compareHoldout
Compare accuracies of two classification models using new data
Syntax
Description
compareHoldout statistically assesses the accuracies of
two classification models. The function first compares their predicted labels against
the true labels, and then it detects whether the difference between the
misclassification rates is statistically significant.
You can determine whether the accuracies of the classification models differ or
whether one model performs better than another. compareHoldout can
conduct several McNemar test variations,
including the asymptotic test, the exact-conditional test, and the
mid-p-value test. For cost-sensitive assessment, available tests include a chi-square test
(requires Optimization Toolbox™) and a likelihood ratio test.
h = compareHoldout(C1,C2,T1,T2,ResponseVarName)C1 and C2 have
equal accuracy for predicting the true class labels in the
ResponseVarName variable. The alternative hypothesis is
that the labels have unequal accuracy.
The first classification model C1 uses the predictor data
in T1, and the second classification model
C2 uses the predictor data in T2.
The tables T1 and T2 must contain the
same response variable but can contain different sets of predictors. By default,
the software conducts the mid-p-value McNemar test to compare
the accuracies.
h = 1 indicates rejecting the null
hypothesis at the 5% significance level. h =
0 indicates not rejecting the null hypothesis at the 5%
level.
The following are examples of tests you can conduct:
Compare the accuracies of a simple classification model and a model that is more complex by passing the same set of predictor data (that is,
T1=T2).Compare the accuracies of two potentially different models using two potentially different sets of predictors.
Perform various types of Feature Selection. For example, you can compare the accuracy of a model trained using a set of predictors to the accuracy of one trained on a subset or different set of those predictors. You can choose the set of predictors arbitrarily, or use a feature selection technique such as PCA or sequential feature selection (see
pcaandsequentialfs).
h = compareHoldout(C1,C2,T1,T2,Y)C1 and C2 have
equal accuracy for predicting the true class labels Y. The
alternative hypothesis is that the labels have unequal accuracy.
The first classification model C1 uses the predictor data
T1, and the second classification model
C2 uses the predictor data T2. By
default, the software conducts the mid-p-value McNemar test
to compare the accuracies.
h = compareHoldout(C1,C2,X1,X2,Y)C1 and C2 have
equal accuracy for predicting the true class labels Y. The
alternative hypothesis is that the labels have unequal accuracy.
The first classification model C1 uses the predictor data
X1, and the second classification model
C2 uses the predictor data X2. By
default, the software conducts the mid-p-value McNemar test
to compare the accuracies.
h = compareHoldout(___,Name,Value)
Examples
Train two k-nearest neighbor classifiers, one using a subset of the predictors used for the other. Conduct a statistical test comparing the accuracies of the two models on a test set.
Load the carsmall data set.
load carsmallCreate two tables of input data, where the second table excludes the predictor Acceleration. Specify Model_Year as the response variable.
T1 = table(Acceleration,Displacement,Horsepower,MPG,Model_Year); T2 = T1(:,2:end);
Create a partition that splits the data into training and test sets. Keep 30% of the data for testing.
rng(1) % For reproducibility CVP = cvpartition(Model_Year,'holdout',0.3); idxTrain = training(CVP); % Training-set indices idxTest = test(CVP); % Test-set indices
CVP is a cross-validation partition object that specifies the training and test sets.
Train the ClassificationKNN models using the T1 and T2 data.
C1 = fitcknn(T1(idxTrain,:),'Model_Year'); C2 = fitcknn(T2(idxTrain,:),'Model_Year');
C1 and C2 are trained ClassificationKNN models.
Test whether the two models have equal predictive accuracies on the test set.
h = compareHoldout(C1,C2,T1(idxTest,:),T2(idxTest,:),'Model_Year')h = logical
0
h = 0 indicates to not reject the null hypothesis that the two models have equal predictive accuracies.
Train two classification models using different algorithms. Conduct a statistical test comparing the misclassification rates of the two models on a test set.
Load the ionosphere data set.
load ionosphereCreate a partition that evenly splits the data into training and test sets.
rng(1) % For reproducibility CVP = cvpartition(Y,'holdout',0.5); idxTrain = training(CVP); % Training-set indices idxTest = test(CVP); % Test-set indices
CVP is a cross-validation partition object that specifies the training and test sets.
Train an SVM model and an ensemble of 100 bagged classification trees. For the SVM model, specify to use the radial basis function kernel and a heuristic procedure to determine the kernel scale.
C1 = fitcsvm(X(idxTrain,:),Y(idxTrain),'Standardize',true, ... 'KernelFunction','RBF','KernelScale','auto'); t = templateTree('Reproducible',true); % For reproducibility of random predictor selections C2 = fitcensemble(X(idxTrain,:),Y(idxTrain),'Method','Bag', ... 'Learners',t);
C1 is a trained ClassificationSVM model. C2 is a trained ClassificationBaggedEnsemble model.
