dissect
중첩 분할 치환
설명
예제
여러 메서드를 사용하여 희소 행렬을 재정렬하고 재정렬된 행렬의 LU 분해 시 발생된 필인(Fill-in)을 비교합니다.
west0479 행렬을 불러옵니다. 이 행렬은 켤레 고유값의 실수와 복소수 쌍을 포함한 실수 값의 479×479 희소 행렬입니다. 희소성 구조를 확인합니다.
load west0479.mat
A = west0479;
spy(A)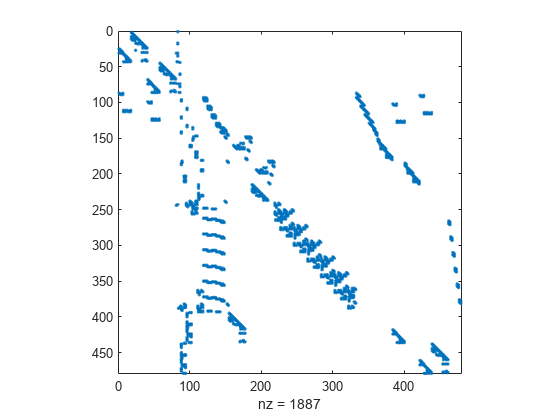
중첩 분할 정렬을 포함하여, 다양한 행렬 열의 치환을 계산합니다.
p1 = dissect(A); p2 = amd(A); p3 = symrcm(A);
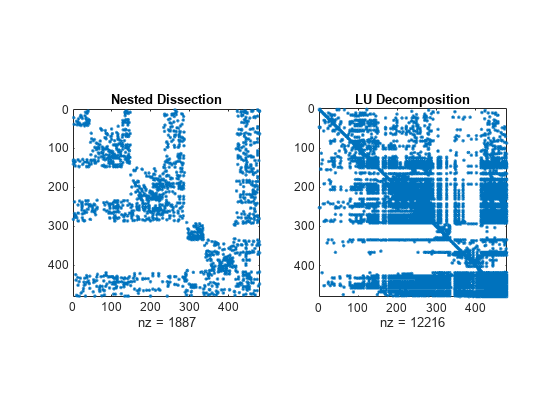
다양한 정렬 메서드를 사용하여 A의 LU 분해로 얻은 희소성 구조를 비교합니다. dissect 함수는 가장 적은 양의 필인(Fill-in)을 발생시키는 재정렬을 생성합니다.
subplot(1,2,1) spy(A) title('Original Matrix') subplot(1,2,2) spy(lu(A)) title('LU Decomposition')
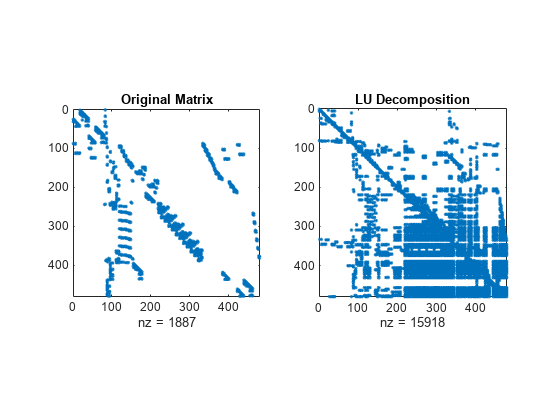
figure subplot(1,2,1) spy(A(p3,p3)) title('Reverse Cuthill-McKee') subplot(1,2,2) spy(lu(A(p3,p3))) title('LU Decomposition')
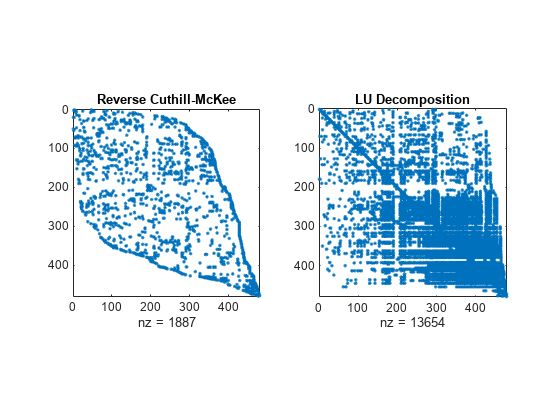
figure subplot(1,2,1) spy(A(p2,p2)) title('Approximate Minimum Degree') subplot(1,2,2) spy(lu(A(p2,p2))) title('LU Decomposition')
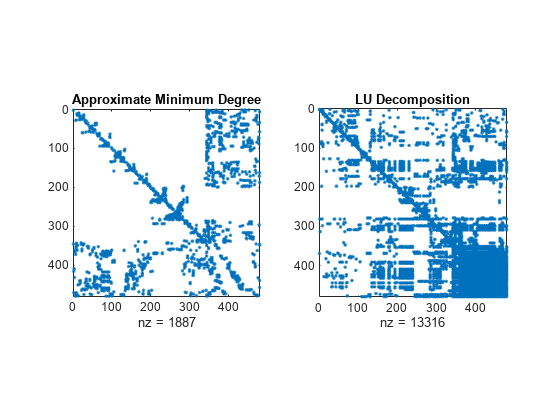
figure subplot(1,2,1) spy(A(p1,p1)) title('Nested Dissection') subplot(1,2,2) spy(lu(A(p1,p1))) title('LU Decomposition')
화살촉 행렬은 조밀한 열이 몇 개 안 되는 희소 행렬입니다. 재정렬된 행렬의 끝까지에서 조밀한 열을 필터링하려면 'MaxDegreeThreshold' 이름-값 쌍을 사용하십시오.
