희소 행렬 연산
연산 효율성
계산 복잡도
희소 연산에 대한 계산 복잡도는 행렬에 포함된 0이 아닌 요소 개수인 nnz에 비례합니다. 계산 복잡도는 행렬의 행 크기 m과 열 크기 n과도 선형적으로 비례하지만, 행 크기와 열 크기의 곱인 m*n, 0인 요소와 0이 아닌 요소의 총 개수와는 독립적입니다.
희소 선형 방정식의 해와 같이 꽤 복잡한 연산의 복잡도는 정렬과 필인(Fill-in)(이전 섹션에 설명되어 있음) 같은 요소와 관련이 있습니다. 그러나, 일반적으로 희소 행렬 연산에 필요한 컴퓨터 실행 시간은 0이 아닌 수량에 대한 산술 연산의 개수에 비례합니다.
알고리즘 세부 정보
희소 행렬은 다음 규칙에 따라 계산을 통해 전파됩니다.
행렬을 받고 스칼라나 일정한 크기의 벡터를 반환하는 함수는 항상 비희소 저장 형식으로 출력값을 생성합니다. 예를 들어,
size함수는 해당 입력값이 비희소 벡터이든 희소 벡터이든 상관없이 항상 비희소 벡터를 반환합니다.스칼라나 벡터를 받고 행렬을 반환하는 함수(예:
zeros,ones,rand,eye)는 항상 비희소 형식 결과를 반환합니다. 이는 예기치 않게 희소성이 생기게 되는 것을 방지하려는 경우 반드시 필요합니다.zeros(m,n)의 희소 아날로그는 단순히sparse(m,n)입니다.rand와eye의 희소 아날로그는 각각sprand와speye입니다. 함수ones에 대한 희소 아날로그는 없습니다.행렬을 받고 행렬이나 벡터를 반환하는 단항 함수는 피연산자의 저장소 클래스를 유지합니다.
S가 희소 행렬이면chol(S)도 희소 행렬이고diag(S)는 희소 벡터입니다.max와sum과 같이 열을 기준으로 하는 함수도 희소 벡터를 반환합니다. 이러한 벡터가 모두 0이 아닌 요소로 구성된 경우에도 마찬가지입니다. 이 규칙에 대한 중요한 예외 사항은sparse함수와full함수입니다.이항 연산자는 두 피연산자가 모두 희소 형식인 경우 희소 형식 결과를 생성하고, 두 피연산자가 모두 비희소 형식인 경우 비희소 형식 결과를 생성합니다. 피연산자가 혼합된 경우 연산이 희소성을 유지하지 않는 한 결과는 비희소 형식입니다.
S는 희소 형식이고F는 비희소 형식인 경우S+F,S*F,F\S는 비희소 형식인 반면,S.*F와S&F는 희소 형식입니다. 경우에 따라, 행렬에 0 요소가 거의 없더라도 결과는 희소 형식일 수 있습니다.cat함수나 대괄호를 사용하는 행렬 결합은 혼합된 피연산자에 대해 희소 형식 결과를 생성합니다.
치환과 재정렬(Reordering)
희소 행렬 S의 행과 열에 대한 치환은 다음 두 가지 방법으로 나타낼 수 있습니다.
치환 행렬
P는P*S로S의 행에 대해 동작을 수행하거나S*P'로 열에 대해 동작을 수행합니다.1:n의 치환을 포함하는 비희소 벡터(Full Vector)인 치환 벡터p는S(p,:)로S의 열에 대해 동작을 수행하거나S(:,p)로 열에 대해 동작을 수행합니다.
예를 들면 다음과 같습니다.
p = [1 3 4 2 5] I = eye(5,5); P = I(p,:) e = ones(4,1); S = diag(11:11:55) + diag(e,1) + diag(e,-1)
p =
1 3 4 2 5
P =
1 0 0 0 0
0 0 1 0 0
0 0 0 1 0
0 1 0 0 0
0 0 0 0 1
S =
11 1 0 0 0
1 22 1 0 0
0 1 33 1 0
0 0 1 44 1
0 0 0 1 55이제 치환 벡터 p와 치환 행렬 P를 사용하여 몇 가지 치환을 시험해 볼 수 있습니다. 예를 들어, S(p,:)와 P*S는 동일한 행렬을 반환하는 명령문입니다.
