이 번역 페이지는 최신 내용을 담고 있지 않습니다. 최신 내용을 영문으로 보려면 여기를 클릭하십시오.
계층적 군집화
계층적 군집화 소개
계층적 군집화는 군집 트리 또는 덴드로그램(Dendrogram)을 생성하여 다양한 스케일에 대해 데이터를 그룹화합니다. 이 트리는 여러 군집으로 구성된 단일 세트가 아니라 다중 수준 계층입니다. 여기서 한 수준에 있는 군집은 다음 수준의 군집으로 결합됩니다. 이를 통해 응용 사례에 가장 적합한 군집화 수준이나 스케일을 결정할 수 있습니다. 함수 clusterdata는 병합 군집화를 지원하고 필요한 모든 단계를 수행합니다. 이 함수에는 pdist, linkage, cluster 함수가 통합되어 있습니다. 이러한 함수는 보다 세부적인 분석을 위해 개별적으로 사용할 수 있습니다. dendrogram 함수는 군집 트리를 플로팅합니다.
알고리즘 설명
Statistics and Machine Learning Toolbox™ 함수를 사용하여 데이터 세트에 대해 계층적 병합 군집 분석을 수행하려면 다음 절차를 따르십시오.
데이터 세트에 포함된 모든 객체 쌍 간의 유사성 또는 비유사성을 구합니다. 이 단계에서는
pdist함수를 사용하여 객체 간 거리를 계산합니다.pdist함수는 이 측정값을 계산할 수 있는 많은 다양한 방법을 지원합니다. 자세한 내용은 유사성 측정법 항목을 참조하십시오.객체를 계층적 이진 군집 트리로 그룹화합니다. 이 단계에서는
linkage함수를 사용하여 근접한 객체 쌍을 연결합니다.linkage함수는 단계 1에서 생성된 거리 정보를 사용하여 객체 간 근접도를 결정합니다. 객체가 이진 군집으로 쌍을 이룸에 따라, 새로 형성된 군집이 계층적 트리가 형성될 때까지 더 큰 군집으로 그룹화됩니다. 자세한 내용은 연결 항목을 참조하십시오.계층적 트리를 여러 군집으로 나누기 위한 절단 위치를 결정합니다. 이 단계에서는
cluster함수를 사용하여 계층적 트리의 맨 아래에서 가지치기를 하고 각 절단 아래에 있는 모든 객체를 하나의 군집에 할당합니다. 이렇게 하면 데이터의 분할이 생성됩니다.cluster함수는 계층적 트리에서 자연적 그룹화를 탐지하거나 임의의 점에서 계층적 트리를 절단하는 방식으로 이러한 군집을 생성할 수 있습니다.
다음 섹션에서 이러한 단계 각각에 대해 자세히 설명합니다.
참고
함수 clusterdata는 필요한 모든 단계를 수행합니다. pdist, linkage, cluster 함수를 개별적으로 실행할 필요가 없습니다.
유사성 측정법
pdist 함수를 사용하여 데이터 세트에 포함된 모든 객체 쌍 간의 거리를 계산합니다. m개 객체로 구성된 데이터 세트의 경우, 데이터 세트에 m*(m – 1)/2개 쌍이 있습니다. 이 계산의 결과는 일반적으로 거리 또는 비유사성 행렬로 알려져 있습니다.
이러한 거리 정보를 계산할 수 있는 방법이 많이 있습니다. 기본적으로, pdist 함수는 객체 간 유클리드 거리(Euclidean Distance)를 계산합니다. 그러나, 여러 다른 옵션 중 하나를 지정할 수 있습니다. 자세한 내용은 pdist를 참조하십시오.
참고
선택적으로, 거리 정보를 계산하기 전에 데이터 세트에 포함된 값을 정규화할 수 있습니다. 실세계의 데이터 세트에서 변수는 다양한 스케일로 측정될 수 있습니다. 예를 들어, 한 변수는 IQ(지능 지수) 검사 점수를 측정하고 다른 변수는 머리 둘레를 측정할 수 있습니다. 이러한 차이는 근접도 계산을 왜곡할 수 있습니다. zscore 함수를 사용하여 동일한 비례적 스케일을 사용하도록 데이터 세트에 포함된 모든 값을 변환할 수 있습니다. 자세한 내용은 zscore를 참조하십시오.
