colamd
열 AMD(Approximate Minimum Degree) 치환
설명
예제
희소 행렬로 구성된 하웰-보잉(Harwell-Boeing) 컬렉션과 MATLAB® demos 디렉터리에 테스트 행렬 west0479가 포함되어 있습니다. 이는 웨스터버그(Westerberg)에 제시된 8단계 화학 증류탑 모델로부터 도출된 479 차수 행렬입니다. SPY 플롯은 이 8단계가 존재함을 보여줍니다. colamd 정렬은 이 구조를 재배열합니다.
load west0479 A = west0479; p = colamd(A); figure() subplot(1,2,1), spy(A,4), title('A') subplot(1,2,2), spy(A(:,p),4), title('A(:,p)')

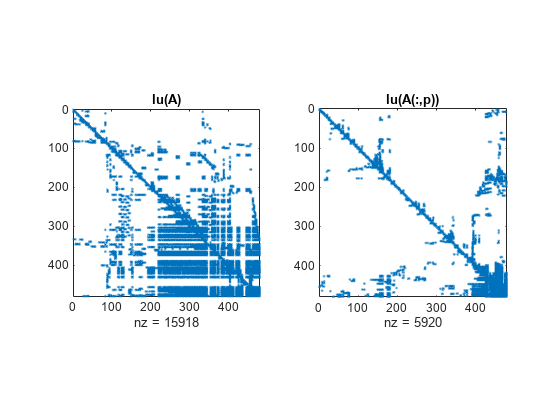
원본 행렬의 LU 분해 SPY 플롯과 다시 정렬된 행렬의 LU 분해 SPY 플롯을 비교하면 최소 차수로 인해 시간과 저장 용량에 대한 요구 사항이 원래에 비해 2.8배 넘게 줄어든다는 것을 알 수 있습니다. 0이 아닌 요소의 개수가 각각 15918과 5920입니다.
figure() subplot(1,2,1), spy(lu(A),4), title('lu(A)') subplot(1,2,2), spy(lu(A(:,p)),4), title('lu(A(:,p))')
입력 인수
출력 인수
참고 문헌
[1] Davis, Timothy A., John R. Gilbert, Stefan I. Larimore, and Esmond G. Ng. “Algorithm 836: COLAMD, a Column Approximate Minimum Degree Ordering Algorithm.” ACM Transactions on Mathematical Software 30, no. 3 (September 2004): 377–380. https://doi.org/10.1145/1024074.1024080.