kruskalwallis
크루스칼-왈리스 검정
구문
설명
p = kruskalwallis(x)x의 각 열에 있는 데이터가 동일한 분포에서 나온다는 귀무가설에 대해 크루스칼-왈리스 검정을 사용하여 p-값을 반환합니다. 대립가설은 모든 표본이 동일한 분포에서 나오지는 않는다는 것입니다. 크루스칼-왈리스 검정은 일원분산분석에 대한 비모수적 대안을 제공합니다. 자세한 내용은 크루스칼-왈리스 검정 항목을 참조하십시오.
p = kruskalwallis(x,group,displayopt)
예제
두 개의 서로 다른 정규 확률 분포 객체를 생성합니다. 첫 번째 분포는 mu = 0 및 sigma = 1이고, 두 번째 분포는 mu = 2 및 sigma = 1입니다.
pd1 = makedist('Normal'); pd2 = makedist('Normal','mu',2,'sigma',1);
이러한 두 개의 분포에서 난수를 생성하여 표본 데이터에 대한 행렬을 만듭니다.
rng('default'); % for reproducibility x = [random(pd1,20,2),random(pd2,20,1)];
x의 처음 두 열에는 첫 번째 분포에서 생성된 데이터가 있고, 세 번째 열에는 두 번째 분포에서 생성된 데이터가 있습니다.
x의 각 열에 있는 표본 데이터가 동일한 분포에서 나왔다는 귀무가설을 검정합니다.
p = kruskalwallis(x)

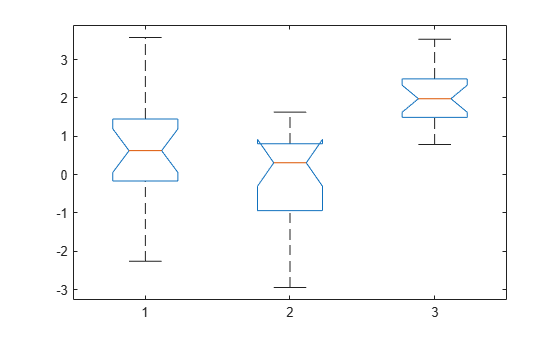
p = 3.6896e-06
반환된 값 p는 kruskalwallis가 1% 유의수준에서 모든 세 가지 데이터 표본이 동일한 분포에서 나온다는 귀무가설을 기각함을 나타냅니다. 분산분석표는 추가적인 검정 결과를 제공하고, 상자 플롯은 x의 각 열에 대한 요약 통계량을 시각적으로 보여줍니다.
두 개의 서로 다른 정규 확률 분포 객체를 생성합니다. 첫 번째 분포는 mu = 0 및 sigma = 1을 갖습니다. 두 번째 분포는 mu = 2 및 sigma = 1을 갖습니다.
pd1 = makedist('Normal'); pd2 = makedist('Normal','mu',2,'sigma',1);
이러한 두 개의 분포에서 난수를 생성하여 표본 데이터에 대한 행렬을 만듭니다.
rng('default'); % for reproducibility x = [random(pd1,20,2),random(pd2,20,1)];
x의 처음 두 열에는 첫 번째 분포에서 생성된 데이터가 있고, 세 번째 열에는 두 번째 분포에서 생성된 데이터가 있습니다.
x의 각 열에 있는 표본 데이터가 동일한 분포에서 나왔다는 귀무가설을 검정합니다. 출력값 표시를 차단하고 추가 검정에 사용할 구조체 stats를 생성합니다.
[p,tbl,stats] = kruskalwallis(x,[],'off')p = 3.6896e-06
tbl=4×6 cell array
{'Source' } {'SS' } {'df'} {'MS' } {'Chi-sq' } {'Prob>Chi-sq'}
{'Columns'} {[7.6311e+03]} {[ 2]} {[3.8155e+03]} {[ 25.0200]} {[ 3.6896e-06]}
{'Error' } {[1.0364e+04]} {[57]} {[ 181.8228]} {0×0 double} {0×0 double }
{'Total' } {[ 17995]} {[59]} {0×0 double } {0×0 double} {0×0 double }
stats = struct with fields:
gnames: [3×1 char]
n: [20 20 20]
source: 'kruskalwallis'
meanranks: [26.7500 18.9500 45.8000]
sumt: 0
반환된 값 p는 검정이 1% 유의수준에서 귀무가설을 기각함을 나타냅니다. 구조체 stats를 사용하여 추가 후속 검정을 수행할 수도 있습니다. 셀형 배열 tbl에는 그래픽 분산분석표와 동일한 데이터가 포함되어 있습니다(열과 행 레이블 포함).
다른 분포에서 나온 데이터 표본이 어느 표본인지를 식별하기 위해 후속 검정을 수행합니다.
c = multcompare(stats);
Note: Intervals can be used for testing but are not simultaneous confidence intervals.
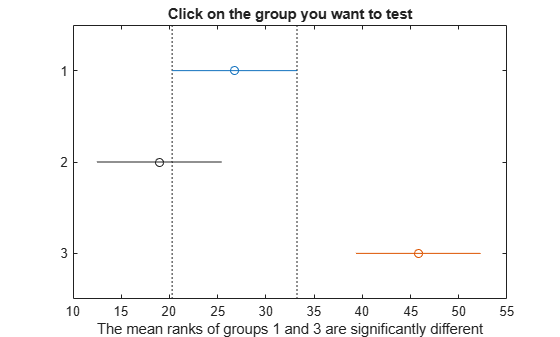
여러 개의 비교 결과를 테이블로 표시합니다.
tbl = array2table(c,"VariableNames", ... ["Group A","Group B","Lower Limit","A-B","Upper Limit","P-value"])
tbl=3×6 table
Group A Group B Lower Limit A-B Upper Limit P-value
_______ _______ ___________ ______ ___________ __________
1 2 -5.1435 7.8 20.744 0.33446
1 3 -31.994 -19.05 -6.1065 0.0016282
2 3 -39.794 -26.85 -13.906 3.4768e-06
결과는 그룹 1과 3 사이에 유의미한 차이가 있음을 나타내므로, 이 검정은 두 그룹의 데이터가 동일한 분포에서 나왔다는 귀무가설을 기각합니다. 그룹 2와 3에서도 마찬가지입니다. 그러나 그룹 1과 2 사이에 유의미한 차이가 없으므로, 이 검정은 두 그룹이 동일한 분포에서 나왔다는 귀무가설을 기각하지 않습니다. 따라서 이러한 결과는 그룹 1과 2의 데이터는 동일한 분포에서 나왔고, 그룹 3의 데이터는 다른 분포에서 나왔다는 것을 의미합니다.
금속 빔 강도의 측정값을 포함하는 벡터 strength를 생성합니다. 해당 빔이 만들어진 금속 합금의 유형을 나타내는 두 번째 벡터 alloy를 만듭니다.
strength = [82 86 79 83 84 85 86 87 74 82 ... 78 75 76 77 79 79 77 78 82 79]; alloy = {'st','st','st','st','st','st','st','st',... 'al1','al1','al1','al1','al1','al1',... 'al2','al2','al2','al2','al2','al2'};
세 가지 합금 모두에서 빔 강도 측정값이 동일한 분포를 갖는다는 귀무가설을 검정합니다.
p = kruskalwallis(strength,alloy,'off')p = 0.0018
반환된 값 p는 검정이 1% 유의수준에서 귀무가설을 기각함을 나타냅니다.
입력 인수
출력 인수
세부 정보
버전 내역
R2006a 이전에 개발됨