이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
kmeans
k-평균 군집화
구문
설명
idx = kmeans(X,k)X의 관측값을 k개 군집으로 분할한 후 각 관측값의 군집 인덱스를 포함하는 n×1 벡터(idx)를 반환합니다. X의 행은 점에 대응되고, 열은 변수에 대응됩니다.
기본적으로, kmeans는 군집 중심 초기화에 제곱 유클리드 거리 측정법과 k-평균++ 알고리즘을 사용합니다.
idx = kmeans(X,k,Name,Value)Name,Value 쌍 인수로 지정된 추가 옵션을 사용하여 군집 인덱스를 반환합니다.
예를 들어, 코사인 거리, 새 초기값을 사용하여 군집화를 반복할 횟수 또는 병렬 연산 사용 여부를 지정합니다.
예제
k-평균 군집화를 사용하여 데이터를 군집화한 후 군집 영역을 플로팅합니다.
피셔(Fisher)의 붓꽃 데이터 세트를 불러옵니다. 꽃잎 길이와 너비를 예측 변수로 사용합니다.
load fisheriris X = meas(:,3:4); figure; plot(X(:,1),X(:,2),'k*','MarkerSize',5); title 'Fisher''s Iris Data'; xlabel 'Petal Lengths (cm)'; ylabel 'Petal Widths (cm)';

큰 쪽 군집은 낮은 분산 영역과 높은 분산 영역으로 분할되는 것처럼 보입니다. 이는 큰 쪽 군집이 2개의 겹치는 군집임을 뜻할 수 있습니다.
데이터를 군집화합니다. k = 3으로 군집 개수를 지정합니다.
rng(1); % For reproducibility
[idx,C] = kmeans(X,3);idx는 X에 포함된 관측값에 대응되는 예측된 군집 인덱스로 구성된 벡터입니다. C는 최종 중심 위치를 포함하는 3×2 행렬입니다.
kmeans를 사용하여 각 중심에서 그리드의 점까지의 거리를 계산합니다. 이렇게 하려면 중심(C)과 그리드의 점을 kmeans에 전달하고 알고리즘의 1회 반복을 구현합니다.
x1 = min(X(:,1)):0.01:max(X(:,1)); x2 = min(X(:,2)):0.01:max(X(:,2)); [x1G,x2G] = meshgrid(x1,x2); XGrid = [x1G(:),x2G(:)]; % Defines a fine grid on the plot idx2Region = kmeans(XGrid,3,'MaxIter',1,'Start',C);
Warning: Failed to converge in 1 iterations.
% Assigns each node in the grid to the closest centroidkmeans가 알고리즘이 수렴되지 않았음을 나타내는 경고를 표시합니다. 이는 소프트웨어가 1회 반복만 구현했기 때문에 예상되는 동작입니다.
군집 영역을 플로팅합니다.
figure; gscatter(XGrid(:,1),XGrid(:,2),idx2Region,... [0,0.75,0.75;0.75,0,0.75;0.75,0.75,0],'..'); hold on; plot(X(:,1),X(:,2),'k*','MarkerSize',5); title 'Fisher''s Iris Data'; xlabel 'Petal Lengths (cm)'; ylabel 'Petal Widths (cm)'; legend('Region 1','Region 2','Region 3','Data','Location','SouthEast'); hold off;

표본 데이터를 무작위로 생성합니다.
rng default; % For reproducibility X = [randn(100,2)*0.75+ones(100,2); randn(100,2)*0.5-ones(100,2)]; figure; plot(X(:,1),X(:,2),'.'); title 'Randomly Generated Data';

데이터에 두 개의 군집이 있는 것처럼 보입니다.
