이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
anovan
다원분산분석
구문
설명
p = anovan(y,group,Name,Value)Name,Value 쌍 인수로 지정된 추가 옵션을 사용하여 다원분산분석(n-way ANOVA)에 대한 p-값으로 구성된 벡터를 반환합니다.
예를 들어, 어떤 예측 변수가 연속형 예측 변수인지 여부, 또는 사용할 제곱합 유형을 지정할 수 있습니다.
[은 어떤 그룹 평균의 쌍이 현저히 다른지 판별할 수 있게 해주는 다중 비교 검정을 수행하는 데 사용할 수 있는 p,tbl,stats] = anovan(___)stats 구조체를 반환합니다. stats 구조체를 입력값으로 하여 multcompare 함수를 사용하여 이러한 검정을 수행할 수 있습니다.
예제
표본 데이터를 불러옵니다.
y = [52.7 57.5 45.9 44.5 53.0 57.0 45.9 44.0]';
g1 = [1 2 1 2 1 2 1 2];
g2 = {'hi';'hi';'lo';'lo';'hi';'hi';'lo';'lo'};
g3 = {'may';'may';'may';'may';'june';'june';'june';'june'};y는 응답 변수 벡터이고 g1, g2, g3은 그룹화 변수(인자)입니다. 각 인자는 두 개의 수준을 가지며, y의 각 관측값은 인자수준 조합으로 식별됩니다. 예를 들어, 관측값 y(1)은 인자 g1의 수준 1, 인자 g2의 수준 'hi', 인자 g3의 수준 'may'와 연결됩니다. 마찬가지로, 관측값 y(6)은 인자 g1의 수준 2, 인자 g2의 수준 'hi', 인자 g3의 수준 'june'과 연결됩니다.
응답 변수가 모든 인자수준에서 동일한지 검정합니다.
p = anovan(y,{g1,g2,g3})
p = 3×1
0.4174
0.0028
0.9140
분산분석표에서 X1, X2, X3은 각각 인자 g1, g2, g3에 대응됩니다. p-값 0.4174는 인자 g1의 수준 1과 수준 2에 대한 평균 응답 변수가 크게 다르지 않음을 나타냅니다. 마찬가지로, p-값 0.914는 인자 g3의 수준 'may' 및 'june'에 대한 평균 응답 변수가 크게 다르지 않음을 나타냅니다. 그러나, p-값 0.0028은 인자 g2의 두 수준 'hi' 및 'lo'에 대한 평균 응답 변수가 현저히 다르다는 결론을 내리기에 충분히 작습니다. 기본적으로, anovan은 세 개의 주효과에 대해서만 p-값을 계산합니다.
2인자 상호 작용을 검정합니다. 이번에는 변수 이름을 지정합니다.
p = anovan(y,{g1 g2 g3},'model','interaction','varnames',{'g1','g2','g3'})
p = 6×1
0.0347
0.0048
0.2578
0.0158
0.1444
0.5000
상호 작용 항은 분산분석표에서 g1*g2, g1*g3, g2*g3으로 표현됩니다. p의 처음 세 요소가 주효과에 대한 p-값입니다. 마지막 세 요소는 이원 상호 작용에 대한 p-값입니다. p-값 0.0158은 g1과 g2 간의 상호 작용이 유의한 수준임을 나타냅니다. p-값 0.1444 및 0.5는 해당 상호 작용이 유의한 수준이 아님을 나타냅니다.
표본 데이터를 불러옵니다.
load carbig이 데이터는 406대 차량에 대한 측정값으로 구성되어 있습니다. 변수 org는 차량이 생산된 지역을 보여주고 when은 차량이 제조된 연도를 보여줍니다.
연비가 차량이 생산된 연도와 지역에 따라 어떻게 달라지는지를 확인합니다. 또한, 모델에 이원 상호 작용도 포함시킵니다.
p = anovan(MPG,{org when},'model',2,'varnames',{'origin','mfg date'})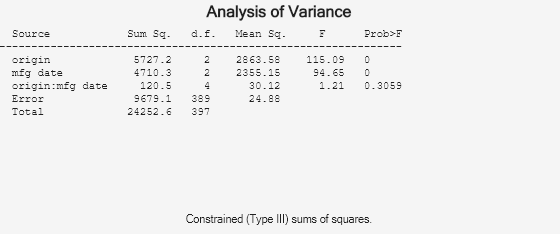
p = 3×1
0.0000
0.0000
0.3059
'model',2 이름-값 쌍의 인수는 이원 상호 작용을 나타냅니다. 상호 작용 항에 대한 p-값 0.3059는 작은 수준이 아니며, 제조 시기(mfg date)의 효과가 차량이 생산된 지역(origin)에 따라 달라짐을 보여주는 증거가 거의 없음을 나타냅니다. 그러나 원산지와 제조 날짜의 주효과는 유의한 수준이며, p-값이 모두 0입니다.
표본 데이터를 불러옵니다.
y = [52.7 57.5 45.9 44.5 53.0 57.0 45.9 44.0]'; g1 = [1 2 1 2 1 2 1 2]; g2 = ["hi" "hi" "lo" "lo" "hi" "hi" "lo" "lo"]; g3 = ["may" "may" "may" "may" "june" "june" "june" "june"];
y는 응답 변수 벡터이고 g1, g2, g3은 그룹화 변수(인자)입니다. 각 인자는 두 개의 수준을 가지며, y의 각 관측값은 인자수준 조합으로 식별됩니다. 예를 들어, 관측값 y(1)은 인자 g1의 수준 1, 인자 g2의 수준 hi, 인자 g3의 수준 may와 연결됩니다. 마찬가지로, 관측값 y(6)은 인자 g1의 수준 2, 인자 g2의 수준 hi, 인자 g3의 수준 june과 연결됩니다.