Test whether the two models have equal predictive accuracies. Use the same test-set predictor data for each model.
h = compareHoldout(C1,C2,X(idxTest,:),X(idxTest,:),Y(idxTest))
h = logical
0
h = 0 indicates to not reject the null hypothesis that the two models have equal predictive accuracies.
Train two classification models using the same algorithm, but adjust a hyperparameter to make the algorithm more complex. Conduct a statistical test to assess whether the simpler model has better accuracy on test data than the more complex model.
Load the ionosphere data set.
load ionosphere;Create a partition that evenly splits the data into training and test sets.
rng(1); % For reproducibility CVP = cvpartition(Y,'holdout',0.5); idxTrain = training(CVP); % Training-set indices idxTest = test(CVP); % Test-set indices
CVP is a cross-validation partition object that specifies the training and test sets.
Train two SVM models: one that uses a linear kernel (the default for binary classification) and one that uses the radial basis function kernel. Use the default kernel scale of 1.
C1 = fitcsvm(X(idxTrain,:),Y(idxTrain),'Standardize',true); C2 = fitcsvm(X(idxTrain,:),Y(idxTrain),'Standardize',true,... 'KernelFunction','RBF');
C1 and C2 are trained ClassificationSVM models.
Test the null hypothesis that the simpler model (C1) is at most as accurate as the more complex model (C2). Because the test-set size is large, conduct the asymptotic McNemar test, and compare the results with the mid-p-value test (the cost-insensitive testing default). Request to return p-values and misclassification rates.
Asymp = zeros(4,1); % Preallocation MidP = zeros(4,1); [Asymp(1),Asymp(2),Asymp(3),Asymp(4)] = compareHoldout(C1,C2,... X(idxTest,:),X(idxTest,:),Y(idxTest),'Alternative','greater',... 'Test','asymptotic'); [MidP(1),MidP(2),MidP(3),MidP(4)] = compareHoldout(C1,C2,... X(idxTest,:),X(idxTest,:),Y(idxTest),'Alternative','greater'); table(Asymp,MidP,'RowNames',{'h' 'p' 'e1' 'e2'})
ans=4×2 table
Asymp MidP
__________ __________
h 1 1
p 7.2801e-09 2.7649e-10
e1 0.13714 0.13714
e2 0.33143 0.33143
The p-value is close to zero for both tests, providing strong evidence to reject the null hypothesis that the simpler model is less accurate than the more complex model. No matter what test you specify, compareHoldout returns the same type of misclassification measure for both models.
For data sets with imbalanced class representations, or for data sets with imbalanced false-positive and false-negative costs, you can statistically compare the predictive performance of two classification models by including a cost matrix in the analysis.
Load the arrhythmia data set. Determine the class representations in the data.
load arrhythmia;
Y = categorical(Y);
tabulate(Y); Value Count Percent
1 245 54.20%
2 44 9.73%
3 15 3.32%
4 15 3.32%
5 13 2.88%
6 25 5.53%
7 3 0.66%
8 2 0.44%
9 9 1.99%
10 50 11.06%
14 4 0.88%
15 5 1.11%
16 22 4.87%
There are 16 classes, however some are not represented in the data set (for example, class 13). Most observations are classified as not having arrhythmia (class 1). The data set is highly discrete with imbalanced classes.
Combine all observations with arrhythmia (classes 2 through 15) into one class. Remove those observations with unknown arrhythmia status (class 16) from the data set.
idx = (Y ~= '16'); Y = Y(idx); X = X(idx,:); Y(Y ~= '1') = 'WithArrhythmia'; Y(Y == '1') = 'NoArrhythmia'; Y = removecats(Y);
Create a partition that evenly splits the data into training and test sets.
rng(1); % For reproducibility CVP = cvpartition(Y,'holdout',0.5); idxTrain = training(CVP); % Training-set indices idxTest = test(CVP); % Test-set indices
CVP is a cross-validation partition object that specifies the training and test sets.
