eigs
고유값(Eigenvalue)과 고유벡터(Eigenvector)의 부분 집합
구문
설명
d = eigs(A,k,sigma,Name,Value)eigs(A,k,sigma,'Tolerance',1e-3)은 알고리즘에 대한 수렴 허용오차를 조정합니다.
예제
행렬 A = delsq(numgrid('C',15))는 (0 8) 구간에 적절히 분산된 고유값을 갖는 양의 정부호 대칭 행렬입니다. 가장 큰 고유값 여섯 개를 계산합니다.
A = delsq(numgrid('C',15));
d = eigs(A)d = 6×1
7.8666
7.7324
7.6531
7.5213
7.4480
7.3517
특정 개수의 가장 큰 고유값을 계산하려면 두 번째 입력값을 지정하십시오.
d = eigs(A,3)
d = 3×1
7.8666
7.7324
7.6531
행렬 A = delsq(numgrid('C',15))는 (0 8) 구간에 적절히 분산된 고유값을 갖는 양의 정부호 대칭 행렬입니다. 가장 작은 고유값 다섯 개를 계산합니다.
A = delsq(numgrid('C',15)); d = eigs(A,5,'smallestabs')
d = 5×1
0.1334
0.2676
0.3469
0.4787
0.5520
0이 아닌 요소의 밀도가 25% 정도인 희소 형식의 1500×1500 확률 행렬을 만듭니다.
n = 1500; A = sprand(n,n,0.25);
행렬의 LU 분해를 수행하여 A(p,:) = L*U를 충족하는 치환 벡터 p를 반환합니다.
[L,U,p] = lu(A,'vector');벡터 입력값 x를 받고 LU 분해의 결과를 사용하여 사실상 A\x를 반환하는 함수 핸들 Afun을 만듭니다.
Afun = @(x) U\(L\(x(p)));
eigs와 함께 함수 핸들 Afun을 사용하여 가장 작은 고유값 여섯 개를 계산합니다. 두 번째 입력값은 A의 크기입니다.
d = eigs(Afun,1500,6,'smallestabs')d = 6×1 complex
0.1423 + 0.0000i
0.4859 + 0.0000i
-0.3323 - 0.3881i
-0.3323 + 0.3881i
0.1019 - 0.5381i
0.1019 + 0.5381i
west0479는 켤레 고유값의 실수 쌍과 복소수 쌍을 모두 포함한 실수 값의 479×479 희소 행렬입니다.
west0479 행렬을 불러온 후 eig를 사용하여 모든 고유값을 계산하고 플로팅하십시오. 고유값이 복소수이므로 plot에서는 실수부를 x 좌표로, 허수부를 y 좌표로 각각 자동으로 사용합니다.
load west0479 A = west0479; d = eig(full(A)); plot(d,'+')
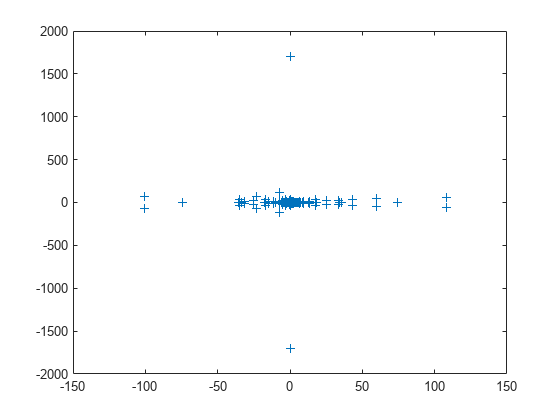
고유값은 실수 선(x축)을 따라 특히 원점 근처에 모여 있습니다.
eigs에는 각기 다른 유형의 최대 고유값이나 최소 고유값을 선택할 수 있는 sigma에 대한 여러 가지 옵션이 있습니다. sigma에서 사용할 수 있는 각각의 옵션에 대해 고유값을 계산하고 플로팅합니다.
