ichol
불완전 촐레스키 분해(Incomplete Cholesky Factorization)
설명
예제
이 예제에서는 불완전 촐레스키 분해(Cholesky Factorization)를 생성합니다.
양의 정부호 대칭 행렬 A로 시작합니다.
N = 100;
A = delsq(numgrid('S',N));A는 디리클레 경계 조건(Dirichlet Boundary condition)을 갖는 100×100 정사각 그리드 위의 음의 5개 점을 가진 2차원 이산 음수 라플라시안(Discrete Negative Laplacian)입니다. A의 크기는 98*98 = 9604입니다. 디리클레 조건을 도입하기 위해 그리드의 경계로 10000이 사용되지 않습니다.
채우기 없음(No-fill) 불완전 촐레스키 분해는 A가 0이 아닌 수를 포함하기 때문에 같은 위치에 0이 아닌 수만 포함하는 행렬 분해입니다. 이 행렬 분해는 리소스를 매우 적게 사용하여 계산이 가능합니다. 일반적으로 결과 L*L'은 A와는 매우 다르지만, 결과 L*L'은 반올림까지 패턴에서 A와 일치합니다.
L = ichol(A); norm(A-L*L','fro')./norm(A,'fro')
ans = 0.0916
norm(A-(L*L').*spones(A),'fro')./norm(A,'fro')
ans = 4.9606e-17
ichol은 임계값 기각을 사용한 불완전 촐레스키 분해의 생성에도 사용될 수 있습니다. 기각 허용오차가 감소할수록 인수는 더 조밀해지고 결과 L*L'은 A에 대한 더 나은 근삿값이 되는 경향이 있습니다. 기각 허용오차에 대한 다음 플롯들은 불완전 행렬 분해의 상대 오차뿐 아니라 완전 촐레스키 인수(Cholesky Factor)의 밀도에 대한 불완전 인수의 밀도의 비율도 플로팅해 보여줍니다.
n = size(A,1); ntols = 20; droptol = logspace(-8,0,ntols); nrm = zeros(1,ntols); nz = zeros(1,ntols); nzComplete = nnz(chol(A,'lower')); for k = 1:ntols L = ichol(A,struct('type','ict','droptol',droptol(k))); nz(k) = nnz(L); nrm(k) = norm(A-L*L','fro')./norm(A,'fro'); end figure loglog(droptol,nrm,'LineWidth',2) title('Drop tolerance vs norm(A-L*L'',''fro'')./norm(A,''fro'')')
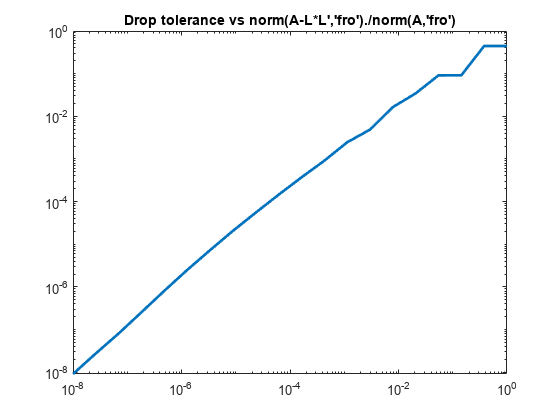
figure semilogx(droptol,nz./nzComplete,'LineWidth',2) title('Drop tolerance vs fill ratio ichol/chol')
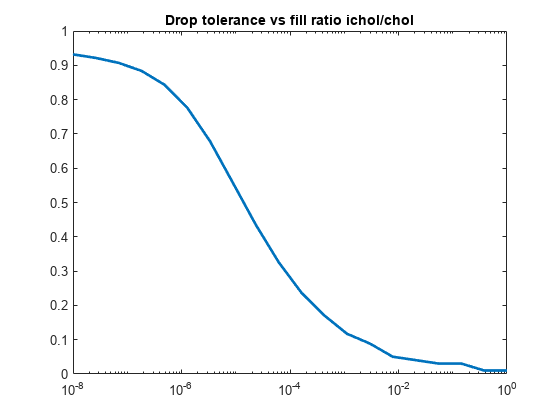
일반적으로 상대 오차는 기각 허용오차와 동일한 차수이지만 항상 동일한 것은 아닙니다.
이 예제에서는 수렴을 개선하기 위해 불완전 촐레스키 분해(Cholesky Factorization)를 선조건자(Preconditioner)로 사용하는 방법을 보여줍니다.
양의 정부호 대칭 행렬 A를 생성합니다.
