svds
일부 특이값과 특이 벡터
구문
설명
s = svds(A,k,sigma,Name,Value)svds(A,k,sigma,'Tolerance',1e-3)은 알고리즘에 대한 수렴 허용오차를 조정합니다.
예제
행렬 A = delsq(numgrid('C',15))는 구간 (0 8)에 적절히 분산된 특이값을 갖는 양의 정부호 대칭 행렬입니다. 가장 큰 특이값 6개를 계산합니다.
A = delsq(numgrid('C',15));
s = svds(A)s = 6×1
7.8666
7.7324
7.6531
7.5213
7.4480
7.3517
특정 개수의 가장 큰 특이값을 계산하려면 두 번째 입력값을 지정하십시오.
s = svds(A,3)
s = 3×1
7.8666
7.7324
7.6531
행렬 A = delsq(numgrid('C',15))는 구간 (0 8)에 적절히 분산된 특이값을 갖는 양의 정부호 대칭 행렬입니다. 가장 작은 특이값 5개를 계산합니다.
A = delsq(numgrid('C',15)); s = svds(A,5,'smallest')
s = 5×1
0.5520
0.4787
0.3469
0.2676
0.1334
희소 형식의 100×100 노이만 행렬을 만듭니다.
C = gallery('neumann',100);가장 작은 특이값 10개를 계산합니다.
ss = svds(C,10,'smallest')ss = 10×1
0.9828
0.9049
0.5625
0.5625
0.4541
0.4506
0.2256
0.1139
0.1139
0
0이 아닌 가장 작은 특이값 10개를 계산합니다. 행렬에 값이 0인 특이값이 1개 있기 때문에 'smallestnz' 옵션은 이 값을 생략합니다.
snz = svds(C,10,'smallestnz')snz = 10×1
0.9828
0.9828
0.9049
0.5625
0.5625
0.4541
0.4506
0.2256
0.1139
0.1139
희소 행렬에서 오른쪽 위와 왼쪽 아래의 0이 아닌 블록을 나타내는 행렬 2개를 만듭니다.
n = 500; B = rand(500); C = rand(500);
svds와 함께 사용할 수 있도록 Afun을 현재 디렉터리에 저장합니다.
function y = Afun(x,tflag,B,C,n) if strcmp(tflag,'notransp') y = [B*x(n+1:end); C*x(1:n)]; else y = [C'*x(n+1:end); B'*x(1:n)]; end
함수 Afun은 전체 희소 행렬 A = [zeros(n) B; C zeros(n)]을 실제로 구성하지 않고 B와 C를 사용하여 A*x 또는 A'*x를 계산합니다(지정된 플래그에 따라 달라짐). 이 방법은 행렬의 희소성 패턴을 활용하기 때문에 A*x와 A'*x 계산 시 메모리를 절약할 수 있습니다.
Afun을 사용하여 A의 가장 큰 특이값 10개를 계산합니다. 추가 입력값으로 B, C, n을 Afun에 전달합니다.
s = svds(@(x,tflag) Afun(x,tflag,B,C,n),[1000 1000],10)
s = 250.3248 249.9914 12.7627 12.7232 12.6988 12.6608 12.6166 12.5643 12.5419 12.4512
직접 A의 가장 큰 특이값 10개를 계산하여 결과를 비교합니다.
A = [zeros(n) B; C zeros(n)]; s = svds(A,10)
s = 250.3248 249.9914 12.7627 12.7232 12.6988 12.6608 12.6166 12.5643 12.5419 12.4512
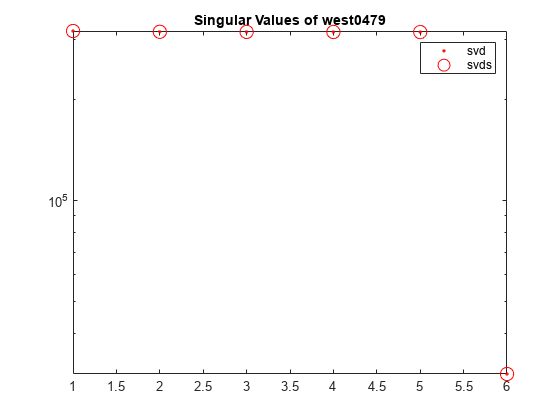
west0479는 실수 값의 479×479 희소 행렬입니다. 이 행렬에는 큰 특이값 몇 개와 작은 특이값 여러 개가 있습니다.