S(p,:)
ans =
11 1 0 0 0
0 1 33 1 0
0 0 1 44 1
1 22 1 0 0
0 0 0 1 55P*S
ans =
11 1 0 0 0
0 1 33 1 0
0 0 1 44 1
1 22 1 0 0
0 0 0 1 55마찬가지로 S(:,p)와 S*P' 둘 다 다음을 반환합니다.
S*P'
ans =
11 0 0 1 0
1 1 0 22 0
0 33 1 1 0
0 1 44 0 1
0 0 1 0 55P가 희소 행렬이면 두 표현 모두 n에 비례하여 저장 공간을 사용하며, 사용자는 이들 중 하나를 nnz(S)에 비례하여 S(시간 단위)에 적용할 수 있습니다. 벡터 표현은 좀 더 간결하고 효율적이므로, 다양한 희소 행렬 치환 루틴은 모두 비희소 행 벡터를 반환합니다. 단, 비희소 LU 분해와 호환되는 행렬을 반환하는 LU(삼각) 분해에서의 피벗 연산 치환은 예외입니다.
두 치환 표현 간에 전환하려면 다음을 입력하십시오.
n = 5; I = speye(n); Pr = I(p,:); Pc = I(:,p); pc = (1:n)*Pc
pc =
1 3 4 2 5pr = (Pr*(1:n)')'
pr =
1 3 4 2 5P의 역행렬은 단순히 R = P'입니다. p의 역행렬은 r(p) = 1:n을 사용하여 계산할 수 있습니다.
r(p) = 1:5
r =
1 4 2 3 5희소성을 위한 재정렬
행렬의 열을 재정렬하면 종종 해당 LU 인수나 QR 인수의 희소성이 가중될 수 있습니다. 행과 열을 재정렬하면 종종 해당 촐레스키 인수의 희소성이 가중될 수 있습니다. 가장 간단한 형식의 재정렬은 0이 아닌 요소의 개수를 기준으로 열을 정렬하는 것입니다. 이러한 재정렬 작업은 매우 불규칙적인 구조를 가지는 행렬에 적합한 경우가 있으며, 특히 행 또는 열의 0이 아닌 요소의 개수가 크게 다른 경우에 그렇습니다.
colperm은 각 열에서 0이 아닌 요소의 개수를 기준으로 행렬의 열을 가장 작은 값에서 가장 큰 값의 순서로 정렬하는 치환을 계산합니다.
대역폭 감소를 위한 재정렬
컷힐-맥키(Cuthill-McKee) 역치환 정렬은 행렬의 프로파일이나 대역폭을 줄이는 용도로 사용됩니다. 항상 그런 것은 아니지만 일반적으로 이 정렬은 가능한 최소 대역폭을 찾습니다. symrcm 함수는 실제로 대칭 행렬 A + A'의 0이 아닌 구조에 대해 연산을 수행하지만, 결과는 비대칭 행렬에도 유용합니다. 이 정렬은 1차원 문제, 어떤 의미로는 길고 가는 형태의 문제에서 생성된 행렬에 유용합니다.
AMD(Approximate Minimum Degree) 정렬
그래프에서 노드의 차수는 해당 노드에 대한 연결 개수입니다. 이는 인접 행렬에서 대응되는 행에 있는 0이 아닌 비대각선 요소 개수와 동일합니다. AMD 알고리즘은 가우스 소거법(Gaussian Elimination)이나 촐레스키 분해(Cholesky Factorization) 중에 이러한 차수가 변경되는 방식을 기반으로 하여 정렬을 생성합니다. 이는 복잡하고 강력한 알고리즘으로, 열 개수와 컷힐-맥키 역치환 등, 일반적으로 다른 대부분의 정렬보다 더 희소한 인수를 초래합니다. 각 노드의 차수를 추적하는 작업은 시간이 매우 많이 걸리므로 AMD 알고리즘은 정확한 차수 대신 차수에 대한 근삿값을 사용합니다.