데이터를 두 개 군집으로 분할하고 5개 초기화 중에서 최적의 배열을 선택합니다. 최종 출력값을 표시합니다.
opts = statset('Display','final'); [idx,C] = kmeans(X,2,'Distance','cityblock',... 'Replicates',5,'Options',opts);
Replicate 1, 3 iterations, total sum of distances = 0.9879171.79822.012450.8117850.42111.476630.935910.7658763.92211.979431.424072.662641.514380.8970231.211160.4900031.413872.344710.9618081.725542.639011.767771.526541.773070.474890.737131.323370.48160.7009451.910930.6884431.523612.030061.231352.433221.058281.000911.655061.244741.553550.3370910.4231971.308820.2056411.31780.8025581.036580.6277072.078681.509511.281030.1702011.127751.479361.012391.006141.158761.246460.3833821.036551.082730.6571421.011252.674342.354170.4094451.978721.251440.9742022.310791.506322.065221.276750.8709761.110391.63371.212310.4582970.5357611.03681.842510.5143450.5416491.19871.261181.256171.22131.371520.6112451.066731.0530.1301640.525781.910790.7818770.722291.450342.043190.5321252.058140.1718340.948870.720610.5322740.5367080.5896830.3956460.534580.5077240.3546260.728470.8935010.4712120.7593141.377580.7991450.6911630.2880741.129630.5508960.9993251.023740.7261060.2204910.9175090.4357990.5026970.2129291.156380.8346460.4969721.187010.5606991.044620.2570.4003661.135382.097341.43670.8821421.192170.5808720.2976160.401890.214231.58420.2424841.005980.4217950.1035350.8210810.1905330.4947271.102361.129220.3802381.103781.424281.211780.6076250.7203680.8542731.048020.5291860.6439461.002930.3392271.094660.1616450.3560030.8847070.6776620.9006650.332320.3368890.8842620.7647690.6776980.9044340.5589671.708050.8172460.3194670.8796910.9693671.099070.8290530.732971.020470.979410.2533961.089880.7817340.9302050.4414340.1001132.052320.634641.114861.52274. Replicate 2, 5 iterations, total sum of distances = 0.9879171.79822.012450.8117850.42111.476630.935910.7658763.92211.979431.424072.662641.514380.8970231.211160.4900031.413872.344710.9618081.725542.639011.767771.526541.773070.474890.737131.323370.48160.7009451.910930.6884431.523612.030061.231352.433221.058281.000911.655061.244741.553550.3370910.4231971.308820.2056411.31780.8025581.036580.6277072.078681.509511.281030.1702011.127751.479361.012391.006141.158761.246460.3833821.036551.082730.6571421.011252.674342.354170.4094451.978721.251440.9742022.310791.506322.065221.276750.8709761.110391.63371.212310.4582970.5357611.03681.842510.5143450.5416491.19871.261181.256171.22131.371520.6112451.066731.0530.1301640.525781.910790.7818770.722291.450342.043190.5321252.058140.1718340.948870.720610.5322740.5367080.5896830.3956460.534580.5077240.3546260.728470.8935010.4712120.7593141.377580.7991450.6911630.2880741.129630.5508960.9993251.023740.7261060.2204910.9175090.4357990.5026970.2129291.156380.8346460.4969721.187010.5606991.044620.2570.4003661.135382.097341.43670.8821421.192170.5808720.2976160.401890.214231.58420.2424841.005980.4217950.1035350.8210810.1905330.4947271.102361.129220.3802381.103781.424281.211780.6076250.7203680.8542731.048020.5291860.6439461.002930.3392271.094660.1616450.3560030.8847070.6776620.9006650.332320.3368890.8842620.7647690.6776980.9044340.5589671.708050.8172460.3194670.8796910.9693671.099070.8290530.732971.020470.979410.2533961.089880.7817340.9302050.4414340.1001132.052320.634641.114861.52274. Replicate 3, 3 iterations, total sum of distances = 0.9879171.79822.012450.8117850.42111.476630.935910.7658763.92211.979431.424072.662641.514380.8970231.211160.4900031.413872.344710.9618081.725542.639011.767771.526541.773070.474890.737131.323370.48160.7009451.910930.6884431.523612.030061.231352.433221.058281.000911.655061.244741.553550.3370910.4231971.308820.2056411.31780.8025581.036580.6277072.078681.509511.281030.1702011.127751.479361.012391.006141.158761.246460.3833821.036551.082730.6571421.011252.674342.354170.4094451.978721.251440.9742022.310791.506322.065221.276750.8709761.110391.63371.212310.4582970.5357611.03681.842510.5143450.5416491.19871.261181.256171.22131.371520.6112451.066731.0530.1301640.525781.