이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
일원분산분석(One-way ANOVA)
일원분산분석 소개
함수 anova1을 사용하여 일원분산분석을 수행할 수 있습니다. 일원분산분석의 목적은 인자의 여러 그룹(수준)에 있는 데이터가 공통 평균을 갖는지 확인하는 것입니다. 즉, 일원분산분석을 수행하면 독립 변수의 각 그룹에 따라 응답 변수 y에 서로 다른 영향을 미치는지 알 수 있습니다. 한 병원에서 새로 제안된 두 가지 예약 방식이 예전의 예약 방식보다 환자 대기 시간을 더 줄여주는지 확인하고자 한다고 가정하겠습니다. 이 경우 독립 변수는 예약 방식이고, 응답 변수는 환자의 대기 시간입니다.
일원분산분석은 선형 모델을 보여주는 단순하고 특별한 사례입니다. 모델의 일원분산분석 형식은 다음과 같습니다.
여기서는 다음과 같이 가정합니다.
yij는 관측값입니다. 여기서 i는 관측값 개수를 나타내고, j는 변수 y의 서로 다른 그룹(수준)을 나타냅니다. 모든 yij는 서로 독립적입니다.
αj는 j번째 그룹(수준 또는 처리)의 모집단 평균을 나타냅니다.
εij는 독립적이고 정규분포된 랜덤 오차로, 평균이 0이고 일정한 분산을 갖습니다. 즉, εij ~ N(0,σ2)입니다.
이 모델을 평균 모델이라고도 합니다. 이 모델에서는 y의 열이 상수 αj에 오차 성분 εij를 더한 것이라고 가정합니다. 분산분석을 수행하면 상수가 모두 동일한지 쉽게 확인할 수 있습니다.
분산분석에서는 '모든 그룹의 평균이 같다'()는 가설과 '적어도 하나의 그룹 평균이 다른 그룹 평균과 다르다'(최소 하나의 i와 j에 대해 )는 대립가설을 비교하여 검정합니다. anova1(y)는 행렬 y에 있는 데이터의 열 평균이 동일한지 검정합니다. 여기서 각 열은 서로 다른 그룹이고 동일한 개수의 관측값을 갖습니다(즉, 균형 설계임). anova1(y,group)은 벡터 또는 행렬 y에 있는 데이터의 그룹 평균값(group으로 지정됨)이 동일한지 검정합니다. 이 경우, 각 그룹 또는 열은 서로 다른 개수의 관측값을 가질 수 있습니다(즉, 불균형 설계임).
분산분석은 모든 표본 모집단이 정규분포된다는 가정에 기반합니다. 분산분석은 이 가정에 조금 위반되는 경우에는 영향을 덜 받는(robust) 것으로 알려져 있습니다. 정규성 플롯(normplot)을 사용하여 시각적으로 정규성 가정을 확인할 수 있습니다. 또는 Statistics and Machine Learning Toolbox™ 함수들 중에서 정규성을 확인하는 함수를 사용할 수 있습니다. 즉, 앤더슨-달링 검정(adtest), 카이제곱 적합도 검정(chi2gof), 자크-베라 검정(jbtest) 또는 릴리포스 검정(lillietest) 중에서 하나를 선택할 수 있습니다.
일원분산분석을 위한 데이터 준비하기
표본 데이터를 벡터 또는 행렬로 제공할 수 있습니다.
표본 데이터가 벡터
y의 형태인 경우,group입력 변수를 사용하여 그룹화 정보(anova1(y,group))를 제공해야 합니다.group은y의 각 요소에 대한 이름을 포함하는 숫자형 벡터, 논리형 벡터, categorical형 벡터, 문자형 배열, string형 배열, 또는 문자형 벡터로 구성된 셀형 배열이어야 합니다.anova1함수는group의 동일한 값에 대응되는y값들을 같은 그룹의 일부로 취급합니다. 예를 들면 다음과 같습니다.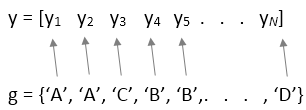
그룹이 각각 다른 개수의 요소를 갖는 경우 이 설계를 사용합니다(불균형 분산분석).
