anova1
일원분산분석
구문
설명
p = anova1(y,group,displayopt)displayopt가 'on'(디폴트 값)인 경우 분산분석표와 상자 플롯을 표시하고 displayopt가 'off'인 경우 표시하지 않습니다.
예제
상수 열을 가진 표본 데이터 행렬 y를 생성하고 평균이 0이고 표준편차가 1인 임의 정규분포의 교란을 추가합니다.
y = meshgrid(1:5); rng default; % For reproducibility y = y + normrnd(0,1,5,5)
y = 5×5
1.5377 0.6923 1.6501 3.7950 5.6715
2.8339 1.5664 6.0349 3.8759 3.7925
-1.2588 2.3426 3.7254 5.4897 5.7172
1.8622 5.5784 2.9369 5.4090 6.6302
1.3188 4.7694 3.7147 5.4172 5.4889
일원분산분석을 수행합니다.
p = anova1(y)


p = 0.0023
분산분석표는 그룹 간 변동(Columns)과 그룹 내 변동(Error)을 보여줍니다. SS는 제곱합이고, df는 자유도입니다. 총 자유도는 총 관측값 개수에서 1을 뺀 값, 즉 25 - 1 = 24입니다. 그룹 간 자유도는 그룹 개수에서 1을 뺀 값, 즉 5 - 1 = 4입니다. 그룹 내 자유도는 총 자유도에서 그룹 간 자유도를 뺀 값, 즉 24 - 4 = 20입니다.
MS는 평균제곱오차, 즉 각 변동 요인에 대한 SS/df입니다. F-통계량은 두 평균제곱오차 간의 비율(13.4309/2.2204)입니다. p-값은 F-검정 통계량이 계산된 검정 통계량의 값보다 큰 값을 취할 수 있는 확률입니다. 즉, P(F > 6.05)입니다. p-값이 0.0023으로 작아 열 평균값 간의 차이가 유의미하다는 것을 나타냅니다.
표본 데이터를 입력합니다.
strength = [82 86 79 83 84 85 86 87 74 82 ... 78 75 76 77 79 79 77 78 82 79]; alloy = {'st','st','st','st','st','st','st','st',... 'al1','al1','al1','al1','al1','al1',... 'al2','al2','al2','al2','al2','al2'};
이 데이터는 호그(Hogg)의 구조적 빔 강도에 대한 연구(1987년)에서 얻은 것입니다. 벡터 strength는 3000파운드 힘이 가해진 상황에서 천 분의 일 인치 단위로 빔의 굴절을 측정합니다. 벡터 alloy는 각 빔을 강철('st'), 합금 1('al1') 또는 합금 2('al2')로 식별합니다. 이 예제에서는 합금이 순서대로 정렬되어 있지만 그룹화 변수를 항상 정렬할 필요는 없습니다.
강철 빔이 비용이 더 비싼 합금으로 제조된 두 빔과 강도가 같다'는 귀무가설을 검정합니다. 그림 표시를 해제하고 셀형 배열로 분산분석 결과를 반환합니다.
[p,tbl] = anova1(strength,alloy,'off')p = 1.5264e-04
tbl=4×6 cell array
{'Source'} {'SS' } {'df'} {'MS' } {'F' } {'Prob>F' }
{'Groups'} {[184.8000]} {[ 2]} {[ 92.4000]} {[ 15.4000]} {[1.5264e-04]}
{'Error' } {[102.0000]} {[17]} {[ 6.0000]} {0×0 double} {0×0 double }
{'Total' } {[286.8000]} {[19]} {0×0 double} {0×0 double} {0×0 double }
총 자유도는 총 관측값 개수에서 1을 뺀 값, 즉 입니다. 그룹 간 자유도는 그룹 개수에서 1을 뺀 값, 즉 입니다. 그룹 내 자유도는 총 자유도에서 그룹 간 자유도를 뺀 값, 즉 입니다.
MS는 평균제곱오차, 즉 각 변동 요인에 대한 SS/df입니다. F-통계량은 두 평균제곱오차 간의 비율입니다. p-값은 F-검정 통계량이 검정 통계량의 값보다 크거나 같은 값을 취할 수 있는 확률입니다. p-값이 1.5264e-04이므로 귀무가설을 기각할 수 있습니다.
셀형 배열의 요소를 참조하여 분산분석표의 값을 가져올 수 있습니다. F-통계량 값과 p-값을 새 변수 Fstat와 pvalue에 저장합니다.
Fstat = tbl{2,5}Fstat = 15.4000
pvalue = tbl{2,6}pvalue = 1.5264e-04
표본 데이터를 입력합니다.
strength = [82 86 79 83 84 85 86 87 74 82 ... 78 75 76 77 79 79 77 78 82 79]; alloy = {'st','st','st','st','st','st','st','st',... 'al1','al1','al1','al1','al1','al1',... 'al2','al2','al2','al2','al2','al2'};
이 데이터는 호그(Hogg)의 구조적 빔 강도에 대한 연구(1987년)에서 얻은 것입니다. 벡터 strength는 3000파운드 힘이 가해진 상황에서 천 분의 일 인치 단위로 빔의 굴절을 측정합니다. 벡터 alloy는 각 빔을 강철(st), 합금 1(al1) 또는 합금 2(al2)로 식별합니다. 이 예제에서는 합금이 순서대로 정렬되어 있지만 그룹화 변수를 항상 정렬할 필요는 없습니다.
anova1을 사용하여 일원분산분석을 수행합니다. multcompare가 Multiple Comparisons를 수행하는 데 필요한 통계량이 포함된 구조체 stats를 반환합니다.
