이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
linkage
계층적 병합 군집 트리
구문
설명
예제
20,000개의 관측값을 갖는 표본 데이터를 임의로 생성합니다.
rng(0,"twister") % For reproducibility X = rand(20000,3);
ward 연결 방법을 사용하여 계층적 군집 트리를 생성합니다. 이 경우, clusterdata 함수의 SaveMemory 옵션은 기본적으로 "on"으로 설정됩니다. 일반적으로, X의 차원과 사용 가능한 메모리를 기준으로 SaveMemory에 가장 적합한 값을 지정합니다.
Z = linkage(X,"ward");데이터를 최대 네 개의 그룹으로 군집화하고 결과를 플로팅합니다.
c = cluster(Z,MaxClust=4); scatter3(X(:,1),X(:,2),X(:,3),10,c)
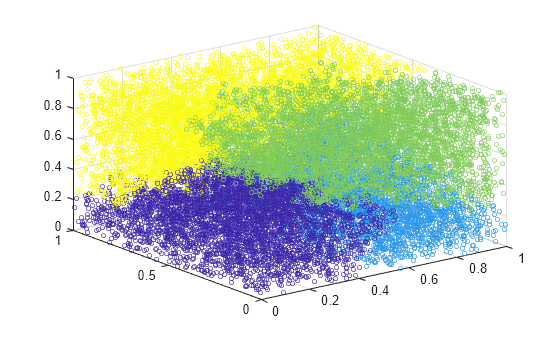
cluster는 데이터에서 네 개의 그룹을 식별합니다.
fisheriris 데이터 세트에서 최대 세 개의 군집을 찾고 꽃의 군집 할당을 알려진 분류와 비교합니다.
표본 데이터를 불러옵니다.
load fisheriris"average" 방법과 "chebychev" 측정법을 사용하여 계층적 군집 트리를 생성합니다.
Z = linkage(meas,"average","chebychev");
데이터에서 최대 세 개의 군집을 찾습니다.
T = cluster(Z,MaxClust=3);
Z에 대한 덴드로그램 플롯을 생성합니다. 3개의 군집을 표시하기 위해 마지막에서 세 번째 연결과 마지막에서 두 번째 연결 간의 중간 절단을 ColorThreshold로 사용합니다.
cutoff = median([Z(end-2,3) Z(end-1,3)]); dendrogram(Z,ColorThreshold=cutoff,ShowCut=true)

Z의 마지막 두 행을 표시하여 세 개의 군집이 어떻게 하나로 결합되었는지를 확인합니다. linkage는 연결 값으로 1.7583을 사용하여 293번째(주황색) 군집을 297번째(파란색) 군집과 결합하여 298번째 군집을 형성합니다. 그런 다음 linkage는 296번째(빨간색) 군집과 298번째 군집을 결합합니다.
lastTwo = Z(end-1:end,:)
lastTwo = 2×3
293.0000 297.0000 1.7583
296.0000 298.0000 3.4445
군집 할당은 세 가지 종에 대응됩니다. 예를 들면, 군집 중 하나에 두 번째 종의 꽃은 50송이, 세 번째 종의 꽃은 40송이가 포함되어 있습니다.
crosstab(T,species)
ans = 3×3
0 0 10
0 50 40
50 0 0
examgrades 데이터 세트를 불러옵니다.
load examgradeslinkage를 사용하여 계층적 트리를 생성합니다. 'single' 방법과, 지수를 3으로 하여 민코프스키(Minkowski) 측정법을 사용합니다.
Z = linkage(grades,'single',{'minkowski',3});
25번째 군집화 스텝을 관측합니다.
Z(25,:)
ans = 1×3
86.0000 137.0000 4.5307
linkage는 86번째 관측값과 137번째 군집을 결합하여 인덱스가 인 군집을 구성합니다. 여기서 120은 grades에 포함된 총 관측값 개수이고, 25는 Z의 행 번호입니다. 86번째 관측값과 137번째 군집에 포함된 모든 점 간의 최단 거리는 4.5307입니다.
비유사성 행렬을 사용하여 계층적 병합 군집 트리를 생성합니다.
비유사성 행렬 X를 지정한 다음 squareform을 사용하여 linkage가 받는 벡터 형식으로 변환합니다.
X = [0 1 2 3; 1 0 4 5; 2 4 0 6; 3 5 6 0]; y = squareform(X);
'complete'을 두 군집 간 거리 계산 방법으로 지정하고 linkage를 사용하여 군집 트리를 생성합니다. Z의 처음 두 열은 linkage가 군집을 어떻게 결합하는지를 보여줍니다. Z의 세 번째 열은 군집 간 거리를 제공합니다.
Z = linkage(y,'complete')Z = 3×3
1 2 1
3 5 4
4 6 6
Z에 대한 덴드로그램 플롯을 생성합니다. x축은 트리의 리프 노드에 대응되고, y축은 군집 간의 연결 거리에 대응됩니다.
dendrogram(Z)
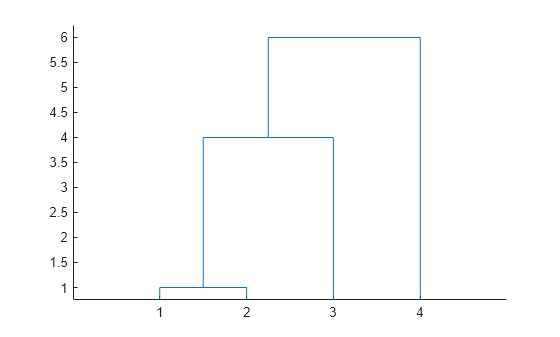
입력 인수
출력 인수
세부 정보
팁
y가 거리 행렬의 벡터 표현인 경우linkage(y)계산이 느려질 수 있습니다.'centroid','median','ward'방법에 대해linkage는y가 유클리드 거리인지 여부를 확인합니다.y대신X를 전달하여 시간이 많이 걸리는 이 확인 작업을 피할 수 있습니다.'centroid'방법과'median'방법은 단조적(Monotonic)이지 않은 군집 트리를 생성할 수 있습니다. 이 결과는 두 군집 r과 s의 합집합에서 세 번째 군집까지의 거리가 r과 s 간의 거리보다 작을 경우에 발생합니다. 이 경우, 디폴트 방향으로 그린 덴드로그램에서 리프로부터 루트 노드까지의 경로는 아래쪽 방향의 일부 단계를 지나게 됩니다. 이 결과를 방지하려면 다른 방법을 사용하십시오. 다음 Figure는 비단조적 군집 트리를 보여줍니다.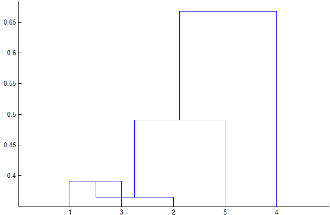
이 경우, 군집 1과 군집 3이 새 군집으로 결합되며, 이 새 군집과 군집 2 간의 거리는 군집 1과 군집 3 간의 거리보다 작습니다. 그 결과 비단조적 트리가 생성됩니다.
트리를 표시하기 위한
dendrogram, 점을 군집에 할당하기 위한cluster, 일치하지 않는 측정값을 계산하기 위한inconsistent, 코페네틱 상관 계수(Cophenetic Correlation Coefficient)를 계산하기 위한cophenet를 비롯한 다른 함수에 출력값Z를 제공할 수 있습니다.
버전 내역
R2006a 이전에 개발됨
참고 항목
cluster | clusterdata | cophenet | dendrogram | inconsistent | kmeans | pdist | silhouette | squareform