lu
LU 행렬 분해(Matrix Factorization)
구문
설명
전체 데이터 또는 희소 형식 데이터
예제
행렬의 LU 분해를 계산하고 결과로 출력되는 인수를 검토합니다. LU 분해는 행렬 를 가 되도록 상부 삼각 행렬 , 하부 삼각 행렬 와 치환 행렬 로 분해하는 한 가지 방법입니다. 이들 행렬은 행렬이 기약행 사다리꼴이 될 때까지 행렬에 대한 가우스 소거법을 수행하는 데 필요한 단계를 설명해 줍니다. 행렬은 모든 승수를 포함하며, 치환 행렬 는 행을 상호 교환하는 역할을 합니다.
3×3 행렬을 만들고 LU 인수를 계산합니다.
A = [10 -7 0
-3 2 6
5 -1 5];[L,U] = lu(A)
L = 3×3
1.0000 0 0
-0.3000 -0.0400 1.0000
0.5000 1.0000 0
U = 3×3
10.0000 -7.0000 0
0 2.5000 5.0000
0 0 6.2000
인수를 곱하여 A를 다시 만듭니다. 2-입력값 구문에서 lu는 반환되는 L이 실제로는 P'*L이 되도록 치환 행렬 P를 L 인수에 반영하므로 A = L*U가 됩니다.
L*U
ans = 3×3
10 -7 0
-3 2 6
5 -1 5
출력값 3개를 지정하면 L에서 승수로부터 치환 행렬을 분리할 수 있습니다.
[L,U,P] = lu(A)
L = 3×3
1.0000 0 0
0.5000 1.0000 0
-0.3000 -0.0400 1.0000
U = 3×3
10.0000 -7.0000 0
0 2.5000 5.0000
0 0 6.2000
P = 3×3
1 0 0
0 0 1
0 1 0
P'*L*U
ans = 3×3
10 -7 0
-3 2 6
5 -1 5
LU 분해를 수행하고 인수를 사용하여 문제를 단순화하여 선형 시스템을 풉니다. 이 결과를 백슬래시 연산자와 decomposition 객체를 사용하는 다른 접근 방식과 비교합니다.
5×5 마방진 행렬을 만들고 b의 모든 요소가 마방진의 합인 65와 같은 선형 시스템 를 풉니다. 이 행렬의 마방진의 합은 65이므로(모든 행과 열의 합이 65) x의 예상되는 해는 1로 구성된 벡터입니다.
A = magic(5); b = 65*ones(5,1); x = A\b
x = 5×1
1.0000
1.0000
1.0000
1.0000
1.0000
일반 정사각 행렬에서 백슬래시 연산자는 LU 분해를 사용하여 선형 시스템의 해를 구합니다. LU 분해는 A를 삼각 행렬의 곱으로 표현하므로 삼각 행렬이 있는 선형 시스템은 대입 수식을 사용하여 쉽게 풀 수 있습니다.
백슬래시로 구한 답을 다시 만들려면 A의 LU 분해를 계산하십시오. 그런 다음 인수를 사용하여 다음 2개의 선형 시스템을 푸십시오.
y = L\(P*b); x = U\y;
선형 시스템의 해를 구하기 전에 행렬 인수를 먼저 계산하는 이 접근 방식은 분해가 한 번만 발생하고 반복이 필요하지 않기 때문에 여러 개의 선형 시스템을 풀어야 할 때 성능이 높아질 수 있습니다.
[L,U,P] = lu(A)
L = 5×5
1.0000 0 0 0 0
0.7391 1.0000 0 0 0
0.4783 0.7687 1.0000 0 0
0.1739 0.2527 0.5164 1.0000 0
0.4348 0.4839 0.7231 0.9231 1.0000
U = 5×5
23.0000 5.0000 7.0000 14.0000 16.0000
0 20.3043 -4.1739 -2.3478 3.1739
0 0 24.8608 -2.8908 -1.0921
0 0 0 19.6512 18.9793
0 0 0 0 -22.2222
P = 5×5
0 1 0 0 0
1 0 0 0 0
0 0 0 0 1
0 0 1 0 0
0 0 0 1 0
y = L\(P*b); x = U\y
x = 5×1
1.0000
1.0000
1.0000
1.0000
1.0000
decomposition 객체도 행렬 인수를 먼저 계산하는 접근 방식의 성능적인 이점을 얻으면서도 인수를 어떻게 사용하는지 알 필요가 없기 때문에 역시 특화된 분해를 사용하여 선형 시스템을 풀 때 유용합니다. decomposition 객체를 'lu' 유형과 함께 사용하여 동일한 결과를 다시 만듭니다.
dA = decomposition(A,'lu');
x = dA\bx = 5×1
1.0000
1.0000
1.0000
1.0000
1.0000
희소 행렬의 LU 분해를 계산하고 항등식 L*U = P*S*Q를 검증합니다.
버크민스터 풀러의 측지선 돔의 연결 그래프에 대한 60×60 희소 인접 행렬을 생성합니다.
S = bucky;
네 개의 출력값을 가진 희소 행렬 구문을 사용하여 S의 LU 분해를 계산하고 행과 열 치환 행렬을 반환합니다.