[~,~,stats] = anova1(strength,alloy);


p-값이 0.0002로 작으므로 빔의 강도가 동일하지 않다는 것을 알 수 있습니다.
빔의 평균 강도에 대한 다중 비교를 수행합니다.
[c,~,~,gnames] = multcompare(stats);

그림에서 파란색 막대는 강철의 평균 재료 강도에 대한 비교 구간을 나타냅니다. 빨간색 막대는 합금 1 및 합금 2의 평균 재료 강도에 대한 비교 구간을 나타냅니다. 빨간색 막대 모두 파란색 막대와 겹치지 않습니다. 이는 강철의 평균 재료 강도가 합금 1과 합금 2의 평균 재료 강도와 현저히 다르다는 것을 나타냅니다. 합금 1과 합금 2를 나타내는 막대를 클릭하여 유의미한 차이를 확인할 수 있습니다.
여러 개의 비교 결과와 해당하는 그룹 이름을 테이블로 표시합니다.
tbl = array2table(c,"VariableNames", ... ["Group A","Group B","Lower Limit","A-B","Upper Limit","P-value"]); tbl.("Group A") = gnames(tbl.("Group A")); tbl.("Group B") = gnames(tbl.("Group B"))
tbl=3×6 table
Group A Group B Lower Limit A-B Upper Limit P-value
_______ _______ ___________ ___ ___________ __________
{'st' } {'al1'} 3.6064 7 10.394 0.00016831
{'st' } {'al2'} 1.6064 5 8.3936 0.0040464
{'al1'} {'al2'} -5.628 -2 1.628 0.35601
처음 두 열은 비교되는 그룹 쌍을 보여줍니다. 네 번째 열은 추정된 그룹 평균 간 차이를 보여줍니다. 세 번째 열과 다섯 번째 열은 실제 평균 차에 대한 95% 신뢰구간의 하한과 상한을 보여줍니다. 여섯 번째 열은 해당 그룹 간 실제 평균 차가 0이라는 가설에 대한 p-값을 보여줍니다.
처음 두 행은 첫 번째 그룹(강철)을 포함하는 두 비교 모두 0을 포함하지 않는 신뢰구간을 갖는다는 것을 보여줍니다. 해당 p-값(각각 1.6831e-04 및 0.0040)이 작기 때문에 이들 빔 간 차이는 유의한 수준입니다.
세 번째 행은 두 합금 간 강도 차이가 유의한 수준이 아니라는 것을 보여줍니다. 차이에 대한 95% 신뢰구간은 [-5.6,1.6]이며, 따라서 실제 차이가 0이라는 가설을 기각할 수 없습니다. 여섯 번째 열에 표시되는 해당 p-값이 0.3560인 것을 통해 이 결과를 확인할 수 있습니다.
입력 인수
표본 데이터로, 벡터 또는 행렬로 지정됩니다.
y가 벡터인 경우group입력 인수를 지정해야 합니다.group의 각 요소는 이에 대응하는y요소의 그룹 이름을 나타냅니다.anova1함수는group의 동일한 값에 대응되는y값들을 같은 그룹의 일부로 취급합니다. 그룹이 각각 다른 개수의 요소를 갖는 경우 이 설계를 사용합니다(불균형 분산분석).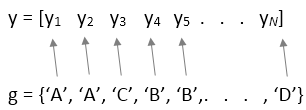
y가 행렬이고group을 지정하지 않은 경우,anova1은y의 각 열을 별도의 그룹으로 취급합니다. 이 경우 함수는 각 열별로 모집단 평균이 동일한지 여부를 평가합니다. 각 그룹이 동일한 개수의 요소를 갖는 경우 이 설계를 사용합니다(균형 분산분석).
y가 행렬이고group을 지정하는 경우,group의 각 요소는 이에 대응하는y열의 그룹 이름을 나타냅니다.anova1함수는 동일한 그룹 이름을 갖는 열을 동일한 그룹의 일부로 취급합니다.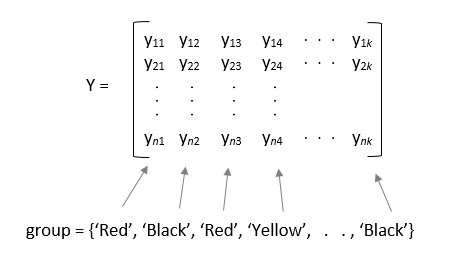
참고
anova1은 y에 포함된 NaN 값을 무시합니다. 또한 group이 비어 있거나 NaN 값을 포함하는 경우 anova1은 y에서 이에 대응되는 관측값을 무시합니다. anova1 함수는 빈 값이나 NaN 값을 무시한 후에 각 그룹의 관측값 개수가 동일하면 균형 분산분석을 수행합니다. 그렇지 않은 경우 anova1은 불균형 분산분석을 수행합니다.