figure plot(d, '+') hold on la = eigs(A,6,'largestabs'); plot(la,'ro') sa = eigs(A,6,'smallestabs'); plot(sa,'go') hold off legend('All eigenvalues','Largest magnitude','Smallest magnitude') xlabel('Real axis') ylabel('Imaginary axis')
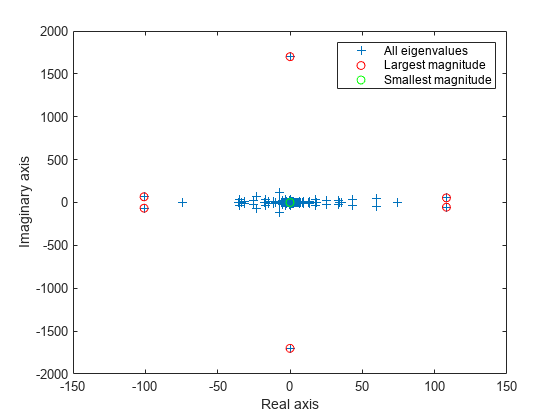
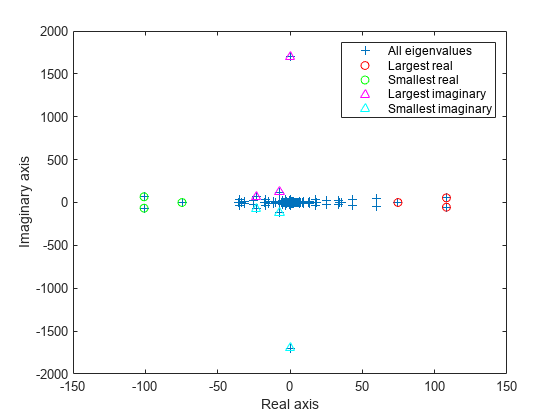
figure plot(d, '+') hold on ber = eigs(A,4,'bothendsreal'); plot(ber,'r^') bei = eigs(A,4,'bothendsimag'); plot(bei,'g^') hold off legend('All eigenvalues','Both ends real','Both ends imaginary') xlabel('Real axis') ylabel('Imaginary axis')

figure plot(d, '+') hold on lr = eigs(A,3,'largestreal'); plot(lr,'ro') sr = eigs(A,3,'smallestreal'); plot(sr,'go') li = eigs(A,3,'largestimag','SubspaceDimension',45); plot(li,'m^') si = eigs(A,3,'smallestimag','SubspaceDimension',45); plot(si,'c^') hold off legend('All eigenvalues','Largest real','Smallest real','Largest imaginary','Smallest imaginary') xlabel('Real axis') ylabel('Imaginary axis')
양의 정부호 대칭 희소 행렬을 생성합니다.
A = delsq(numgrid('C', 150));A를 이용한 크릴로프(Krylov) 방법을 차용하는 'smallestreal'로 실수부 기준으로 최소 고유값 여섯 개를 계산합니다.
tic
d = eigs(A, 6, 'smallestreal')d = 6×1
0.0013
0.0025
0.0033
0.0045
0.0052
0.0063
toc
Elapsed time is 0.897648 seconds.
A의 역행렬을 이용한 크릴로프 방법을 차용하는 'smallestabs'로 동일한 고유값을 계산합니다.
tic
dsm = eigs(A, 6, 'smallestabs')dsm = 6×1
0.0013
0.0025
0.0033
0.0045
0.0052
0.0063
toc
Elapsed time is 0.190163 seconds.
고유값은 0 근처에 모여 있습니다. 'smallestreal' 계산에서는 고유값 간 간격이 너무 작아 A를 사용하여 수렴하는 것이 쉽지 않습니다. 반대로, 'smallestabs' 옵션에서는 A의 역행렬을 사용하는데, A의 고유값의 역수는 간격이 훨씬 더 크기 때문에 계산하기가 더욱 쉽습니다. 이러한 성능 향상은 'smallestreal'에서는 불필요한 과정인 A 분해에 드는 계산 과정이 생략되기에 일어납니다.
고유값과 거의 같은 숫자형 sigma 값에 가까운 고유값을 계산합니다.