[L,U,P,Q] = lu(S);
S의 행과 열을 P*S*Q로 치환하고 이 결과를 삼각 인수를 곱한 결과(L*U)와 비교합니다. 두 차이에 대한 1-노름이 반올림 오차 내에 있으므로, L*U = P*S*Q를 나타냅니다.
e = P*S*Q - L*U; norm(e,1)
ans = 5.7732e-15
행렬의 LU 분해를 계산합니다. 행 치환을 행렬이 아닌 벡터로 반환하여 메모리를 절약합니다.
1000×1000 확률 행렬을 만듭니다.
A = rand(1000);
행렬 P로 저장된 치환 정보를 사용하여 LU 분해를 계산합니다. 이 결과를 벡터 p로 저장된 치환 정보와 비교합니다. 행렬의 크기가 클수록 치환 벡터를 사용했을 때의 메모리 효율이 높아집니다.
[L1,U1,P] = lu(A); [L2,U2,p] = lu(A,'vector'); whos P p
Name Size Bytes Class Attributes P 1000x1000 8000000 double p 1x1000 8000 double
치환 벡터를 사용하면 이후의 연산에서의 실행 시간도 단축됩니다. 예를 들어, 앞에서 본 LU 분해를 사용하여 선형 시스템 를 구할 수 있습니다. 이때 치환 벡터로 구한 해와 치환 행렬로 구한 해는 (반올림 오차 내에서) 동일하지만 치환 벡터를 사용할 때 시간이 더 적게 걸립니다.
열 치환을 사용하여 희소 행렬의 LU 분해를 계산한 결과와 사용하지 않고 계산한 결과를 비교합니다.
실수 값의 479×479 희소 행렬인 west0479 행렬을 불러옵니다.
load west0479
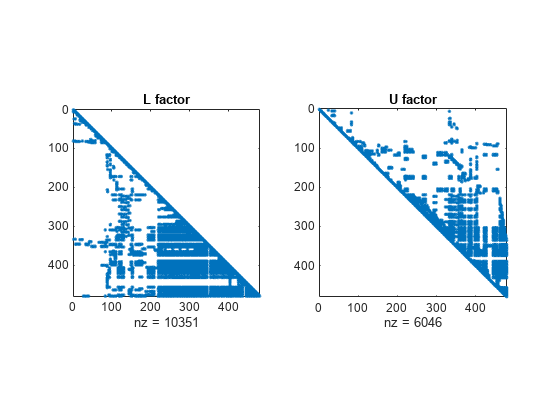
A = west0479;출력값 3개를 반환하는 lu를 호출하여 A의 LU 분해를 계산합니다. L 인수와 U 인수의 희소성 패턴을 보여주는 플롯을 생성합니다.
[L,U,P] = lu(A); subplot(1,2,1) spy(L) title('L factor') subplot(1,2,2) spy(U) title('U factor')
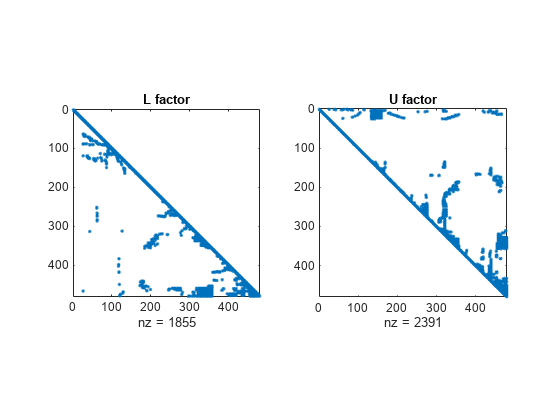
이번에는 출력값 4개를 반환하는 lu를 사용하여 A의 LU 분해를 계산합니다. 이때 lu는 A의 열을 치환하여 인수에서 0이 아닌 값의 개수를 줄입니다. 이 결과로 나오는 인수는 열 치환을 사용하지 않은 경우에 비해 희소성이 훨씬 높습니다.
[L,U,P,Q] = lu(A); subplot(1,2,1) spy(L) title('L factor') subplot(1,2,2) spy(U) title('U factor')
입력 인수
출력 인수
알고리즘
LU 분해는 가우스 소거법의 변형을 사용하여 계산됩니다. 해의 정확도는 원래 행렬의 조건수 cond(A)에 따라 달라집니다. 행렬의 조건수가 크면(즉, 유사 특이 행렬이면) 계산된 행렬 분해는 정확하지 않을 수 있습니다.
LU 분해는 inv를 사용하여 역행렬을 구하거나 det를 사용하여 행렬식을 구하는 데 있어 중요한 단계입니다. 또한 선형 방정식의 해를 구하거나 연산자 \ 및 /를 사용하여 행렬 나눗셈을 계산하는 데 있어서도 기본적인 연산입니다. 이는 lu의 수치적 제한 사항이 이러한 종속 함수에도 존재함을 의미합니다.
참고 문헌
[1] Gilbert, John R., and Tim Peierls. “Sparse Partial Pivoting in Time Proportional to Arithmetic Operations.” SIAM Journal on Scientific and Statistical Computing 9, no. 5 (September 1988): 862–874. https://doi.org/10.1137/0909058.
[2] Anderson, E., ed. LAPACK Users’ Guide. 3rd ed. Software, Environments, Tools. Philadelphia: Society for Industrial and Applied Mathematics, 1999. https://doi.org/10.1137/1.9780898719604.
[3] Davis, Timothy A. "Algorithm 832: UMFPACK V4.3 – an unsymmetric-pattern multifrontal method." ACM Transactions on Mathematical Software 30, no. 2 (June 2004): 196–199. https://doi.org/10.1145/992200.992206.