데이터형: single | double
그룹 이름을 포함하는 그룹화 변수로, 숫자형 벡터, 논리형 벡터, categorical형 벡터, 문자형 배열, string형 배열 또는 문자형 벡터로 구성된 셀형 배열로 지정됩니다.
y가 벡터인 경우group의 각 요소는 이에 대응하는y요소의 그룹 이름을 나타냅니다.anova1함수는group의 동일한 값에 대응되는y값들을 같은 그룹의 일부로 취급합니다.N은 총 관측값 개수입니다.
y가 행렬인 경우group의 각 요소는 이에 대응하는y열의 그룹 이름을 나타냅니다.anova1함수는 동일한 그룹 이름을 갖는y의 열들을 동일한 그룹의 일부로 취급합니다.행렬 표본 데이터
y의 그룹 이름을 지정하지 않으려는 경우에는 빈 배열([])을 입력하거나 이 인수를 생략하십시오. 이 경우,anova1은y의 각 열을 별도의 그룹으로 취급합니다.
group이 비어 있거나 NaN 값을 포함하는 경우 anova1은 y에서 이에 대응되는 관측값을 무시합니다.
그룹화 변수에 대한 자세한 내용은 그룹화 변수 항목을 참조하십시오.
예: y가 그룹 1, 2, 3으로 분류된 관측값을 갖는 벡터인 경우 'group',[1,2,1,3,1,...,3,1]
예: y가 빨간색, 흰색, 검은색 그룹으로 분류된 5개 열을 갖는 행렬인 경우 'group',{'white','red','white','black','red'}
데이터형: single | double | logical | categorical | char | string | cell
분산분석표와 상자 플롯을 표시할지를 나타내는 표시자로, 'on' 또는 'off'로 지정됩니다. displayopt가 'off'인 경우, anova1은 출력 인수만 반환합니다. 표준 분산분석표와 상자 플롯은 표시하지 않습니다.
예: p = anova(x,group,'off')
출력 인수
세부 정보
anova1은 y에 있는 각 그룹의 관측값에 대한 상자 플롯을 반환합니다. 상자 플롯은 그룹 위치 모수에 대한 시각적 비교를 제공합니다.
각 상자에서 중앙에 있는 표시가 중앙값(제2사분위수, q2)이고 상자의 가장자리가 25번째 백분위수(제1사분위수, q1)와 75번째 백분위수(제3사분위수, q3)입니다. 수염(Whisker)은 이상값으로 간주되지 않는 최대 또는 최소 데이터 점까지 확장됩니다. 이상값은 '+' 기호를 사용하여 개별적으로 플로팅됩니다. 수염의 극값은 q3 + 1.5 × (q3 – q1) 및 q1 – 1.5 × (q3 – q1)에 대응됩니다.
상자 플롯에는 중앙값 비교를 위한 노치가 있습니다. 두 중앙값은 노치로 나타낸 구간이 겹쳐지지 않는 경우 5% 유의수준에서 현저히 다릅니다. 이 검정은 분산분석에서 수행하는 F-검정과 다릅니다. 하지만 상자에서 중심선의 차이가 크면 F-통계량 값이 큰 것을 나타내며 따라서 p-값이 작음을 나타냅니다. 노치의 극값은 q2 – 1.57(q3 – q1)/sqrt(n) 및 q2 + 1.57(q3 – q1)/sqrt(n)에 대응됩니다. 여기서 n은 NaN 값을 제외한 관측값 개수입니다. 경우에 따라 노치가 상자 외부로 확장될 수 있습니다.

대체 기능
anova1 함수를 사용하는 대신에, anova 함수를 사용하여 anova 객체를 만들 수 있습니다. anova 함수는 다음과 같은 이점을 제공합니다.
anova함수를 사용하면 분산분석 모델 유형, 제곱합 유형, 범주형으로 처리할 인자를 지정할 수 있습니다.anova는 또한 table형 예측 변수와 응답 변수를 입력 인수로 사용할 수 있습니다.anova1에서 반환하는 출력값 외에,anova객체의 속성에는 다음이 포함됩니다.분산분석 모델식
피팅된 분산분석 모델 계수
잔차
인자와 응답 변수 데이터
anova객체 함수를 사용하면anova객체를 피팅한 후 추가 분석을 수행할 수 있습니다. 예를 들어 분산분석을 위해 평균에 대한 다중 비교를 대화형 플롯으로 만들고, 인자의 각 값에 대해 평균 응답 변수의 추정값을 구하고, 분산 성분 추정값을 계산할 수 있습니다.
참고 문헌
[1] Hogg, R. V., and J. Ledolter. Engineering Statistics. New York: MacMillan, 1987.
버전 내역
R2006a 이전에 개발됨
참고 항목
anova | anova2 | anovan | boxplot | multcompare