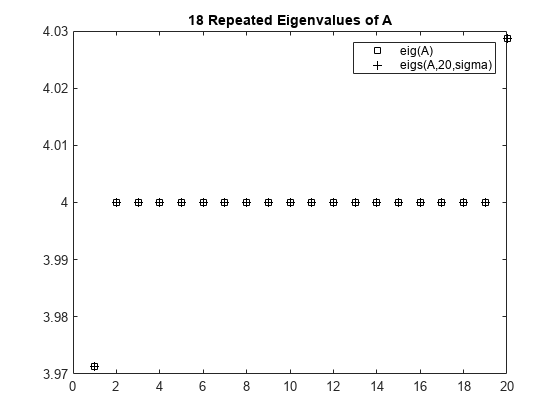
행렬 A = delsq(numgrid('C',30))은 632 크기의 양의 정부호 대칭 행렬로, (0 8) 구간에 적절히 분산된 고유값을 갖지만 18개의 고유값이 4.0에서 반복됩니다. 4.0에 가까운 고유값을 계산하려면 함수 호출 eigs(A,20,4.0)을 시도하는 것이 합리적입니다. 그러나 이 호출은 A - 4.0*I의 역행렬에서 가장 큰 고유값을 계산합니다. 여기서 I는 단위 행렬입니다. 4.0이 A의 고유값이기 때문에 이 행렬은 특이 행렬이며, 따라서 역행렬을 갖지 않습니다. eigs는 실패하고 오류 메시지를 만듭니다. sigma의 숫자형 값은 고유값과 정확히 같을 수 없습니다. 대신, 이 고유값을 구하기 위해서는 4.0에 가깝지만 4와 동일하지 않은 sigma 값을 사용해야 합니다.
먼저 eig를 사용하여 모든 고유값을 계산하고, 이후 eigs를 사용하여 4 - 1e-6에 가장 가까운 고유값 20개를 계산한 후, 두 계산 결과를 비교합니다. 각 방법으로 계산된 고유값을 플로팅합니다.
A = delsq(numgrid('C',30));
sigma = 4 - 1e-6;
d = eig(A);
D = sort(eigs(A,20,sigma));plot(d(307:326),'ks') hold on plot(D,'k+') hold off legend('eig(A)','eigs(A,20,sigma)') title('18 Repeated Eigenvalues of A')
0이 아닌 요소의 비율이 적은 희소 형식의 확률 행렬 A B를 만듭니다.
B = sprandn(1e3,1e3,0.001) + speye(1e3); B = B'*B; A = sprandn(1e3,1e3,0.005); A = A+A';
세 개의 출력값을 사용해 행렬 B의 촐레스키 분해(Cholesky Decomposition)를 수행하여 치환 벡터 s와 테스트 값 p를 반환합니다.
[R,p,s] = chol(B,'vector');
pp = 0
p가 0이므로 B는 B(s,s) = R'*R을 충족하는 양의 정부호 대칭 행렬입니다.
A와 R을 포함하는 일반 고유값 문제의 최대 고유값과 고유벡터 여섯 개를 각각 계산합니다. R이 B의 촐레스키 인수(Cholesky Factor)이므로 'IsCholesky'를 true로 지정하십시오. 또한 B(s,s) = R'*R이며, 고로 R = chol(B(s,s))이므로 치환 벡터 s를 'CholeskyPermutation'의 값으로 사용하십시오.
[V,D,flag] = eigs(A,R,6,'largestabs','IsCholesky',true,'CholeskyPermutation',s); flag
flag = 0
flag가 0이므로 모든 고유값이 수렴됩니다.
입력 인수
이름-값 인수
출력 인수
팁
eigs는 프라이빗 난수 스트림을 사용하는 디폴트 시작 벡터를 생성하여 매 실행마다 같은 결과를 재현할 수 있게 합니다.eigs를 호출하기 전에rng를 사용하여 난수 생성기 상태를 설정해도 출력값에는 영향을 주지 않습니다.작고 조밀한 행렬의 고유값 몇 개를 구하자고자 한다면
eigs를 사용하는 것이 그렇게 효율적인 방법은 아닙니다. 이러한 문제에는eig(full(A))를 사용하는 것이 더 빠를 수 있습니다. 예를 들어, 500×500 행렬에서 고유값 세 개를 구하는 것은 비교적 작은 문제이며eig를 사용하여 쉽게 처리할 수 있습니다.eigs가 어떤 행렬에 대해 수렴하지 않는 경우'SubspaceDimension'값을 늘려 Lanczos 기저 벡터의 개수를 늘려보십시오. 부차적인 옵션으로 최대 반복 횟수,'MaxIterations', 수렴 허용오차'Tolerance'를 조정하는 것도 수렴 동작에 도움이 될 수 있습니다.
참고 문헌
[1] Stewart, G.W. "A Krylov-Schur Algorithm for Large Eigenproblems." SIAM Journal of Matrix Analysis and Applications. Vol. 23, Issue 3, 2001, pp. 601–614.
[2] Lehoucq, R.B., D.C. Sorenson, and C. Yang. ARPACK Users' Guide. Philadelphia, PA: SIAM, 1998.