다음 MATLAB® 함수는 AMD 알고리즘을 구현합니다.
symamd를 사용한 예제는 희소 행렬 재정렬과 분해 항목을 참조하십시오.
spparms 함수를 사용하여 알고리즘의 세부 정보와 관련된 다양한 파라미터를 변경할 수 있습니다.
colamd와 symamd에서 사용하는 알고리즘에 대한 자세한 내용은 [5] 항목을 참조하십시오. 이러한 알고리즘에서 사용하는 근사 차수(Approximate Degree)는 [1]을 기반으로 합니다.
중첩 분할 정렬
AMD(Approximate Minimum Degree) 정렬과 마찬가지로, dissect 함수에 의해 구현되는 중첩 분할 정렬 알고리즘은 행렬을 그래프의 인접 행렬로 간주하여 행렬의 행과 열을 재정렬합니다. 이 알고리즘은 그래프의 정점 쌍들을 다 함께 축소하여 문제를 훨씬 더 작은 스케일로 줄입니다. 작아진 그래프를 재정렬한 후 이 알고리즘은 투영 단계와 세분화 단계를 적용하여 그래프를 다시 원래 크기로 확장합니다.
중첩 분할 알고리즘은 양질의 재정렬을 수행하며, 다른 재정렬 기법에 비해 유한 요소 행렬에서 특히 잘 동작합니다. 중첩 분할 정렬 알고리즘에 대한 자세한 내용은 [7] 항목을 참조하십시오.
희소 행렬 분해하기
LU 분해
S가 희소 행렬인 경우 다음 명령은 P*S = L*U를 만족하는 3개의 희소 행렬 L, U, P를 반환합니다.
[L,U,P] = lu(S);
lu는 부분 피벗 연산을 사용하는 가우스 소거법으로 인수를 얻습니다. 치환 행렬 P에는 0이 아닌 요소가 n개만 있습니다. 조밀 행렬과 마찬가지로, 명령문 [L,U] = lu(S)는 곱이 S인 치환된 단위 하부 삼각 행렬과 상부 삼각 행렬을 반환합니다. lu(S)는 자체적으로 피벗 정보 없이 단일 행렬로 L과 U를 반환합니다.
출력값을 3개 갖는 [L,U,P] = lu(S) 구문은 수치 부분 피벗 연산을 통해 P를 선택하지만, 피벗 연산을 통해 LU 인수의 희소성을 향상시키지는 않습니다. 반면, 출력값을 4개 갖는 [L,U,P,Q] = lu(S) 구문은 임계값 부분 피벗 연산을 통해 P를 선택하며, LU 인수의 희소성이 향상되도록 P와 Q를 선택합니다.
다음을 사용하여 희소 행렬의 피벗 연산을 제어할 수 있습니다.
lu(S,thresh)
여기서 thresh는 [0,1] 내의 피벗 임계값입니다. 피벗 연산은 어떤 열에 있는 대각선 요소의 크기가 그 열에 있는 임의의 하부대각선 요소의 크기에 thresh를 곱한 값보다 작은 경우 수행됩니다. thresh = 0은 대각선 피벗 연산을 강제 적용합니다. 디폴트 값은 thresh = 1입니다. 출력값을 4개 갖는 구문의 경우 thresh의 디폴트 값은 0.1입니다.
3개 이하의 출력값을 갖는 lu를 호출하면 MATLAB이 행렬 분해를 수행하는 중에 희소 L 인수와 U 인수를 유지하는 데 필요한 메모리를 자동으로 할당합니다. 출력값을 4개 갖는 구문을 제외하면, MATLAB은 메모리 요구 사항 파악 및 이에 맞춘 데이터 구조체 설정을 목적으로 미리 심볼릭 LU 사전 분해를 사용하지 않습니다.
희소 행렬 재정렬과 분해
이 예제에서는 재정렬(Reordering)과 행렬 분해가 희소 행렬에 미치는 영향을 보여줍니다.
필인(Fill-in)을 줄이는 적절한 열 치환 p를 얻은 경우(symrcm이나 colamd에서 얻을 수 있음), lu(S(:,p))를 계산하면 lu(S)를 계산할 때보다 시간과 저장 공간이 적게 소요됩니다.
버키 볼(Bucky Ball) 예제를 사용하여 희소 행렬을 만듭니다.