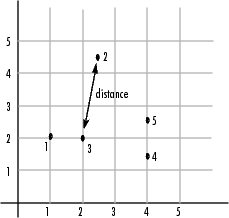
예를 들어, 각 개체가 x,y 좌표 세트인 5개 객체로 구성된 데이터 세트 X가 있다고 가정해 보겠습니다.
객체 1: 1, 2
객체 2: 2.5, 4.5
객체 3: 2, 2
객체 4: 4, 1.5
객체 5: 4, 2.5
다음과 같이 이 데이터 세트를 행렬로 정의할 수 있습니다.
rng("default") % For reproducibility X = [1 2; 2.5 4.5; 2 2; 4 1.5; ... 4 2.5];
그런 다음 pdist로 전달할 수 있습니다. pdist 함수는 객체 1과 객체 2, 객체 1과 객체 3 등의 식으로 모든 쌍 간의 거리가 계산될 때까지 객체 간의 거리를 계산합니다. 다음 그림은 그래프에 이러한 객체를 플로팅한 것입니다. 거리에 대한 한 해석을 보여주기 위해 객체 2와 객체 3 간의 유클리드 거리가 표시되어 있습니다.
거리 정보
pdist 함수는 각 요소가 객체 쌍 간의 거리를 포함하는 벡터 Y로 이 거리 정보를 반환합니다.
Y = pdist(X)
Y =
Columns 1 through 6
2.9155 1.0000 3.0414 3.0414 2.5495 3.3541
Columns 7 through 10
2.5000 2.0616 2.0616 1.0000squareform 함수를 사용하여 거리 벡터를 행렬로 형식을 다시 지정하면 pdist로 생성된 거리 정보와 원래 데이터 세트의 객체와의 관계를 더욱 쉽게 파악할 수 있습니다. 이 행렬에서 요소 i,j는 원래 데이터 세트의 객체 i와 객체 j 간의 거리에 대응됩니다. 다음 예제에서 요소 1,1은 객체 1과 그 자신 간의 거리를 나타냅니다(0임). 요소 1,2는 객체 1과 객체 2 간의 거리를 나타내는 식입니다.
squareform(Y)
ans =
0 2.9155 1.0000 3.0414 3.0414
2.9155 0 2.5495 3.3541 2.5000
1.0000 2.5495 0 2.0616 2.0616
3.0414 3.3541 2.0616 0 1.0000
3.0414 2.5000 2.0616 1.0000 0연결
데이터 세트의 객체 간 근접도를 계산한 후에는 linkage 함수를 사용하여 데이터 세트의 객체를 어떻게 군집으로 그룹화할지 결정할 수 있습니다. linkage 함수는 pdist로 생성된 거리 정보를 사용하여 서로 가까이 있는 객체 쌍들을 연결해 이진 군집(두 객체로 구성된 군집)으로 만듭니다. 그런 다음, linkage 함수는 원래 데이터 세트의 모든 객체가 계층적 트리에서 모두 연결될 때까지 이렇게 새로 형성된 군집을 서로 간에 그리고 다른 객체에 연결하여 더 큰 군집을 생성합니다.
예를 들어, x 좌표와 y 좌표로 구성된 표본 데이터 세트에서 pdist에 의해 생성된 거리 벡터 Y가 있다고 가정할 경우 linkage 함수는 행렬 Z로 연결 정보를 반환하는 계층적 군집 트리를 생성합니다.
Z = linkage(Y)
Z =
4.0000 5.0000 1.0000
1.0000 3.0000 1.0000
6.0000 7.0000 2.0616
2.0000 8.0000 2.5000이 출력값에서 각 행은 객체 또는 군집 사이의 링크를 나타냅니다. 처음 두 열은 연결된 객체를 식별합니다. 세 번째 열은 이러한 객체들 간의 거리를 식별합니다. x 좌표와 y 좌표로 구성된 표본 데이터 세트에 대해 linkage 함수는 먼저 가장 근접해 있는 객체 4와 객체 5(거리 값 = 1.0000)를 그룹화합니다. 계속해서 linkage 함수는 거리 값이 역시 1.0000인 객체 1과 객체 3을 그룹화합니다.