표본 데이터가 행렬
y의 형태인 경우 그룹 정보를 제공하는 것은 선택 사항입니다.입력 변수
group을 지정하지 않는 경우,anova1은y의 각 열을 별도의 그룹으로 처리하고 각 열별로 모집단 평균이 동일한지 여부를 평가합니다. 예를 들면 다음과 같습니다.
각 그룹이 동일한 개수의 요소를 갖는 경우 이 설계의 형식을 사용합니다(균형 분산분석).
입력 변수
group을 지정하는 경우,group의 각 요소는 이에 대응하는y의 열에 대한 그룹 이름을 나타냅니다.anova1함수는 동일한 그룹 이름을 갖는 열을 동일한 그룹의 일부로 처리합니다. 예를 들면 다음과 같습니다.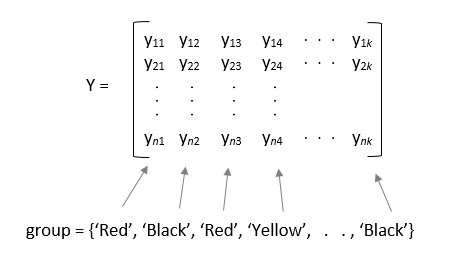
anova1은 y에 포함된 NaN 값을 무시합니다. 또한 group이 비어 있거나 NaN 값을 포함하는 경우 anova1은 y에서 이에 대응되는 관측값을 무시합니다. anova1 함수는 빈 값이나 NaN 값을 무시한 후에 각 그룹의 관측값 개수가 동일하면 균형 분산분석을 수행합니다. 그렇지 않은 경우 anova1은 불균형 분산분석을 수행합니다.
일원분산분석 수행하기
이 예제에서는 일원분산분석을 사용하여 여러 그룹에 있는 데이터가 공통 평균을 갖는지 확인하는 방법을 보여줍니다.
표본 데이터를 불러와서 표시합니다.
load hogg
hogghogg = 6×5
24 14 11 7 19
15 7 9 7 24
21 12 7 4 19
27 17 13 7 15
33 14 12 12 10
23 16 18 18 20
이 데이터는 출하된 우유에 포함된 박테리아 수를 조사한 Hogg와 Ledolter의 연구(1987)에서 가져온 것입니다. 행렬 hogg의 열은 서로 다른 출하를 나타냅니다. 행은 각 출하에서 무작위로 선택된 우유 팩에서 검출된 박테리아 수입니다.
일부 출하가 다른 출하에 비해 박테리아 수가 더 많은지 검정합니다. 기본적으로 anova1은 두 개의 Figure를 반환합니다. 하나는 표준 분산분석표이고, 다른 하나는 그룹별 데이터에 대한 상자 플롯입니다.
[p,tbl,stats] = anova1(hogg);


p
p = 1.1971e-04
p-값이 약 0.0001로 작은 것은 각 출하마다 박테리아 수가 같지 않음을 나타냅니다.
상자 플롯을 살펴보면 평균이 서로 다르다는 것을 시각적으로 확실히 알 수 있습니다. 그러나 노치는 평균이 아닌 중앙값을 비교합니다. 이 표시에 대한 자세한 내용은 boxplot 항목을 참조하십시오.
표준 분산분석표를 확인합니다. anova1은 표준 분산분석표를 출력 인수 tbl에 셀형 배열로 저장합니다.
tbl
tbl=4×6 cell array
{'Source' } {'SS' } {'df'} {'MS' } {'F' } {'Prob>F' }
{'Columns'} {[ 803.0000]} {[ 4]} {[200.7500]} {[ 9.0076]} {[1.1971e-04]}
{'Error' } {[ 557.1667]} {[25]} {[ 22.2867]} {0×0 double} {0×0 double }
{'Total' } {[1.3602e+03]} {[29]} {0×0 double} {0×0 double} {0×0 double }
변수 Fstat에 F-통계량 값을 저장합니다.