west0479를 불러와서 A로 저장합니다.
load west0479
A = west0479;A의 특이값 분해를 계산하면 가장 큰 특이값 6개와 대응하는 특이 벡터가 반환됩니다. 네 번째 출력 인수를 지정하여 특이값의 수렴을 확인합니다.
[U,S,V,cflag] = svds(A); cflag
cflag = 0
cflag는 모든 특이값이 수렴되었음을 나타냅니다. 특이값은 출력 행렬 S의 대각선에 있습니다.
s = diag(S)
s = 6×1
105 ×
3.1895
3.1725
3.1695
3.1685
3.1669
0.3038
A의 전체 특이값 분해를 계산하여 결과를 확인합니다. A를 비희소 행렬로 변환하고 svd를 사용합니다.
[U1,S1,V1] = svd(full(A));
svd와 svds로 계산된 A의 가장 큰 특이값 6개를 로그 스케일을 사용하여 플로팅합니다.
s2 = diag(S1); semilogy(s2(1:6),'r.') hold on semilogy(s,'ro','MarkerSize',10) title('Singular Values of west0479') legend('svd','svds')
희소 대각 행렬을 만들고 가장 큰 특이값 6개를 계산합니다.
A = diag(sparse([1e4*ones(1, 8) 1e4:-1:1])); s = svds(A)
Warning: Only 2 of the 6 requested singular values converged. Singular values that did not converge are NaN.
s = 6×1
104 ×
1.0000
0.9999
NaN
NaN
NaN
NaN
최대 반복 횟수에 도달했지만 허용오차를 충족할 수 없기 때문에 svds 알고리즘은 경고를 발생시킵니다.
수렴 문제를 해결할 수 있는 가장 효과적인 방법은 계산에 사용되는 크릴로프 부분공간의 최대 크기를 더 큰 'SubspaceDimension' 값을 사용하여 늘리는 것입니다. 이름-값 쌍 'SubspaceDimension'을 값 60으로 전달하십시오.
s = svds(A,6,'largest','SubspaceDimension',60)
s = 6×1
104 ×
1.0000
1.0000
1.0000
1.0000
1.0000
1.0000
유사 특이 행렬의 가장 작은 특이값 10개를 계산합니다.
rng default format shortg B = spdiags([repelem([1; 1e-7], [198, 2]) ones(200, 1)], [0 1], 200, 200); s1 = svds(B,10,'smallest')
Warning: Large residual norm detected. This is likely due to bad condition of the input matrix (condition number 1.0008e+16).
s1 = 10×1
7.0945
7.0945
7.0945
7.0945
7.0945
7.0945
7.0945
7.0945
0.25927
7.0888e-16
경고는 svds가 적합한 특이값 계산에 실패했음을 나타냅니다. svds가 실패한 이유는 가장 작은 특이값과 두 번째로 작은 특이값 사이의 간격 때문입니다. svds(...,'smallest')는 큰 수치 오차를 발생시키는 B의 역을 구해야 합니다.
비교를 위해 svd를 사용하여 정확한 특이값을 계산합니다.
s = svd(full(B)); s = s(end-9:end)
s = 10×1
0.14196
0.12621
0.11045
0.094686
0.078914
0.063137
0.047356
0.031572
0.015787
7.0888e-16
svds를 사용하여 이 계산을 재현하려면 B의 QR 분해를 수행하십시오. 삼각 행렬 R의 특이값은 B의 경우와 동일합니다.