세 번째 행은 linkage 함수가 객체 6과 객체 7을 그룹화했음을 나타냅니다. 원래 표본 데이터 세트에 5개 객체만 포함되었다면 객체 6과 객체 7은 무엇일까요? 객체 6은 객체 4와 객체 5의 그룹화를 통해 만들어진 새로 형성된 이진 군집입니다. linkage 함수는 두 객체를 새 군집으로 그룹화할 때 값 m + 1(여기서 m은 원래 데이터 세트에 포함된 객체의 개수임)로 시작하는 고유한 인덱스 값을 군집에 할당해야 합니다. (값 1~m은 원래 데이터 세트에서 이미 사용되었습니다.) 마찬가지로 객체 7은 객체 1과 객체 3의 그룹화를 통해 형성된 군집입니다.
linkage는 거리를 사용하여 객체를 군집화하는 순서를 결정합니다. 거리 벡터 Y는 원래 객체 1~5 간의 거리를 포함합니다. 그러나 연결은 객체 6 및 객체 7과 같이 생성하는 군집과 관련된 거리도 결정할 수 있어야 합니다. 기본적으로, linkage는 단일 연결이라고 하는 방법을 사용합니다. 그러나, 사용할 수 있는 방법에는 여러 가지가 있습니다. 자세한 내용은 linkage 도움말 페이지를 참조하십시오.
마지막 군집으로 linkage 함수는 객체 6과 객체 7로 구성된 새로 형성된 군집인 객체 8을 원래 데이터 세트의 객체 2와 그룹화했습니다. 다음 그림은 linkage가 객체를 군집의 계층으로 그룹화하는 방식을 시각적으로 보여줍니다.
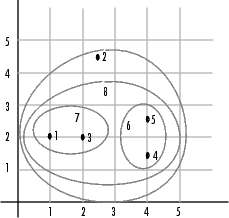
덴드로그램(Dendrogram)
linkage 함수로 생성된 계층적 이진 군집 트리는 그래픽으로 볼 때 가장 쉽게 이해할 수 있습니다. 함수 dendrogram은 다음과 같이 트리를 플로팅합니다.
dendrogram(Z)

이 그림에서 가로 축의 숫자는 원래 데이터 세트에 포함된 객체의 인덱스를 나타냅니다. 객체 간 링크는 거꾸로 된 U자 모양의 선으로 표시되어 있습니다. U의 높이는 객체 간 거리를 나타냅니다. 예를 들어, 객체 1과 객체 3을 포함하는 군집을 나타내는 링크는 높이가 1입니다. 객체 2를 객체 1, 3, 4, 5(이미 객체 8로 군집화되어 있음)와 함께 그룹화하는 군집을 나타내는 링크는 높이가 2.5입니다. 이 높이는 linkage가 객체 2와 객체 8 간을 계산한 거리를 나타냅니다. 덴드로그램 다이어그램 생성에 대한 자세한 내용은 dendrogram 도움말 페이지를 참조하십시오.
군집 트리 확인하기
데이터 세트의 객체를 계층적 군집 트리에 연결한 후에, 트리의 거리(즉, 높이)가 원래 거리를 정확히 나타내는지 확인하고자 할 수 있습니다. 또한, 객체 간 링크 사이에 존재하는 자연적인 분할을 조사하고자 할 수도 있습니다. 이러한 작업 모두에 Statistics and Machine Learning Toolbox 함수를 사용할 수 있으며, 이에 대해서는 다음 섹션에 설명되어 있습니다.
비유사성 확인하기
계층적 군집 트리에서 원래 데이터 세트에 포함된 임의의 두 객체는 최종적으로 특정 수준에서 연결됩니다. 링크의 높이는 이 두 객체를 포함하는 두 군집 간의 거리를 나타냅니다. 이 높이를 두 객체 간 코페네틱 거리(Cophenetic Distance)라고 합니다. linkage 함수로 생성된 군집 트리가 데이터를 얼마나 잘 반영하는지 측정하는 한 가지 방법은 pdist 함수로 생성된 원래 거리 데이터와 코페네틱 거리를 비교하는 것입니다. 군집화가 유효한 경우 군집 트리의 객체 연결은 거리 벡터의 객체 간 거리와 강한 상관관계를 가져야 합니다. cophenet 함수는 이러한 두 개의 값 세트를 비교하고 상관관계를 계산하여 코페네틱 상관 계수(Cophenetic Correlation Coefficient)라고 하는 값을 반환합니다. 코페네틱 상관 계수의 값이 1에 가까울수록 군집화 해가 데이터를 더 정확히 반영합니다.
코페네틱 상관 계수를 사용하면, 동일한 데이터 세트를 다양한 거리 계산 방법 또는 군집화 알고리즘을 통해 군집화한 결과를 비교해 볼 수 있습니다. 예를 들어, cophenet 함수를 사용하여 표본 데이터 세트에 대해 생성된 군집을 평가할 수 있습니다.
c = cophenet(Z,Y)
c =
0.8615Z는 linkage 함수에서 반환된 행렬 출력값이고 Y는 pdist 함수에서 반환된 거리 벡터 출력값입니다.