Create a cost matrix such that misclassifying a patient with arrhythmia into the "no arrhythmia" class is five times worse than misclassifying a patient without arrhythmia into the arrhythmia class. Classifying correctly incurs no cost. The rows indicate the true class and the columns indicate the predicted class. When you conduct a cost-sensitive analysis, a good practice is to specify the order of the classes.
cost = [0 1;5 0];
ClassNames = {'NoArrhythmia','WithArrhythmia'};Train two boosting ensembles of 50 classification trees, one that uses AdaBoostM1 and another that uses LogitBoost. Because the data set contains missing values, specify to use surrogate splits. Train the models using the cost matrix.
t = templateTree('Surrogate','on'); numTrees = 50; C1 = fitcensemble(X(idxTrain,:),Y(idxTrain),'Method','AdaBoostM1', ... 'NumLearningCycles',numTrees,'Learners',t, ... 'Cost',cost,'ClassNames',ClassNames); C2 = fitcensemble(X(idxTrain,:),Y(idxTrain),'Method','LogitBoost', ... 'NumLearningCycles',numTrees,'Learners',t, ... 'Cost',cost,'ClassNames',ClassNames);
C1 and C2 are trained ClassificationEnsemble models.
Compute the classification loss for the test data by using the loss function. Specify LossFun as 'classifcost' to compute the misclassification cost.
L1 = loss(C1,X(idxTest,:),Y(idxTest),'LossFun','classifcost')
L1 = 0.6642
L2 = loss(C2,X(idxTest,:),Y(idxTest),'LossFun','classifcost')
L2 = 0.8018
The misclassification cost for the AdaBoostM1 ensemble (C1) is less than the cost for the LogitBoost ensemble (C2).
Test whether the difference is statistically significant. Conduct the asymptotic, likelihood ratio, cost-sensitive test (the default when you pass in a cost matrix). Supply the cost matrix, and return the p-values and misclassification costs.
[h,p,e1,e2] = compareHoldout(C1,C2,X(idxTest,:),X(idxTest,:),Y(idxTest),... 'Cost',cost,'ClassNames',ClassNames)
h = logical
0
p = 0.1180
e1 = 0.6698
e2 = 0.8093
h = 0 indicates to not reject the null hypothesis that the two models have equal predictive accuracies.
The loss function uses observation weights normalized by the prior probabilities (stored in the Prior property of the trained model), but the compareHoldout function does not use observation weights and prior probabilities. Therefore, the misclassification cost values (L1 and L2) computed by the loss function can be different from the values (e1 and e2) computed by the compareHoldout function.
Reduce classification model complexity by selecting a subset of predictor variables (features) from a larger set. Then, statistically compare the out-of-sample accuracy between the two models.
Load the ionosphere data set.
load ionosphere;Create a partition that evenly splits the data into training and test sets.
rng(1); % For reproducibility CVP = cvpartition(Y,'holdout',0.5); idxTrain = training(CVP); % Training-set indices idxTest = test(CVP); % Test-set indices
CVP is a cross-validation partition object that specifies the training and test sets.
Train an ensemble of 100 boosted classification trees using AdaBoostM1 and the entire set of predictors. Inspect the importance measure for each predictor.
t = templateTree('MaxNumSplits',1); % Weak-learner template tree object C2 = fitcensemble(X(idxTrain,:),Y(idxTrain),'Method','AdaBoostM1',... 'Learners',t); predImp = predictorImportance(C2); figure; bar(predImp); h = gca; h.XTick = 1:2:h.XLim(2)
h =
Axes with properties:
XLim: [-0.2000 35.2000]
YLim: [0 0.0090]
XScale: 'linear'
YScale: 'linear'
GridLineStyle: '-'
Position: [0.1300 0.1100 0.7750 0.8150]
Units: 'normalized'
Show all properties
title('Predictor Importance'); xlabel('Predictor'); ylabel('Importance measure');
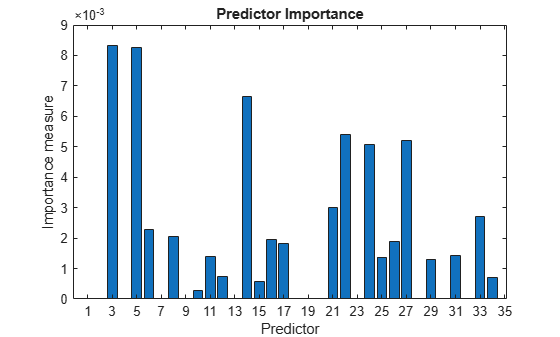
Identify the top five predictors in terms of their importance.
[~,idxSort] = sort(predImp,'descend');
idx5 = idxSort(1:5);Train another ensemble of 100 boosted classification trees using AdaBoostM1 and the five predictors with the greatest importance.
C1 = fitcensemble(X(idxTrain,idx5),Y(idxTrain),'Method','AdaBoostM1',... 'Learners',t);
Test whether the two models have equal predictive accuracies. Specify the reduced test-set predictor data for C1 and the full test-set predictor data for C2.
[h,p,e1,e2] = compareHoldout(C1,C2,X(idxTest,idx5),X(idxTest,:),Y(idxTest))
h = logical
0
p = 0.7744
e1 = 0.0914
e2 = 0.0857
h = 0 indicates to not reject the null hypothesis that the two models have equal predictive accuracies. This result favors the simpler ensemble, C1.