B = bucky;
B는 각 행과 열에 정확히 세 개의 0이 아닌 요소를 갖습니다.
각각 symrcm과 symamd를 사용하여 두 개의 치환 r과 m을 만듭니다.
r = symrcm(B); m = symamd(B);
이 두 개의 치환은 대칭적 컷힐-맥키(Cuthill-McKee) 역치환 정렬과 대칭적 AMD(Approximate Minimum Degree) 정렬입니다.
spy 플롯을 만들어 다음 세 개의 다른 번호 매기기를 사용하는 버키 볼 그래프의 인접 행렬 세 개를 표시합니다. 원래 번호 매기기 방식의 오각형 기반 국소 구조는 다른 그래프에서 명확히 표시되지 않습니다.
figure subplot(1,3,1) spy(B) title('Original') subplot(1,3,2) spy(B(r,r)) title('Reverse Cuthill-McKee') subplot(1,3,3) spy(B(m,m)) title('Min Degree')
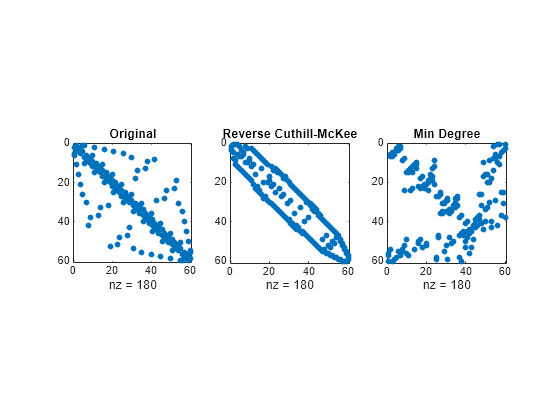
컷힐-맥키 역치환 정렬 r은 대역폭을 줄이고 0이 아닌 모든 요소를 대각선 가까이로 모읍니다. AMD(Approximate Minimum Degree) 정렬 m은 0으로 구성된 여러 블록을 갖는, 프랙털과 같은 구조를 생성합니다.
버키 볼의 LU 분해에서 생성된 필인(Fill-in)을 보려면 희소 단위 행렬을 생성하는 speye를 사용하여 B의 대각선에 -3을 삽입하십시오.
B = B - 3*speye(size(B));
이제 각 행의 합은 0이므로 이 새로운 B는 특이 행렬이지만, 여전히 LU 분해를 계산하는 데 유용합니다. lu는 출력 인수 하나만 사용하여 호출할 경우 두 개의 삼각 인수 L과 U를 단일 희소 행렬로 반환합니다. 이 행렬에서 0이 아닌 요소의 개수는 B를 포함하는 선형 시스템을 푸는 데 필요한 시간과 저장 공간을 측정한 값입니다.
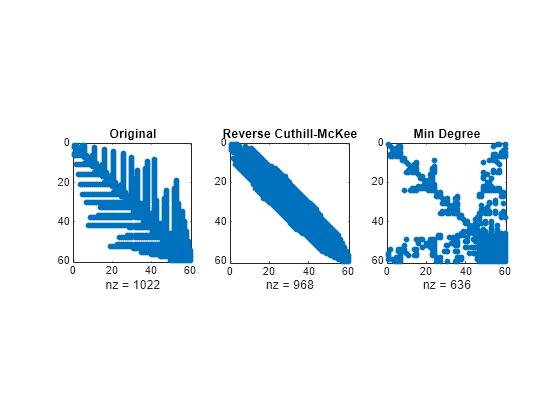
다음은 여기서 다루고 있는 세 가지 치환의 0이 아닌 요소 개수입니다.
lu(B)(원래 정렬): 1022lu(B(r,r))(컷힐-맥키 역치환): 968lu(B(m,m))(AMD(Approximate Minimum Degree)): 636
이 예는 간단하지만 전형적인 결과를 보여줍니다. 원래 번호 매기기 방식에서 필인이 가장 많이 생성됩니다. 컷힐-맥키 역치환 정렬의 필인은 대역 내에 집중되어 있지만 처음 두 개의 정렬과 거의 비슷하게 많습니다. AMD(Approximate Minimum Degree) 정렬의 경우 소거하는 동안 비교적 많은 0 블록이 유지되며, 필인의 개수는 다른 정렬에서 생성되는 것보다 현저히 적습니다.