이번에는 도시 블록(City Block) 측정법을 지정하여 동일한 데이터 세트에 대해 pdist를 다시 실행합니다. 평균 연결 방법을 사용하여 이 새 pdist 출력값에 대해 linkage 함수를 실행한 후 cophenet를 호출하여 군집화 해를 평가합니다.
Y = pdist(X,"cityblock"); Z = linkage(Y,"average"); c = cophenet(Z,Y)
c =
0.9047코페네틱 상관 계수는 다른 거리와 연결 방법을 사용하면 원래 거리를 좀 더 정확히 표현하는 트리가 생성된다는 것을 보여줍니다.
일치성 확인하기
데이터 세트에서 자연적인 군집 분할을 결정하는 한 가지 방법은 군집 트리의 각 링크 높이를 트리에서 그 하위에 있는 인접 링크의 높이와 비교하는 것입니다.
하위 링크와 높이가 거의 같은 링크는 이 계층 수준에서 결합된 객체 간에 뚜렷한 분할이 없음을 나타냅니다. 이러한 링크는 결합된 객체 간의 거리가 해당 객체에 포함된 객체들 간의 거리와 거의 같기 때문에 높은 일치성 수준을 보이는 것으로 간주됩니다.
반면에, 높이가 하위 링크의 높이와 눈에 띄게 다른 링크는 군집 트리의 이 수준에서 결합된 객체들이 해당 객체의 성분들이 결합될 때보다 훨씬 더 서로 떨어져 있음을 나타냅니다. 이러한 링크는 하위 링크와 일치하지 않는 것으로 간주됩니다.
군집 분석에서, 일치하지 않는 링크는 데이터 세트에서 자연적인 분할의 경계를 나타낼 수 있습니다. cluster 함수는 불일치에 대한 정량적 측정을 통해 데이터 세트를 군집으로 분할할 위치를 결정합니다.
다음 덴드로그램에서는 일치하지 않는 링크를 보여줍니다. 덴드로그램의 객체가 트리의 훨씬 더 높은 수준에 있는 링크로 연결되어 있는 두 그룹에 어떤 식으로 속해 있는지를 확인합니다. 이러한 링크를 계층의 하위에 있는 링크와 비교하면 일치하지 않는 것을 알 수 있습니다.
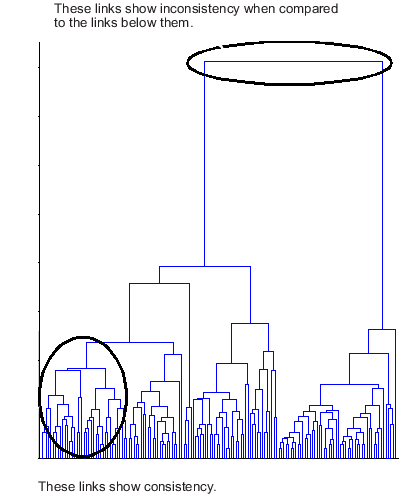
계층적 군집 트리에 포함된 각 링크의 상대적인 일치성을 정량적으로 측정하여 불일치 계수로 표현할 수 있습니다. 이 값은 군집 계층에서 특정 링크의 높이를 하위 링크의 평균 높이와 비교합니다. 완전히 구별되는 군집을 결합하는 링크는 높은 불일치 계수를 가지며, 그다지 구별되지 않는 군집을 결합하는 링크는 낮은 불일치 계수를 가집니다.
군집 트리의 각 링크에 대한 불일치 계수 목록을 생성하려면 inconsistent 함수를 사용하십시오. 기본적으로, inconsistent 함수는 군집 계층의 각 링크를 군집 계층에서 두 수준 미만으로 하위에 있는 인접 링크들과 비교합니다. 이를 비교의 깊이라고 합니다. 다른 깊이를 지정할 수도 있습니다. 리프 노드라고 하는 군집 트리의 맨 아래에 있는 객체는 하위에 더 이상 객체가 없으며 불일치 계수 0을 가집니다. 두 리프를 결합하는 군집도 불일치 계수 0을 가집니다.
예를 들어, inconsistent 함수를 사용하여 연결에 설명되어 있는 linkage 함수로 생성된 링크에 대한 불일치 값을 계산할 수 있습니다.