910790.7818770.722291.450342.043190.5321252.058140.1718340.948870.720610.5322740.5367080.5896830.3956460.534580.5077240.3546260.728470.8935010.4712120.7593141.377580.7991450.6911630.2880741.129630.5508960.9993251.023740.7261060.2204910.9175090.4357990.5026970.2129291.156380.8346460.4969721.187010.5606991.044620.2570.4003661.135382.097341.43670.8821421.192170.5808720.2976160.401890.214231.58420.2424841.005980.4217950.1035350.8210810.1905330.4947271.102361.129220.3802381.103781.424281.211780.6076250.7203680.8542731.048020.5291860.6439461.002930.3392271.094660.1616450.3560030.8847070.6776620.9006650.332320.3368890.8842620.7647690.6776980.9044340.5589671.708050.8172460.3194670.8796910.9693671.099070.8290530.732971.020470.979410.2533961.089880.7817340.9302050.4414340.1001132.052320.634641.114861.52274. Replicate 4, 3 iterations, total sum of distances = 0.9879171.79822.012450.8117850.42111.476630.935910.7658763.92211.979431.424072.662641.514380.8970231.211160.4900031.413872.344710.9618081.725542.639011.767771.526541.773070.474890.737131.323370.48160.7009451.910930.6884431.523612.030061.231352.433221.058281.000911.655061.244741.553550.3370910.4231971.308820.2056411.31780.8025581.036580.6277072.078681.509511.281030.1702011.127751.479361.012391.006141.158761.246460.3833821.036551.082730.6571421.011252.674342.354170.4094451.978721.251440.9742022.310791.506322.065221.276750.8709761.110391.63371.212310.4582970.5357611.03681.842510.5143450.5416491.19871.261181.256171.22131.371520.6112451.066731.0530.1301640.525781.910790.7818770.722291.450342.043190.5321252.058140.1718340.948870.720610.5322740.5367080.5896830.3956460.534580.5077240.3546260.728470.8935010.4712120.7593141.377580.7991450.6911630.2880741.129630.5508960.9993251.023740.7261060.2204910.9175090.4357990.5026970.2129291.156380.8346460.4969721.187010.5606991.044620.2570.4003661.135382.097341.43670.8821421.192170.5808720.2976160.401890.214231.58420.2424841.005980.4217950.1035350.8210810.1905330.4947271.102361.129220.3802381.103781.424281.211780.6076250.7203680.8542731.048020.5291860.6439461.002930.3392271.094660.1616450.3560030.8847070.6776620.9006650.332320.3368890.8842620.7647690.6776980.9044340.5589671.708050.8172460.3194670.8796910.9693671.099070.8290530.732971.020470.979410.2533961.089880.7817340.9302050.4414340.1001132.052320.634641.114861.52274. Replicate 5, 2 iterations, total sum of distances = 0.9879171.79822.012450.8117850.42111.476630.935910.7658763.92211.979431.424072.662641.514380.8970231.211160.4900031.413872.344710.9618081.725542.639011.767771.526541.773070.474890.737131.323370.48160.7009451.910930.6884431.523612.030061.231352.433221.058281.000911.655061.244741.553550.3370910.4231971.308820.2056411.31780.8025581.036580.6277072.078681.509511.281030.1702011.127751.479361.012391.006141.158761.246460.3833821.036551.082730.6571421.011252.674342.354170.4094451.978721.251440.9742022.310791.506322.065221.276750.8709761.110391.63371.212310.4582970.5357611.03681.842510.5143450.5416491.19871.261181.256171.22131.371520.6112451.066731.0530.1301640.525781.910790.7818770.722291.450342.043190.5321252.058140.1718340.948870.720610.5322740.5367080.5896830.3956460.534580.5077240.3546260.728470.8935010.4712120.7593141.377580.7991450.6911630.2880741.129630.5508960.9993251.023740.7261060.2204910.9175090.4357990.5026970.2129291.156380.8346460.4969721.187010.5606991.044620.2570.4003661.135382.097341.43670.8821421.192170.5808720.2976160.401890.214231.58420.2424841.005980.4217950.1035350.8210810.1905330.4947271.102361.129220.3802381.103781.424281.211780.6076250.7203680.8542731.048020.5291860.6439461.002930.3392271.094660.1616450.3560030.8847070.6776620.9006650.332320.3368890.8842620.7647690.6776980.9044340.5589671.708050.8172460.3194670.8796910.9693671.099070.8290530.732971.020470.979410.2533961.089880.7817340.9302050.4414340.1001132.052320.634641.114861.52274. Best total sum of distances = 201.533
기본적으로, 소프트웨어는 k-평균++를 사용하여 개별적으로 반복 실험을 초기화합니다.