N = 100;
A = delsq(numgrid('S',N));pcg에 대한 선조건자로 불완전 촐레스키 분해를 생성합니다. 상수 벡터를 우변으로 사용합니다. 기준으로 선조건자 없이 pcg를 실행합니다.
b = ones(size(A,1),1); tol = 1e-6; maxit = 100; [x0,fl0,rr0,it0,rv0] = pcg(A,b,tol,maxit);
참고로, fl0 = 1은 pcg가 상대 잔차를 최대 허용 반복으로 요청된 허용오차까지 가져가지 않았음을 나타냅니다. 채우기 없음(No-fill) 불완전 촐레스키 분해(Cholesky Factorization)를 선조건자(Preconditioner)로 시도합니다.
L1 = ichol(A); [x1,fl1,rr1,it1,rv1] = pcg(A,b,tol,maxit,L1,L1');
fl1 = 0은 pcg가 요청된 허용오차로 수렴되었고 이것이 59회의 반복에서 이루어졌음을 나타냅니다(it1의 값). 하지만 이 행렬은 이산 라플라시안(Discrete Laplacian)이기 때문에 수정된 불완전 촐레스키 분해(Cholesky Factorization)를 사용하면 더 나은 선조건자(Preconditioner)를 생성할 수 있습니다. 수정된 불완전 촐레스키 분해(Cholesky Factorization)는 상수 벡터에 대한 연산자의 동작을 보존하는 근사 분해를 생성합니다. 즉, norm(A-L*L','fro')/norm(A,'fro')가 0에 가깝지 않더라도 e = ones(size(A,2),1)에 대해 norm(A*e-L*(L'*e))는 0에 근사합니다. nofill이 디폴트이기 때문에 이 구문에 대해 유형을 지정할 필요는 없지만, 연습해 보기 위해 지정합니다.
options.type = 'nofill'; options.michol = 'on'; L2 = ichol(A,options); e = ones(size(A,2),1); norm(A*e-L2*(L2'*e))
ans = 3.7983e-14
[x2,fl2,rr2,it2,rv2] = pcg(A,b,tol,maxit,L2,L2');
pcg는 단 38회 반복에서 수렴됩니다(fl2 = 0). 세 수렴 기록을 플로팅하면 수렴이 표시됩니다.
semilogy(0:maxit,rv0./norm(b),'b.'); hold on semilogy(0:it1,rv1./norm(b),'r.'); semilogy(0:it2,rv2./norm(b),'k.'); legend('No Preconditioner','IC(0)','MIC(0)');
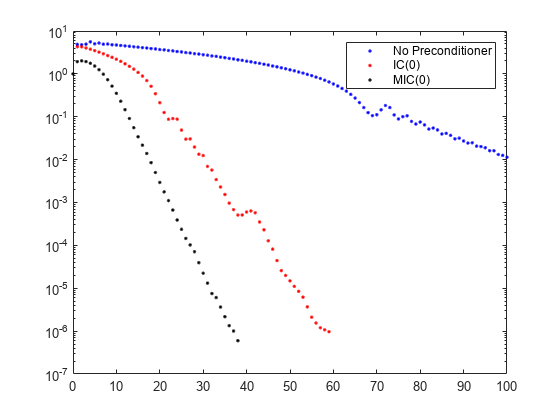
플롯은 수정된 불완전 촐레스키 선조건자(Cholesky Preconditioner)가 훨씬 더 빠른 수렴을 생성한다는 것을 보여줍니다.
또한 임계값 기각을 사용한 불완전 촐레스키 분해를 시도할 수 있습니다. 다음 플롯은 다양한 기각 허용오차로 생성된 선조건자를 사용하여 pcg의 수렴을 보여줍니다.
L3 = ichol(A, struct('type','ict','droptol',1e-1)); [x3,fl3,rr3,it3,rv3] = pcg(A,b,tol,maxit,L3,L3'); L4 = ichol(A, struct('type','ict','droptol',1e-2)); [x4,fl4,rr4,it4,rv4] = pcg(A,b,tol,maxit,L4,L4'); L5 = ichol(A, struct('type','ict','droptol',1e-3)); [x5,fl5,rr5,it5,rv5] = pcg(A,b,tol,maxit,L5,L5'); figure semilogy(0:maxit,rv0./norm(b),'b-','linewidth',2); hold on semilogy(0:it3,rv3./norm(b),'b-.','linewidth',2); semilogy(0:it4,rv4./norm(b),'b--','linewidth',2); semilogy(0:it5,rv5./norm(b),'b:','linewidth',2); legend('No Preconditioner','ICT(1e-1)','ICT(1e-2)', ... 'ICT(1e-3)','Location','SouthEast');

참고로, 기각 허용오차 1e-2로 생성된 불완전 촐레스키 선조건자는 ICT(1e-2)로 나타납니다.