먼저, 디폴트 설정을 사용하여 거리 값과 연결 값을 다시 계산합니다.
Y = pdist(X); Z = linkage(Y);
다음으로, inconsistent를 사용하여 불일치 값을 계산합니다.
I = inconsistent(Z)
I =
1.0000 0 1.0000 0
1.0000 0 1.0000 0
1.3539 0.6129 3.0000 1.1547
2.2808 0.3100 2.0000 0.7071inconsistent 함수는 (m-1)×4 행렬로 링크에 대한 데이터를 반환합니다. 이 행렬의 열은 다음 표에 설명되어 있습니다.
| 열 | 설명 |
|---|---|
1 | 계산에 포함된 모든 링크의 높이에 대한 평균 |
2 | 계산에 포함된 모든 링크의 표준편차 |
3 | 계산에 포함된 링크의 수 |
4 | 불일치 계수 |
표본 출력값에서 첫 번째 행은 객체 4와 객체 5 간의 링크를 나타냅니다. 이 군집에는 linkage 함수에 의해 인덱스 6이 할당됩니다. 4와 5 모두 리프 노드이기 때문에 이 군집의 불일치 계수는 0입니다. 두 번째 행은 객체 1과 객체 3 간의 링크를 나타냅니다. 두 객체도 모두 리프 노드입니다. 이 군집에는 연결 함수에 의해 인덱스 7이 할당됩니다.
세 번째 행은 이러한 두 군집인 객체 6과 객체 7을 연결하는 링크를 평가합니다. 이 새 군집에는 linkage 출력값에서 인덱스 8이 할당됩니다. 열 3은 링크 자체와 계층에서 그 바로 밑에 있는 두 개의 링크, 즉 세 개의 링크가 계산에 고려되었음을 나타냅니다. 열 1은 이러한 링크 높이의 평균을 나타냅니다. inconsistent 함수는 linkage 함수에서 반환되는 높이 정보 출력값을 사용하여 평균을 계산합니다. 열 2는 링크 간의 표준편차를 나타냅니다. 마지막 열은 이러한 링크의 불일치 값인 1.1547을 포함합니다. 이는 현재 링크 높이와 평균 간의 차이로, 표준편차를 사용해 정규화한 값입니다.
(2.0616 - 1.3539) / 0.6129
ans =
1.1547다음 그림에서는 이 계산에 포함된 링크와 높이를 보여줍니다.
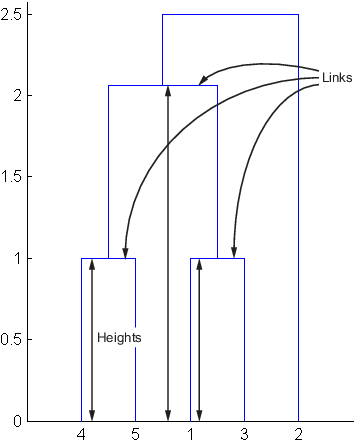
참고
앞의 그림에서 y 축의 하한은 링크의 높이를 표시하기 위해 0으로 설정되어 있습니다. 하한을 0으로 설정하려면 편집 메뉴에서 axes 속성을 선택하고 Y축 탭을 클릭한 후 Y 제한의 바로 오른쪽에 있는 필드에 0을 입력하십시오.
출력 행렬의 4행은 객체 8과 객체 2 간의 링크를 설명합니다. 3열은 링크 자체와 계층에서 그 바로 밑에 있는 링크, 즉 두 개의 링크가 이 계산에 포함되었음을 나타냅니다. 이 링크의 불일치 계수는 0.7071입니다.
다음 그림에서는 이 계산에 포함된 링크와 높이를 보여줍니다.
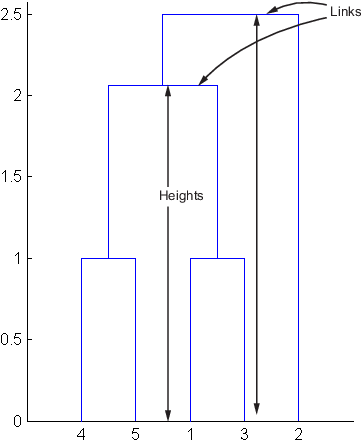
군집 만들기
이진 군집의 계층적 트리를 생성한 후에는 cluster 함수를 사용하여 트리를 가지치기함으로써 데이터를 군집으로 분할할 수 있습니다. cluster 함수를 사용하면 두 가지 방법으로 군집을 생성할 수 있습니다. 이에 대해서는 다음 섹션에 설명되어 있습니다.