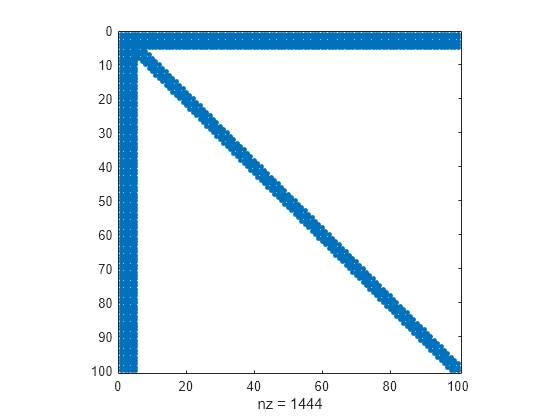
화살촉 희소 행렬을 만들고 희소성 패턴을 봅니다.
A = speye(100) + diag(ones(1,99),1) + diag(ones(1,98),2); A(1:5,:) = ones(5,100); A = A + A'; spy(A)
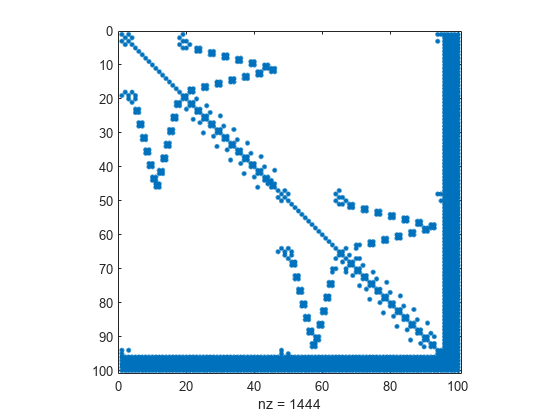
중첩 분할 정렬을 계산하고 0이 아닌 요소가 10개가 넘는 열을 필터링합니다.
p = dissect(A,'MaxDegreeThreshold',10);재정렬된 행렬의 희소성 패턴을 봅니다. dissect는 조밀한 열을 재정렬된 행렬의 끝에 배치합니다.
spy(A(p,p))
입력 인수
이름-값 인수
출력 인수
알고리즘
[1]에서 설명된 중첩 분할 정렬 알고리즘은 희소 행렬의 필인(Fill-in) 감소 정렬을 생성하는 데 사용되는 다중 수준 그래프 분할 알고리즘입니다. 입력 행렬은 그래프의 인접 행렬로 취급됩니다. 알고리즘은 정점과 모서리를 축소하여 밀도를 줄이고, 작아진 그래프를 재정렬한 다음, 미세 조정 단계를 사용하여 작은 그래프의 밀도를 되돌려 원래 그래프의 재정렬을 도출합니다.
dissect에 대한 이름-값 쌍을 통해 알고리즘의 다양한 단계를 제어할 수 있습니다.
밀도 줄이기
이 단계에서 알고리즘은 인접 정점 쌍을 함께 축소하여 원래 그래프에서 성공적으로 작은 그래프를 만듭니다.
'MaxDegreeThreshold'를 사용하여 작은 그래프를 마지막으로 정렬함으로써 밀접하게 연결된 그래프 정점(행렬에서 조밀 열)을 필터링할 수 있습니다.분할
그래프의 밀도가 감소된 후, 알고리즘은 작은 그래프를 완전히 재정렬합니다. 각 분할 단계에서 알고리즘은 그래프를 균등한 부분으로 분할하려 합니다.
'NumSeparators'는 그래프를 몇 부분으로 분할할지를 지정하고,'VertexWeights'는 선택적으로 정점에 가중치를 지정하고,'MaxImbalance'는 여러 파티션 간의 가중치 차이에 대한 임계값을 지정합니다.미세 조정
가장 작은 그래프가 재정렬된 후, 알고리즘은 투영을 통해 이전에 결합된 정점을 확장하여 그래프를 다시 원래 크기로 확대합니다. 각 투영 단계가 끝나면 미세 조정 단계가 수행되어 파티션 간에 정점을 이동하여 재정렬의 품질을 향상시킵니다.
'NumIterations'는 이 밀도 복구 단계에 사용되는 미세 조정 단계 수를 제어합니다.
참고 문헌
[1] Karypis, George and Vipin Kumar. "A Fast and High Quality Multilevel Scheme for Partitioning Irregular Graphs." SIAM Journal on Scientific Computing. Vol. 20, Number 1, 1999, pp. 359–392.
확장 기능
버전 내역
R2017b에 개발됨