군집과 군집 중심을 플로팅합니다.
figure; plot(X(idx==1,1),X(idx==1,2),'r.','MarkerSize',12) hold on plot(X(idx==2,1),X(idx==2,2),'b.','MarkerSize',12) plot(C(:,1),C(:,2),'kx',... 'MarkerSize',15,'LineWidth',3) legend('Cluster 1','Cluster 2','Centroids',... 'Location','NW') title 'Cluster Assignments and Centroids' hold off

idx를 silhouette에 전달하여 군집이 얼마나 잘 분리되었는지 확인할 수 있습니다.
대규모 데이터 세트를 군집화하는 데는 시간이 걸릴 수 있으며, 특히 온라인 업데이트(기본적으로 설정됨)를 사용하는 경우 그렇습니다. Parallel Computing Toolbox™ 라이선스가 있는 경우 병렬 연산에 사용할 옵션을 설정하면 kmeans가 병렬로 각 군집화 작업(또는 반복 실험)을 실행합니다. 그리고 Replicates > 1이면 병렬 연산이 수렴 시간을 줄여 줍니다.
가우스 혼합 모델에서 대규모 데이터 세트를 임의로 생성합니다.
rng(1); % For reproducibility Mu = ones(20,30).*(1:20)'; % Gaussian mixture mean rn30 = randn(30,30); Sigma = rn30'*rn30; % Symmetric and positive-definite covariance Mdl = gmdistribution(Mu,Sigma); % Define the Gaussian mixture distribution X = random(Mdl,10000);
Mdl은 20개 성분을 포함하는 30차원 gmdistribution 모델입니다. X는 Mdl에서 생성된 데이터로 구성된 10000×30 행렬입니다.
병렬 연산에 사용할 옵션을 지정합니다.
stream = RandStream('mlfg6331_64'); % Random number stream options = statset('UseParallel',1,'UseSubstreams',1,... 'Streams',stream);
RandStream의 입력 인수 'mlfg6331_64'는 승산식 시차 피보나치 수열(Multiplicative Lagged Fibonacci) 생성기 알고리즘을 사용하도록 지정합니다. options는 추정을 제어하는 옵션 지정 필드가 포함된 구조체형 배열입니다.
k-평균 군집화를 사용하여 데이터를 군집화합니다. 데이터에 20개 군집(k = 20)이 있다고 지정하고 반복 횟수를 늘립니다. 일반적으로, 목적 함수는 국소 최솟값을 포함합니다. 더 낮은 국소 최솟값을 구하는 데 도움이 되도록 10회 반복 실험을 지정합니다.
tic; % Start stopwatch timer [idx,C,sumd,D] = kmeans(X,20,'Options',options,'MaxIter',10000,... 'Display','final','Replicates',10);
Starting parallel pool (parpool) using the 'Processes' profile ... 08-Nov-2024 15:52:23: Job Queued. Waiting for parallel pool job with ID 2 to start ... Connected to parallel pool with 4 workers. Replicate 2, 56 iterations, total sum of distances = 7.62036e+06. Replicate 4, 79 iterations, total sum of distances = 7.62412e+06. Replicate 3, 76 iterations, total sum of distances = 7.62583e+06. Replicate 1, 94 iterations, total sum of distances = 7.60746e+06. Replicate 5, 103 iterations, total sum of distances = 7.61753e+06. Replicate 7, 77 iterations, total sum of distances = 7.61939e+06. Replicate 6, 96 iterations, total sum of distances = 7.6258e+06. Replicate 8, 113 iterations, total sum of distances = 7.60741e+06. Replicate 10, 66 iterations, total sum of distances = 7.62582e+06. Replicate 9, 80 iterations, total sum of distances = 7.60592e+06. Best total sum of distances = 7.60592e+06
toc % Terminate stopwatch timerElapsed time is 86.846475 seconds.