응답 변수가 모든 인자수준에서 동일한지 검정합니다. 또한, 다중 비교 검정에 필요한 통계량을 계산합니다.
[~,~,stats] = anovan(y,{g1 g2 g3},"Model","interaction", ...
"Varnames",["g1","g2","g3"]);
p-값 0.2578은 인자 g3의 수준 may 및 june에 대한 평균 응답 변수가 크게 다르지 않음을 나타냅니다. p-값 0.0347은 인자 g1의 수준 1 및 2에 대한 평균 응답 변수가 현저히 다름을 나타냅니다. 마찬가지로, p-값 0.0048은 인자 g2의 수준 hi 및 lo에 대한 평균 응답 변수가 현저히 다름을 나타냅니다.
다중 비교 검정을 수행하여 인자 g1 및 g2 그룹 중 현저히 다른 그룹을 찾아냅니다.
[results,~,~,gnames] = multcompare(stats,"Dimension",[1 2]);
이 그룹에 대응되는 비교 구간을 클릭하여 다른 그룹에 대해 검정을 수행할 수 있습니다. 막대를 클릭하면 파란색으로 바뀝니다. 현저히 다른 그룹의 막대는 빨간색으로 표시됩니다. 크게 다르지 않은 그룹의 막대는 회색으로 표시됩니다. 예를 들어, g1의 수준 1과 g2의 수준 lo의 조합에 대한 비교 구간을 클릭하면 g1의 수준 2와 g2의 수준 lo의 조합에 대한 비교 구간이 겹치므로 회색으로 표시됩니다. 반대로, 다른 비교 구간은 빨간색으로 표시되며, 이는 현저한 차이가 있음을 나타냅니다.
여러 개의 비교 결과와 해당하는 그룹 이름을 테이블로 표시합니다.
tbl = array2table(results,"VariableNames", ... ["Group A","Group B","Lower Limit","A-B","Upper Limit","P-value"]); tbl.("Group A")=gnames(tbl.("Group A")); tbl.("Group B")=gnames(tbl.("Group B"))
tbl=6×6 table
Group A Group B Lower Limit A-B Upper Limit P-value
______________ ______________ ___________ _____ ___________ _________
{'g1=1,g2=hi'} {'g1=2,g2=hi'} -6.8604 -4.4 -1.9396 0.027249
{'g1=1,g2=hi'} {'g1=1,g2=lo'} 4.4896 6.95 9.4104 0.016983
{'g1=1,g2=hi'} {'g1=2,g2=lo'} 6.1396 8.6 11.06 0.013586
{'g1=2,g2=hi'} {'g1=1,g2=lo'} 8.8896 11.35 13.81 0.010114
{'g1=2,g2=hi'} {'g1=2,g2=lo'} 10.54 13 15.46 0.0087375
{'g1=1,g2=lo'} {'g1=2,g2=lo'} -0.8104 1.65 4.1104 0.07375
multcompare 함수는 두 가지 그룹화 변수 g1 및 g2의 그룹(수준) 조합을 비교합니다. 예를 들어, 행렬의 첫 번째 행은 g1의 수준 1과 g2의 수준 hi의 조합이 g1의 수준 2와 g2의 수준 hi의 조합과 평균 응답 변수 값이 같음을 보여줍니다. 이 검정에 대응되는 p-값은 0.0272이며, 이는 평균 응답 변수가 현저히 다름을 나타냅니다. 그림에서 이 결과를 확인할 수도 있습니다. 파란색 막대는 g1의 수준 1과 g2의 수준 hi의 조합에 대한 평균 응답 변수의 비교 구간을 보여줍니다. 빨간색 막대는 다른 그룹 조합에 대한 평균 응답 변수의 비교 구간입니다. 빨간색 막대는 파란색 막대와 겹치지 않으며, 이는 g1의 수준 1과 g2의 수준 hi의 조합에 대한 평균 응답 변수가 다른 그룹 조합에 대한 평균 응답 변수와 현저히 다르다는 것을 의미합니다.
입력 인수
이름-값 인수
출력 인수
대체 기능
anovan 함수를 사용하는 대신에, anova 함수를 사용하여 anova 객체를 만들 수 있습니다. anova 함수는 다음과 같은 이점을 제공합니다.
anova함수를 사용하면 분산분석 모델 유형, 제곱합 유형, 범주형으로 처리할 인자를 지정할 수 있습니다.anova는 또한 table형 예측 변수와 응답 변수를 입력 인수로 사용할 수 있습니다.anovan에서 반환하는 출력값 외에,anova객체의 속성에는 다음이 포함됩니다.분산분석 모델식
피팅된 분산분석 모델 계수
잔차
인자와 응답 변수 데이터
anova객체 함수를 사용하면anova객체를 피팅한 후 추가 분석을 수행할 수 있습니다. 예를 들어 분산분석을 위해 평균에 대한 다중 비교를 대화형 플롯으로 만들고, 인자의 각 값에 대해 평균 응답 변수의 추정값을 구하고, 분산 성분 추정값을 계산할 수 있습니다.
참고 문헌
[1] Dunn, O.J., and V.A. Clark. Applied Statistics: Analysis of Variance and Regression. New York: Wiley, 1974.
[2] Goodnight, J.H., and F.M. Speed. Computing Expected Mean Squares. Cary, NC: SAS Institute, 1978.
[3] Seber, G. A. F., and A. J. Lee. Linear Regression Analysis. 2nd ed. Hoboken, NJ: Wiley-Interscience, 2003.
버전 내역
R2006a 이전에 개발됨