Fstat = tbl{2,5}Fstat = 9.0076
그룹 평균에 대한 다중 쌍별 비교를 하는 데 필요한 통계량을 확인합니다. anova1은 이러한 통계량을 구조체 stats에 저장합니다.
stats
stats = struct with fields:
gnames: [5×1 char]
n: [6 6 6 6 6]
source: 'anova1'
means: [23.8333 13.3333 11.6667 9.1667 17.8333]
df: 25
s: 4.7209
분산분석은 모든 그룹 평균이 동일하다는 귀무가설을 기각합니다. 따라서 다중 비교를 통해 어떤 그룹의 평균이 다른 그룹의 평균과 다른지 확인할 수 있습니다. 다중 비교 검정을 수행하려면 stats를 입력 인수로 받는 함수 multcompare를 사용해야 합니다. 이 예제에서 anova1은 4건의 모든 출하에서 검출된 평균 박테리아 수가 서로 동일하다는 귀무가설, 즉 를 기각합니다.
다중 비교 검정을 수행하여 평균 박테리아 수를 기준으로 했을 때 어느 출하가 나머지 출하와 다른지 확인합니다.
results = multcompare(stats);
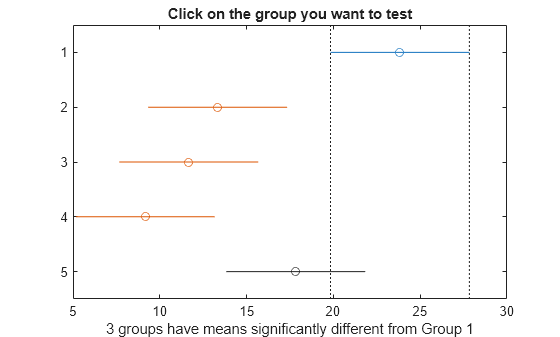
Figure에서도 동일한 결과를 보여줍니다. 파란색 막대는 첫 번째 그룹 평균의 비교 구간을 보여주며, 이 비교 구간은 빨간색으로 표시된 두 번째, 세 번째, 네 번째 그룹 평균의 비교 구간과 겹치지 않습니다. 회색으로 표시된 다섯 번째 그룹 평균의 비교 구간은 첫 번째 그룹 평균의 비교 구간과 겹칩니다. 따라서 첫 번째와 다섯 번째 그룹의 그룹 평균이 크게 서로 다르지 않습니다.
여러 개의 비교 결과를 테이블로 표시합니다.
tbl = array2table(results,"VariableNames", ... ["Group A","Group B","Lower Limit","A-B","Upper Limit","P-value"])
tbl=10×6 table
Group A Group B Lower Limit A-B Upper Limit P-value
_______ _______ ___________ _______ ___________ _________
1 2 2.4953 10.5 18.505 0.0059332
1 3 4.1619 12.167 20.171 0.0012925
1 4 6.6619 14.667 22.671 0.0001262
1 5 -2.0047 6 14.005 0.21195
2 3 -6.3381 1.6667 9.6714 0.97193
2 4 -3.8381 4.1667 12.171 0.55436
2 5 -12.505 -4.5 3.5047 0.48062
3 4 -5.5047 2.5 10.505 0.88757
3 5 -14.171 -6.1667 1.8381 0.19049
4 5 -16.671 -8.6667 -0.66193 0.029175
처음 두 열은 어느 두 그룹끼리 평균을 비교했는지 보여줍니다. 예를 들어, 첫 번째 행은 그룹 1과 2의 평균을 비교한 것입니다. 마지막 열은 검정에 대한 p-값을 보여줍니다. p-값 0.0059, 0.0013, 0.0001은 첫 번째 출하된 우유의 평균 박테리아 수가 두 번째, 세 번째, 네 번째 출하된 우유의 평균 박테리아 수와 다르다는 것을 나타냅니다. p- 값 0.0292는 네 번째 출하된 우유의 평균 박테리아 수가 다섯 번째 출하된 우유의 평균 박테리아 수와 다르다는 것을 나타냅니다. 이 절차에서는 다른 그룹 평균이 서로 다르다는 가설을 기각하지 않습니다.