명령 창에 6개의 워커를 사용할 수 있다고 표시되어 있습니다. 워커의 개수는 시스템에 따라 다를 수 있습니다. 명령 창에 반복 횟수와 각 반복 실험에 대한 최종 목적 함수 값이 표시됩니다. 반복 실험 9가 가장 작은 거리 총합을 가지므로 출력 인수에는 이 반복 실험의 결과가 포함됩니다.
kmeans는 k-평균 군집화를 수행하여 데이터를 k개의 군집으로 분할합니다. 군집화를 수행할 새 데이터 세트가 있는 경우 kmeans를 사용하여 기존 데이터와 새 데이터를 포함하는 새 군집을 생성할 수 있습니다. kmeans 함수는 C/C++ 코드 생성을 지원하므로 훈련 데이터를 받아서 군집화 결과를 반환하는 코드를 생성한 다음 코드를 장치에 배포할 수 있습니다. 이 워크플로에서는 훈련 데이터를 전달해야 하는데, 그 크기가 상당히 클 수 있습니다. 장치의 메모리를 절약하기 위해 각각 kmeans와 pdist2를 사용하여 훈련과 예측을 분리할 수 있습니다.
kmeans를 사용하여 MATLAB®에서 군집을 생성하고 생성된 코드에서 pdist2를 사용하여 기존 군집에 새 데이터를 할당합니다. 코드 생성을 위해, 군집 중심 위치와 새 데이터 세트를 받아서 가장 가까운 군집의 인덱스를 반환하는 진입점 함수를 정의합니다. 그런 다음 진입점 함수에 대한 코드를 생성합니다.
C/C++ 코드를 생성하려면 MATLAB® Coder™가 필요합니다.
k-평균 군집화 수행하기
세 개의 분포를 사용하여 훈련 데이터 세트를 생성합니다.
rng('default') % For reproducibility X = [randn(100,2)*0.75+ones(100,2); randn(100,2)*0.5-ones(100,2); randn(100,2)*0.75];
kmeans를 사용하여 훈련 데이터를 세 개 군집으로 분할합니다.
[idx,C] = kmeans(X,3);
군집과 군집 중심을 플로팅합니다.
figure gscatter(X(:,1),X(:,2),idx,'bgm') hold on plot(C(:,1),C(:,2),'kx') legend('Cluster 1','Cluster 2','Cluster 3','Cluster Centroid')

기존 군집에 새 데이터 할당하기
테스트 데이터 세트를 생성합니다.
Xtest = [randn(10,2)*0.75+ones(10,2);
randn(10,2)*0.5-ones(10,2);
randn(10,2)*0.75];기존 군집을 사용하여 테스트 데이터 세트를 분류합니다. pdist2를 사용하여 각 테스트 데이터 점에서 가장 가까운 중심을 구합니다.
[~,idx_test] = pdist2(C,Xtest,'euclidean','Smallest',1);
gscatter를 사용하여 테스트 데이터를 플로팅하고 idx_test를 사용하여 테스트 데이터에 레이블을 지정합니다.
gscatter(Xtest(:,1),Xtest(:,2),idx_test,'bgm','ooo') legend('Cluster 1','Cluster 2','Cluster 3','Cluster Centroid', ... 'Data classified to Cluster 1','Data classified to Cluster 2', ... 'Data classified to Cluster 3')

코드 생성하기
기존 군집에 새 데이터를 할당하는 C 코드를 생성합니다. C/C++ 코드를 생성하려면 MATLAB® Coder™가 필요합니다.
중심 위치와 새 데이터를 받는 findNearestCentroid라는 이름의 진입점 함수를 정의한 다음 pdist2를 사용하여 가장 가까운 군집을 찾습니다.
