames: [AAA AA A BBB BB B CCC]
ScoreTransform: 'none'
NumObservations: 3146
LayerSizes: 10
Activations: 'relu'
OutputLayerActivation: 'softmax'
Solver: 'LBFGS'
ConvergenceInfo: [1×1 struct]
TrainingHistory: [1000×7 table]
Properties, Methods
Mdl is a trained ClassificationNeuralNetwork classifier. You can use dot notation to access the properties of Mdl. For example, you can specify Mdl.TrainingHistory to get more information about the training history of the neural network model.
Evaluate the performance of the classifier on the test set by computing the test set classification error. Visualize the results by using a confusion matrix.
testAccuracy = 1 - loss(Mdl,creditTest,"Rating", ... "LossFun","classiferror")
testAccuracy = 0.7977
confusionchart(creditTest.Rating,predict(Mdl,creditTest))

Specify a custom neural network architecture using Deep Learning Toolbox™.
Load the ionosphere data set, which includes radar signal data. X contains the predictor data, and Y is the response variable, whose values represent either good ("g") or bad ("b") radar signals.
load ionosphereSeparate the data into training data (XTrain and YTrain) and test data (XTest and YTest) by using a stratified holdout partition. Reserve approximately 30% of the observations for testing, and use the rest of the observations for training.
rng("default") % For reproducibility of the partition cvp = cvpartition(Y,Holdout=0.3); XTrain = X(training(cvp),:); YTrain = Y(training(cvp)); XTest = X(test(cvp),:); YTest = Y(test(cvp));
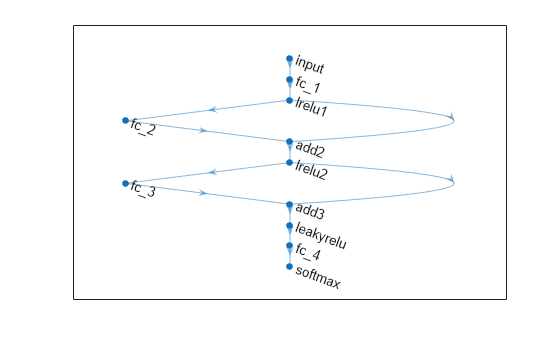
Define a neural network architecture with these characteristics:
A feature input layer with an input size that matches the number of predictors.
Three fully connected layers followed by leaky ReLU layers, connected in series, where the fully connected layers have output sizes of 16, and addition layers after the second and third fully connected layers.
Skip connections around the second and third fully connected layers using the addition layers.
A final fully connected layer with an output size that matches the number of classes followed by a softmax layer.
inputSize = size(XTrain,2);
outputSize = numel(unique(YTrain));
net = dlnetwork;
layers = [
featureInputLayer(inputSize)
fullyConnectedLayer(30)
leakyReluLayer(Name="lrelu1")
fullyConnectedLayer(30)
additionLayer(2,Name="add2")
leakyReluLayer(Name="lrelu2")
fullyConnectedLayer(30)
additionLayer(2,Name="add3")
leakyReluLayer
fullyConnectedLayer(outputSize)
softmaxLayer];
net = addLayers(net,layers);
net = connectLayers(net,"lrelu1","add2/in2");
net = connectLayers(net,"lrelu2","add3/in2");Visualize the neural network architecture in a plot.
figure plot(net)
Train a neural network classifier.
Mdl = fitcnet(XTrain,YTrain,Network=net,Standardize=true)
Mdl =
ClassificationNeuralNetwork
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'b' 'g'}
ScoreTransform: 'none'
NumObservations: 246
LayerSizes: []
Activations: ''
OutputLayerActivation: ''
Solver: 'LBFGS'
ConvergenceInfo: [1×1 struct]
TrainingHistory: [30×7 table]
View network information using dlnetwork.
Properties, Methods
To estimate the performance of the trained classifier, compute the test set classification error.
testError = loss(Mdl,XTest,YTest, ... LossFun="classiferror")
testError = 0.0774
Extended Capabilities
Version History
Introduced in R2021aSee Also
fitcnet | predict | loss | margin | edge | ClassificationPartitionedNeuralNetwork | CompactClassificationNeuralNetwork | dlnetwork (Deep Learning Toolbox)