아래의 spy 플롯에는 각 재정렬의 특성이 반영되어 있습니다.
figure subplot(1,3,1) spy(lu(B)) title('Original') subplot(1,3,2) spy(lu(B(r,r))) title('Reverse Cuthill-McKee') subplot(1,3,3) spy(lu(B(m,m))) title('Min Degree')
촐레스키 분해(Cholesky Factorization)
S가 양의 정부호 대칭(또는 에르미트(Hermitian)) 희소 행렬인 경우 아래 명령문은 R'*R = S가 되도록 희소 상부 삼각 행렬 R을 반환합니다.
R = chol(S)
chol은 희소성을 위해 자동으로 피벗 연산을 수행하지 않지만, chol(S(p,p))에 사용할 수 있도록 AMD(Approximate Minimum Degree)와 프로파일 제한 치환을 계산할 수 있습니다.
촐레스키 알고리즘은 희소성을 위해 피벗 연산을 사용하지 않고 수치적 안정성을 위해 피벗 연산을 수행할 필요가 없으므로, chol은 행렬 분해 시작 시 필요한 메모리의 양을 신속하게 계산하여 필요한 모든 메모리를 할당합니다. chol과 동일한 알고리즘을 사용하는 symbfact를 사용하여 할당할 메모리의 양을 계산할 수 있습니다.
QR 분해
MATLAB은 다음을 사용하여 희소 행렬 S에 대한 완전 QR 분해를 계산합니다.
[Q,R] = qr(S)
[Q,R,E] = qr(S)
그러나 이는 실용성이 떨어지는 경우가 종종 있습니다. 유니타리(Unitary) 행렬 Q는 대개 0 요소의 비율이 높지 않습니다. "Q-less QR 분해"라고 알려진 더 실용적인 다른 방법을 사용할 수 있습니다.
희소 형식 입력 인수 하나와 출력 인수 하나를 사용하는 다음 명령문은
R = qr(S)
QR 분해의 상부 삼각 부분만 반환합니다. 행렬 R은 정규 방정식과 연결된 행렬에 대한 촐레스키 분해를 제공합니다.
R'*R = S'*S
그러나, S'*S 계산에 있어 태생적인 수치 정보 손실 문제는 방지됩니다.
동일한 개수의 행을 갖는 두 개의 입력 인수와 두 개의 출력 인수를 사용하는 다음 명령문은
[C,R] = qr(S,B)
B에 직교 변환을 적용하여, Q를 계산하지 않고도 C = Q'*B를 생성합니다.
Q-less QR 분해를 사용하면 다음 희소 최소제곱 문제의 해를
다음 두 단계를 사용하여 구할 수 있습니다.
[c,R] = qr(A,b); x = R\c
A가 희소 행렬이지만 정사각 행렬이 아닌 경우 MATLAB은 다음 선형 방정식 풀기 백슬래시 연산자에 대해 다음 단계를 사용합니다.
x = A\b
또는, 직접 행렬 분해를 수행하고 R에 대해 랭크 부족 검사를 수행할 수 있습니다.
또한, R = qr(A)를 계산해도 반드시 구해지지 않는 각기 다른 우변 b를 가진 다른 일련의 최소제곱 선형 시스템의 해를 구할 수도 있습니다. 이 접근 방식은 "반정규 방정식" R'*R*x = A'*b의 해를 다음과 같이 구합니다.
x = R\(R'\(A'*b))
그런 다음, 반복적인 세분화 단계 하나를 수행하여 반올림 오차를 줄입니다.
r = b - A*x; e = R\(R'\(A'*r)); x = x + e
불완전 행렬 분해
ilu 함수와 ichol 함수는 희소 반복법에 대한 선조건자로 유용한 대략적인 불완전 분해를 제공합니다.
ilu 함수는 3개의 ILU(불완전 하부-상부) 분해, 즉 0 채우기(Zero-fill) ILU(ILU(0)), ILU의 크라우트 버전(ILUC(tau)), 임계값 기각과 피벗 연산을 사용한 ILU(ILUTP(tau))를 생성합니다. ILU(0)은 피벗 연산을 수행하지 않고, 결과로 생성되는 인수는 입력 행렬이 0이 아닌 요소를 갖는 위치에만 0이 아닌 요소를 가집니다. 그러나, ILUC(tau)와 ILUTP(tau)는 모두 사용자 정의 기각 허용오차 tau를 사용하여 임계값 기준 기각을 수행합니다.