진입점 함수의 함수 시그니처 뒤에 %#codegen 컴파일러 지시문(또는 pragma)을 추가하여 MATLAB 알고리즘을 위한 코드를 생성하고자 함을 표시합니다. 이 지시문을 추가하면 MATLAB 코드 분석기에 코드 생성 중에 오류를 유발할 수 있는 위반을 진단하여 수정할 수 있도록 지원해 달라는 명령을 내리게 됩니다.
type findNearestCentroid % Display contents of findNearestCentroid.m
function idx = findNearestCentroid(C,X) %#codegen [~,idx] = pdist2(C,X,'euclidean','Smallest',1); % Find the nearest centroid
참고: 이 페이지의 오른쪽 위 섹션에 있는 버튼을 클릭하고 이 예제를 MATLAB®에서 열면 예제 폴더가 열립니다. 이 폴더에는 진입점 함수 파일이 포함되어 있습니다.
codegen (MATLAB Coder)을 사용하여 코드를 생성합니다. C와 C++는 정적 유형 언어이므로 컴파일 시점에 진입점 함수의 모든 변수의 속성을 결정해야 합니다. findNearestCentroid의 입력값 크기와 데이터형을 지정하려면 -args 옵션을 사용하여 특정 데이터형과 배열 크기를 포함하는 값 세트를 나타내는 MATLAB 표현식을 전달하십시오. 자세한 내용은 Specify Variable-Size Arguments for Code Generation of Machine Learning Models 항목을 참조하십시오.
codegen findNearestCentroid -args {C,Xtest}
Code generation successful.
codegen은 플랫폼별 확장자를 갖는 MEX 함수 findNearestCentroid_mex를 생성합니다.
생성된 코드를 확인합니다.
myIndx = findNearestCentroid(C,Xtest); myIndex_mex = findNearestCentroid_mex(C,Xtest); verifyMEX = isequal(idx_test,myIndx,myIndex_mex)
verifyMEX = logical
1
isequal이 논리값 1(true)을 반환합니다. 이는 모든 입력값이 동일하다는 의미입니다. 비교를 통해 pdist2 함수, findNearestCentroid 함수 및 MEX 함수가 동일한 인덱스를 반환함을 확인할 수 있습니다.
GPU Coder™를 사용하여 최적화된 CUDA® 코드를 생성할 수도 있습니다.
cfg = coder.gpuConfig('mex'); codegen -config cfg findNearestCentroid -args {C,Xtest}
코드 생성에 대한 자세한 내용은 항목을 참조하십시오. GPU Coder에 대한 자세한 내용은 GPU Coder 시작하기 (GPU Coder) 항목과 지원되는 함수 (GPU Coder) 항목을 참조하십시오.
kmeans 함수는 누락값을 포함하는 테이블 행을 무시합니다. k-평균 군집화에 입력 데이터의 모든 행을 사용하기 위해 회귀 모델을 사용하여 누락값을 대치할 수 있습니다.
carbig 데이터 세트를 불러오고 Weight 예측 변수, Displacement 예측 변수, Horsepower 예측 변수를 포함하는 테이블을 만듭니다.
load carbig
X = table(Weight,Displacement,Horsepower);X의 각 열에 있는 누락값 개수를 표시합니다.
MissingValues = sum(ismissing(X))
MissingValues = 1×3
0 0 6
열 3(Horsepower)에는 6개의 누락값이 있습니다. 다른 열은 누락값을 포함하지 않습니다.
누락값을 포함하지 않는 행을 사용하여 다중 회귀 모델을 훈련시킵니다. Horsepower를 응답 변수로 지정합니다.
HPmodel = fitlm(rmmissing(X),"Horsepower");회귀 모델의 플롯을 표시합니다.
plot(HPmodel)
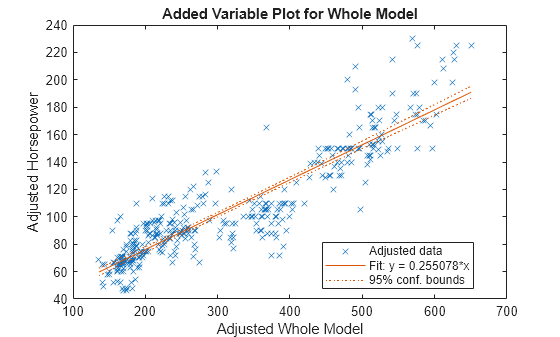
X에 있는 누락된 Horsepower 값을 선형 회귀 모델을 사용하여 대치합니다.
imputedHP = predict(HPmodel,X(any(ismissing(X),2),1:2))
imputedHP = 6×1
70.6749
105.0360
65.2328
90.0460
73.9490
94.1612
누락된 Horsepower 값을 대치 값으로 바꿉니다.