[Q,R,p] = qr(B,0);
R에 있는 각 행의 노름을 플로팅합니다.
rownormR = sqrt(diag(R*R')); semilogy(rownormR) hold on; semilogy(size(R, 1), rownormR(end), 'ro')
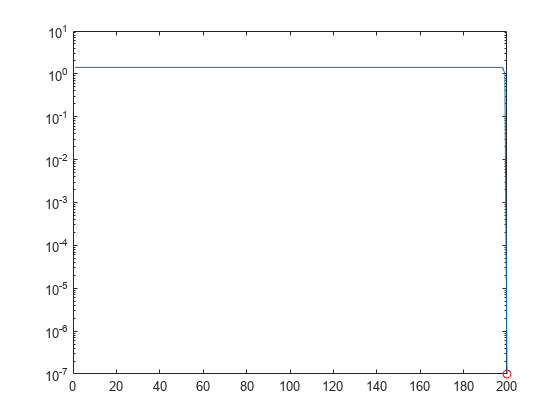
R의 마지막 요소는 거의 0에 가깝기 때문에 해가 불안정하게 됩니다.
이러한 요소가 해의 안정성을 해치지 않도록 하려면 R의 마지막 행을 정확하게 0으로 설정하십시오.
R(end,:) = 0;
svds를 사용하여 R의 가장 작은 특이값 10개를 구합니다. 해당 결과는 svd로 구한 결과와 유사합니다.
sr = svds(R,10,'smallest')sr = 10×1
0.14196
0.12621
0.11045
0.094686
0.078914
0.063137
0.047356
0.031572
0.015787
0
이 메서드를 사용하여 B의 특이 벡터를 계산하려면 Q와 치환 벡터 p를 사용하여 좌측 특이 벡터와 우측 특이 벡터를 변환하십시오.
[U,S,V] = svds(R,20,'s');
U = Q*U;
V(p,:) = V;입력 인수
이름-값 인수
출력 인수
팁
svdsketch는svds에 어떤 랭크를 지정해야 할지 미리 알지 못하지만 SVD의 근사가 충족해야 하는 허용오차는 알고 있는 경우에 유용합니다.svds는 실행 전체에 걸쳐 재현될 수 있도록 프라이빗 난수 스트림을 사용하여 디폴트 시작 벡터를 생성합니다.svds를 호출하기 전에rng를 사용하여 난수 생성기 상태를 설정해도 출력값에는 영향을 주지 않습니다.작고 조밀한 행렬의 특이값 몇 개를 구하고자 한다면
svds를 사용하는 것이 그렇게 효율적인 방법은 아닙니다. 이러한 문제에는svd(full(A))를 사용하는 편이 더 빠를 수도 있습니다. 예를 들어, 500×500 행렬에서 특이값 세 개를 구하는 것은 비교적 작은 문제이며svd를 사용하여 손쉽게 처리할 수 있습니다.svds가 주어진 행렬에 대해 수렴하지 못하면'SubspaceDimension'의 값을 증가시켜 크릴로프 부분공간 크기를 늘려 보십시오. 부차적인 옵션으로 최대 반복 횟수('MaxIterations')와 수렴 허용오차('Tolerance')를 조정해도 수렴 동작에 도움이 될 수 있습니다.특히 행렬에서 특이값이 반복되는 경우에
k를 늘리면 성능이 개선될 수도 있습니다.
참고 문헌
[1] Baglama, J. and L. Reichel, “Augmented Implicitly Restarted Lanczos Bidiagonalization Methods.” SIAM Journal on Scientific Computing. Vol. 27, 2005, pp. 19–42.
[2] Larsen, R. M. “Lanczos Bidiagonalization with partial reorthogonalization.” Dept. of Computer Science, Aarhus University. DAIMI PB-357, 1998.