예를 들어, 다음은
A = gallery('neumann',1600) + speye(1600);
nnz(A)ans =
7840nnz(lu(A))
ans =
126478A가 7840개의 0이 아닌 요소를 가지고, 해당 완전 LU 분해가 126478개의 0이 아닌 요소를 가짐을 보여줍니다. 반면, 다음 코드에서는 다른 ILU 출력값을 보여줍니다.
[L,U] = ilu(A); nnz(L)+nnz(U)-size(A,1)
ans =
7840norm(A-(L*U).*spones(A),'fro')./norm(A,'fro')
ans = 4.8874e-17
opts.type = 'ilutp';
opts.droptol = 1e-4;
[L,U,P] = ilu(A, opts);
nnz(L)+nnz(U)-size(A,1)ans =
31147norm(P*A - L*U,'fro')./norm(A,'fro')
ans = 9.9224e-05
opts.type = 'crout';
[L,U,P] = ilu(A, opts);
nnz(L)+nnz(U)-size(A,1)ans =
31083norm(P*A-L*U,'fro')./norm(A,'fro')
ans = 9.7344e-05
이러한 계산에서는 0 채우기 인수가 7840개의 0이 아닌 요소를 가지고, ILUTP(1e-4) 인수가 31147개의 0이 아닌 요소를 가지며, ILUC(1e-4) 인수가 31083개의 0이 아닌 요소를 가짐을 보여줍니다. 또한, 0 채우기 인수의 곱의 상대 허용오차는 본질적으로 A 패턴에 대해 0입니다. 마지막으로, 임계값 기각을 사용하여 생성된 행렬 분해의 상대 허용오차는 기각 허용오차와 동일한 차수가 나왔지만 이들이 항상 동일한 것은 아닙니다. 추가 옵션과 자세한 내용은 ilu 도움말 페이지를 참조하십시오.
ichol 함수는 양의 정부호 대칭 희소 행렬에 대한 0 채우기 불완전 촐레스키 분해(IC(0))는 물론, 임계값 기반 기각 불완전 촐레스키 분해(ICT(tau))도 제공합니다. 이러한 분해는 위에서 설명한 불완전 LU 분해와 유사한 형태이며, 이와 동일한 특징을 많이 갖습니다. 예를 들면 다음과 같습니다.
A = delsq(numgrid('S',200));
nnz(A)ans =
195228nnz(chol(A,'lower'))ans =
7762589A는 195228개의 0이 아닌 요소를 가지고, 재정렬을 사용하지 않은 완전 촐레스키 분해는 7762589개의 0이 아닌 요소를 가짐을 보여줍니다. 이와 반대로, 다음 예제에서L = ichol(A); nnz(L)
ans =
117216norm(A-(L*L').*spones(A),'fro')./norm(A,'fro')
ans = 3.5805e-17
opts.type = 'ict';
opts.droptol = 1e-4;
L = ichol(A,opts);
nnz(L)ans =
1166754norm(A-L*L','fro')./norm(A,'fro')
ans = 2.3997e-04
IC(0)은 A의 하부 삼각 패턴에서만 0이 아닌 요소를 가지고, A 패턴에서 인수의 곱은 서로 일치합니다. 또한, ICT(1e-4) 인수는 완전 촐레스키 인수보다 상당히 더 희소하고 A와 L*L' 간의 상대 허용오차는 기각 허용오차와 동일한 차수입니다. chol에서 제공하는 인자와 달리, ichol에서 제공하는 디폴트 인수는 하부 삼각임을 유의해야 합니다. 자세한 내용은 ichol 도움말 페이지를 참조하십시오.
고유값과 특이값
몇 개의 지정된 고유값이나 특이값을 계산하는 함수에는 두 가지가 있습니다. svds는 eigs를 기반으로 합니다.