X(any(ismissing(X),2),3) = table(imputedHP);
k-평균 군집화를 사용하여 데이터를 군집화합니다. 데이터가 3개의 군집을 가지도록 지정합니다.
[idx,C] = kmeans(table2array(X),3);
데이터와 군집 할당을 플로팅합니다.
scatter3(X.Weight,X.Displacement,X.Horsepower,15,idx,"filled")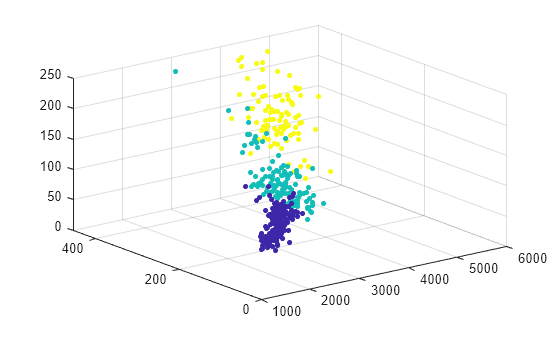
입력 인수
이름-값 인수
출력 인수
세부 정보
알고리즘
kmeans는 두 단계의 반복 알고리즘을 사용하여 모든k개 군집에 대해 합한 점-중심 간 거리의 합을 최소화합니다.이 첫 번째 단계는 각 반복에서 가장 가까운 군집 중심으로 점을 한 번에 재할당한 후 군집 중심을 재계산하는 일괄 업데이트를 사용합니다. 이 단계는 경우에 따라 국소 최솟값으로 해가 수렴되지 않습니다. 즉, 단일 점을 다른 군집으로 이동할 경우 거리의 총합이 증가하는 데이터의 분할이 이에 해당합니다. 이는 작은 데이터 세트에서 발생할 가능성이 더 큽니다. 일괄 단계는 빠르지만, 잠재적으로 두 번째 단계의 시작점으로만 해의 근삿값을 구합니다.
이 두 번째 단계는 점을 재할당 때 거리의 합이 줄어드는 경우 점을 개별적으로 재할당하고 재할당이 수행된 후마다 군집 중심을 재계산하는 온라인 업데이트를 사용합니다. 이 단계 동안 수행되는 각 반복마다 모든 점을 한 번씩 거칩니다. 이 단계는 국소 최솟값으로 수렴됩니다. 하지만 거리 총합이 더 낮은 다른 국소 최솟값이 있을 수 있습니다. 일반적으로 전역 최솟값은 모든 점을 시작점으로 빠짐없이 선택하면 구해지지만, 보통은 임의의 시작점들을 사용해 수차례 반복 실험하는 것만으로도 전역 최솟값이 구해집니다.
Replicates= r > 1이고Start가plus(디폴트 값)이면 소프트웨어가 k-평균++ 알고리즘에 따라 시드값으로 구성된 r개의 가능한 다른 세트를 선택합니다.Options에서UseParallel옵션을 활성화하고Replicates> 1이면 각 워커가 시드값과 군집을 병렬로 선택합니다.
참고 문헌
[1] Arthur, David, and Sergi Vassilvitskii. K-means++: The Advantages of Careful Seeding. In SODA ‘07: Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, 1027–1035. Society for Industrial and Applied Mathematics, 2007.
[2] Lloyd, S. Least Squares Quantization in PCM. IEEE Transactions on Information Theory 28, no. 2 (March 1982): 129–37.
[3] Seber, G. A. F. Multivariate Observations. Hoboken, NJ: John Wiley & Sons, Inc., 1984.
[4] Spath, H. Cluster Dissection and Analysis: Theory, FORTRAN Programs, Examples. Translated by J. Goldschmidt. New York: Halsted Press, 1985.
확장 기능
버전 내역
R2006a 이전에 개발됨
참고 항목
linkage | clusterdata | incrementalKMeans | silhouette | parpool (Parallel Computing Toolbox) | statset | gmdistribution | kmedoids