Input Arguments
Name-Value Arguments
Output Arguments
Limitations
compareHoldoutdoes not compare ECOC models composed of linear or kernel classification models (that is,ClassificationLinearorClassificationKernelmodel objects). To compareClassificationECOCmodels composed of linear or kernel classification models, usetestcholdoutinstead.Similarly,
compareHoldoutdoes not compareClassificationLinearorClassificationKernelmodel objects. To compare these models, usetestcholdoutinstead.
More About
McNemar Tests are hypothesis tests that compare two population proportions while addressing the issues resulting from two dependent, matched-pair samples.
One way to compare the predictive accuracies of two classification models is:
Partition the data into training and test sets.
Train both classification models using the training set.
Predict class labels using the test set.
Summarize the results in a two-by-two table similar to this figure.

nii are the number of concordant pairs, that is, the number of observations that both models classify the same way (correctly or incorrectly). nij, i ≠ j, are the number of discordant pairs, that is, the number of observations that models classify differently (correctly or incorrectly).
The misclassification rates for Models 1 and 2 are and , respectively. A two-sided test for comparing the accuracy of the two models is
The null hypothesis suggests that the population exhibits marginal homogeneity, which reduces the null hypothesis to Also, under the null hypothesis, N12 ~ Binomial(n12 + n21,0.5) [1].
These facts are the basis for the available McNemar test variants: the asymptotic, exact-conditional, and mid-p-value McNemar tests. The definitions that follow summarize the available variants.
Asymptotic — The asymptotic McNemar test statistics and rejection regions (for significance level α) are:
For one-sided tests, the test statistic is
If where Φ is the standard Gaussian cdf, then reject H0.
For two-sided tests, the test statistic is
If , where is the χm2 cdf evaluated at x, then reject H0.
The asymptotic test requires large-sample theory, specifically, the Gaussian approximation to the binomial distribution.
The total number of discordant pairs, , must be greater than 10 ([1], Ch. 10.1.4).
In general, asymptotic tests do not guarantee nominal coverage. The observed probability of falsely rejecting the null hypothesis can exceed α, as suggested in simulation studies in [2]. However, the asymptotic McNemar test performs well in terms of statistical power.
Exact-Conditional — The exact-conditional McNemar test statistics and rejection regions (for significance level α) are ([4], [5]):
For one-sided tests, the test statistic is
If , where is the binomial cdf with sample size n and success probability p evaluated at x, then reject H0.
For two-sided tests, the test statistic is
If , then reject H0.
The exact-conditional test always attains nominal coverage. Simulation studies in [2] suggest that the test is conservative, and then show that the test lacks statistical power compared to other variants. For small or highly discrete test samples, consider using the mid-p-value test ([1], Ch. 3.6.3).
Mid-p-value test — The mid-p-value McNemar test statistics and rejection regions (for significance level α) are ([3]):
For one-sided tests, the test statistic is
If , where and are the binomial cdf and pdf, respectively, with sample size n and success probability p evaluated at x, then reject H0.
For two-sided tests, the test statistic is
If , then reject H0.
The mid-p-value test addresses the over-conservative behavior of the exact-conditional test. The simulation studies in [2] demonstrate that this test attains nominal coverage, and has good statistical power.
Tips
One way to perform cost-insensitive feature selection is:
Train the first classification model (
C1) using the full predictor set.Train the second classification model (
C2) using the reduced predictor set.Specify
X1as the full test-set predictor data andX2as the reduced test-set predictor data.Enter
compareHoldout(C1,C2,X1,X2,Y,'Alternative','less'). IfcompareHoldoutreturns1, then there is enough evidence to suggest that the classification model that uses fewer predictors performs better than the model that uses the full predictor set.
Alternatively, you can assess whether there is a significant difference between the accuracies of the two models. To perform this assessment, remove the
'Alternative','less'specification in step 4.compareHoldoutconducts a two-sided test, andh = 0indicates that there is not enough evidence to suggest a difference in the accuracy of the two models.Cost-sensitive tests perform numerical optimization, which requires additional computational resources. The likelihood ratio test conducts numerical optimization indirectly by finding the root of a Lagrange multiplier in an interval. For some data sets, if the root lies close to the boundaries of the interval, then the method can fail. Therefore, if you have an Optimization Toolbox license, consider conducting the cost-sensitive chi-square test instead. For more details, see
CostTestand Cost-Sensitive Testing.
Alternative Functionality
To directly compare the accuracy of two sets of class labels
in predicting a set of true class labels, use testcholdout.