이러한 함수는 희소 행렬과 함께 가장 많이 사용되지만, 비희소 행렬(Full Matrix)은 물론, MATLAB 코드에 정의된 선형 연산자와도 사용할 수 있습니다.
다음 명령문은
[V,lambda] = eigs(A,k,sigma)
행렬 A에서 "shift" sigma에 가장 가까운 k개의 고유값과 이에 대응되는 고유벡터를 구합니다. sigma를 생략하면 크기가 가장 큰 고유값이 생성됩니다. sigma가 0이면 크기가 가장 작은 고유값이 생성됩니다. 두 번째 행렬 B를 일반 고유값 문제 Aυ = λBυ에 포함할 수 있습니다.
다음 명령문은
[U,S,V] = svds(A,k)
A에서 k개의 가장 큰 특이값을 구하고, 다음 명령문은
[U,S,V] = svds(A,k,'smallest')
k개의 가장 작은 특이값을 구합니다.
eigs와 svds에 사용된 수치 기법은 [6] 항목에 설명되어 있습니다.
희소 행렬의 최소 고유값
이 예제에서는 희소 행렬의 가장 작은 고유값과 고유벡터를 구하는 방법을 보여줍니다.
L 모양의 2차원 영역에서 65×65 그리드에 5개 점의 라플라시안 차분 연산자를 설정합니다.
L = numgrid('L',65);
A = delsq(L);차수와 0이 아닌 요소의 개수를 확인합니다.
size(A)
ans = 1×2
2945 2945
nnz(A)
ans = 14473
A는 차수가 2945인 행렬로, 0이 아닌 요소를 14,473개 가지고 있습니다.
가장 작은 고유값과 고유벡터를 구합니다.
[v,d] = eigs(A,1,'smallestabs');고유벡터의 성분을 적절한 그리드 점에 분산시키고, 그 결과에 대한 등고선 플롯을 그립니다.
L(L>0) = full(v(L(L>0)));
x = -1:1/32:1;
contour(x,x,L,15)
axis square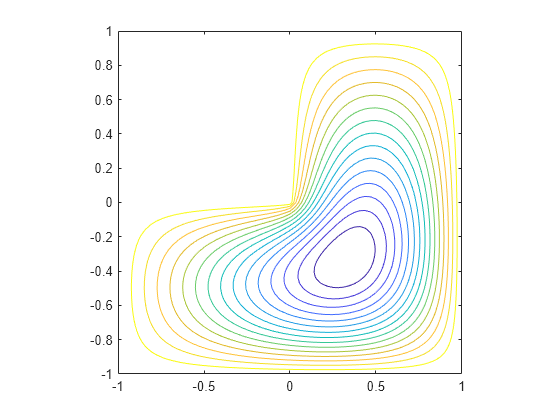
참고 문헌
[1] Amestoy, P. R., T. A. Davis, and I. S. Duff, “An Approximate Minimum Degree Ordering Algorithm,” SIAM Journal on Matrix Analysis and Applications, Vol. 17, No. 4, Oct. 1996, pp. 886-905.
[2] Barrett, R., M. Berry, T. F. Chan, et al., Templates for the Solution of Linear Systems: Building Blocks for Iterative Methods, SIAM, Philadelphia, 1994.
[3] Davis, T.A., Gilbert, J. R., Larimore, S.I., Ng, E., Peyton, B., “A Column Approximate Minimum Degree Ordering Algorithm,” Proc. SIAM Conference on Applied Linear Algebra, Oct. 1997, p. 29.
[4] Gilbert, John R., Cleve Moler, and Robert Schreiber, “Sparse Matrices in MATLAB: Design and Implementation,” SIAM J. Matrix Anal. Appl., Vol. 13, No. 1, January 1992, pp. 333-356.
[5] Larimore, S. I., An Approximate Minimum Degree Column Ordering Algorithm, MS Thesis, Dept. of Computer and Information Science and Engineering, University of Florida, Gainesville, FL, 1998.
[6] Saad, Yousef, Iterative Methods for Sparse Linear Equations. PWS Publishing Company, 1996.
[7] Karypis, George and Vipin Kumar. "A Fast and High Quality Multilevel Scheme for Partitioning Irregular Graphs." SIAM Journal on Scientific Computing. Vol. 20, Number 1, 1999, pp. 359–392.