0 채우기 불완전 촐레스키 분해의 경우와 같이 임계값 기각 분해는 수정(즉, options.michol = 'on')의 이점을 가집니다. 이는 행렬이 타원형 편미분 방정식에서 발생하기 때문입니다. MIC(0)의 경우와 같이 수정된 임계값 기반 기각 불완전 촐레스키 분해는 상수 벡터에 대한 선조건자의 동작을 유지합니다. 즉, norm(A*e-L*(L'*e))는 약 0이 됩니다.
이 예제에서는 ichol에 diagcomp 옵션을 사용하는 예를 보여줍니다.
양의 정부호 행렬의 불완전 촐레스키 분해(Cholesky Factorization)가 항상 존재하는 것은 아닙니다. 다음 코드는 임의의 양의 정부호 대칭 행렬을 생성하고 pcg를 사용하여 선형 시스템의 해를 구하려고 시도합니다.
S = rng('default');
A = sprandsym(1000,1e-2,1e-4,1);
rng(S);
b = full(sum(A,2));
[x0,fl0,rr0,it0,rv0] = pcg(A,b,1e-6,100);수렴되지 않으므로 불완전 촐레스키 선조건자(Cholesky Preconditioner)를 생성해 봅니다.
L = ichol(A,struct('type','ict','droptol',1e-3));
Error using ichol Encountered nonpositive pivot.
ichol이 위와 같이 오류를 반환하는 경우, diagcomp 옵션을 사용하여 이동된 불완전 촐레스키 분해를 생성할 수 있습니다. L*L'이 A에 근사하도록 L을 생성하는 대신 대각선 보정 ichol은 명시적으로 M을 구성하지 않고 L*L'이 M = A + alpha*diag(diag(A))에 근사하도록 L을 생성합니다. 대각선 우위 행렬에 대해 불완전 행렬 분해가 항상 존재하므로, M을 대각선 우위로 만드는 alpha를 찾을 수 있습니다.
alpha = max(sum(abs(A),2)./diag(A))-2
alpha = 62.9341
L1 = ichol(A, struct('type','ict','droptol',1e-3,'diagcomp',alpha)); [x1,fl1,rr1,it1,rv1] = pcg(A,b,1e-6,100,L1,L1');
여기서 pcg는 원하는 반복 횟수 내에서 기대한 허용오차로 수렴하는 데 여전히 실패하지만, 아래의 플롯이 보여주는 바와 같이 선조건자가 없는 것보다 있는 것이 pcg의 수렴에 더 낫습니다. 더 작은 alpha 값을 선택하는 것이 도움이 될 수 있습니다. 몇 번의 시도로, alpha에 대한 적절한 값을 결정할 수 있습니다.
alpha = .1; L2 = ichol(A, struct('type','ict','droptol',1e-3,'diagcomp',alpha)); [x2,fl2,rr2,it2,rv2] = pcg(A,b,1e-6,100,L2,L2');
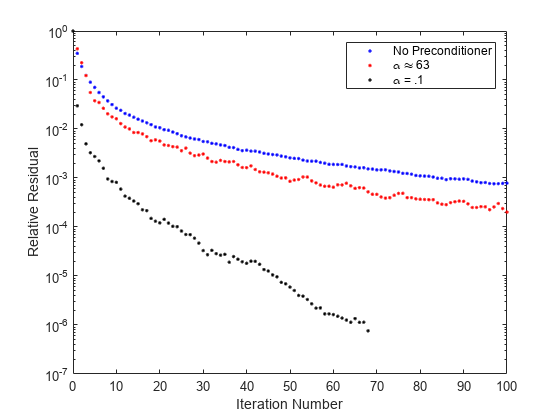
이제 pcg는 수렴하며, 플롯은 각 선조건자와 함께 수렴 기록을 표시할 수 있습니다.
semilogy(0:100,rv0./norm(b),'b.'); hold on; semilogy(0:100,rv1./norm(b),'r.'); semilogy(0:it2,rv2./norm(b),'k.'); legend('No Preconditioner','\alpha \approx 63','\alpha = .1'); xlabel('Iteration Number'); ylabel('Relative Residual');
입력 인수
팁
참고 문헌
[1] Saad, Yousef. “Preconditioning Techniques.” Iterative Methods for Sparse Linear Systems. PWS Publishing Company, 1996.
[2] Manteuffel, T.A. “An incomplete factorization technique for positive definite linear systems.” Math. Comput. 34, 473–497, 1980.