수학적 세부 정보
분산분석은 데이터의 전체 변동을 다음의 두 성분으로 분할하여 그룹 평균의 차이를 검정합니다.
전체 평균으로부터 그룹 평균의 변동, 즉 (그룹 간 변동). 여기서, 는 그룹 j의 표본평균이고, 는 전체 표본평균입니다.
그룹 평균 추정값으로부터 각 그룹 관측값의 변동, 즉 (그룹 내 변동).
다시 말해서, 분산분석은 총 제곱합(SST)을 그룹 간 효과로 인한 제곱합(SSR)과 오차제곱합(SSE)으로 분할합니다.
여기서 nj는 j번째 그룹의 표본 크기이고, j = 1, 2, ..., k입니다.
그런 다음 분산분석은 그룹 간 변동을 그룹 내 변동과 비교합니다. 그룹 내 변동에 대한 그룹 간 변동의 비율이 높으면 그룹 평균이 서로 현저히 다르다는 결론을 내릴 수 있습니다. 이 비율은 자유도가 (k – 1, N – k)인 F-분포를 갖는 검정 통계량을 사용하여 측정할 수 있습니다.
여기서 MSR은 평균제곱 처리이고, MSE는 평균제곱오차이며, k는 그룹 수, N은 총 관측값 개수입니다. F-통계량의 p-값이 유의수준보다 작기 때문에, 검정은 '모든 그룹 평균이 동일하다'는 귀무가설을 기각하고, '적어도 하나의 그룹 평균이 다른 그룹 평균과 다르다'는 결론을 내립니다. 가장 일반적인 유의수준은 0.05와 0.01입니다.
분산분석표
분산분석표는 요인별로 나눈 모델의 변동성과 이 변동성의 유의성을 검정하기 위한 F-통계량, 이 변동성의 유의성을 결정하기 위한 p-값을 포착합니다. anova1에 의해 반환된 p-값은 모델 방정식의 확률 교란 εij에 대한 가정에 따라 결정됩니다. p-값이 정확하려면 확률 교란이 서로 독립적이고 정규분포되며 일정한 분산을 가져야 합니다. 표준 분산분석표의 형식은 다음과 같습니다.

anova1은 표준 분산분석표를 6개의 열을 갖는 셀형 배열로 반환합니다.
| 열 | 정의 |
|---|---|
Source | 변동성의 요인입니다. |
SS | 각 요인에 의한 제곱합입니다. |
df | 각 요인와 연관된 자유도입니다. N은 총 관측값 개수이고 k는 그룹 개수라고 가정합니다. 이 경우, N – k는 그룹 내 자유도(Error)이고, k – 1은 그룹 간 자유도(Columns)이며, N – 1은 총 자유도입니다. 여기서 N – 1 = (N – k) + (k – 1)입니다. |
MS | 각 요인의 평균제곱으로, SS/df 비율입니다. |
F | F-통계량으로, 두 평균제곱 간의 비율입니다. |
Prob>F | p-값으로, 계산된 검정-통계량 값보다 F-통계량이 더 큰 값을 취할 수 있는 확률입니다. anova1은 F-분포의 cdf에서 이 확률을 도출합니다. |
분산분석표의 각 행은 데이터의 변동성을 요인별로 나누어 보여줍니다.
| 행(요인) | 정의 |
|---|---|
Groups 또는 Columns | 그룹 평균 간 차이로 인한 변동성(그룹 간 변동성) |
Error | 각 그룹의 데이터와 그룹 평균 간의 차이로 인한 변동성(그룹 내 변동성) |
Total | 총 변동성 |
참고 문헌
[1] Wu, C. F. J., and M. Hamada. Experiments: Planning, Analysis, and Parameter Design Optimization, 2000.
[2] Neter, J., M. H. Kutner, C. J. Nachtsheim, and W. Wasserman. 4th ed. Applied Linear Statistical Models. Irwin Press, 1996.
참고 항목
anova | anova1 | multcompare | kruskalwallis