데이터에서 자연적인 분할 찾기
계층적 군집 트리는 데이터를 잘 분리된 고유한 군집들로 자연스럽게 분할할 수 있습니다. 이는 데이터에서 생성된 덴드로그램 다이어그램에서 특히 명확하게 나타날 수 있습니다. 여기서 객체의 그룹은 다른 영역과 구별될 정도로 특정 영역에 조밀하게 밀집해 있습니다. 군집 트리에 포함된 링크가 갖는 불일치 계수를 통해 객체 간 유사성이 급격히 변하는 이러한 분할을 식별할 수 있습니다. 불일치 계수에 대한 자세한 내용은 군집 트리 확인하기 항목을 참조하십시오. 이 값을 사용하여 cluster 함수가 만드는 군집 경계의 위치를 확인할 수 있습니다.
예를 들어, cutoff 인수의 값으로 불일치 계수 분계점을 1.2로 지정해 cluster 함수로 표본 데이터 세트를 군집으로 그룹화하면 cluster 함수는 표본 데이터 세트의 모든 객체를 하나의 군집으로 그룹화합니다. 이 경우, 군집 계층의 어떤 링크도 1.2보다 큰 불일치 계수를 가지지 않습니다.
T = cluster(Z,"cutoff",1.2)T =
1
1
1
1
1cluster 함수는 원래 데이터 세트와 크기가 같은 벡터 T를 출력합니다. 이 벡터의 각 요소는 원래 데이터 세트의 해당 객체가 배치된 군집의 번호를 포함합니다.
불일치 계수 분계점을 0.8로 낮추면 cluster 함수가 표본 데이터 세트를 3개의 개별 군집으로 분할합니다.
T = cluster(Z,"cutoff",0.8)T =
1
2
1
3
3이 출력값은 객체 1과 객체 3이 하나의 군집에 있고, 객체 4와 객체 5가 다른 군집에 있으며, 객체 2가 자체적인 군집에 있다는 것을 나타냅니다.
군집이 이 방식으로 형성된 경우 절단 값이 불일치 계수에 적용됩니다. 이러한 군집은 반드시 그런 것은 아니지만 덴드로그램을 특정 높이에서 잘랐을 때의 수평 슬라이스에 대응될 수 있습니다. 덴드로그램의 수평 슬라이스에 대응되는 군집을 원하는 경우 criterion 옵션을 사용하여 절단이 불일치 대신 거리를 기반으로 해야 함을 지정하거나 다음 섹션에 설명된 대로 직접 군집 개수를 지정할 수도 있습니다.
임의 군집 지정하기
cluster 함수가 데이터 세트의 자연적인 분할로 결정된 군집을 생성하도록 하는 대신, 생성하려는 군집 개수를 지정할 수 있습니다.
예를 들어, cluster 함수가 표본 데이터 세트를 두 군집으로 분할하도록 지정할 수 있습니다. 이 경우, cluster 함수는 객체 1, 3, 4, 5를 포함하는 군집 하나와 객체 2를 포함하는 또 다른 군집 하나를 생성합니다.
T = cluster(Z,"maxclust",2)T =
2
1
2
2
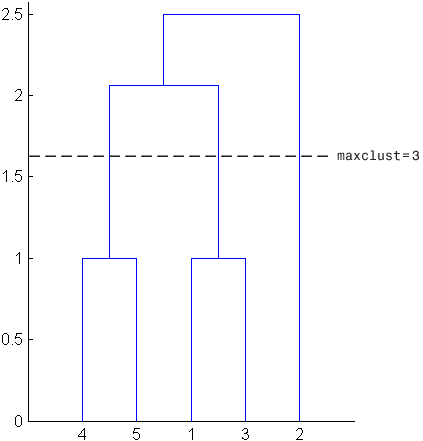
2cluster 함수가 이러한 군집을 결정하는 방법을 시각화하는 데 도움이 되도록 다음 그림에서는 계층적 군집 트리의 덴드로그램을 보여줍니다. 가로 파선은 덴드로그램의 두 선을 교차합니다. 이는 maxclust를 2로 설정하는 것에 해당합니다. 이 두 선은 객체를 두 군집으로 분할합니다. 왼쪽 선 아래에 있는 객체 1, 3, 4, 5가 한 군집에 속하고, 오른쪽 선 아래에 있는 객체 2가 또 다른 군집에 속합니다.
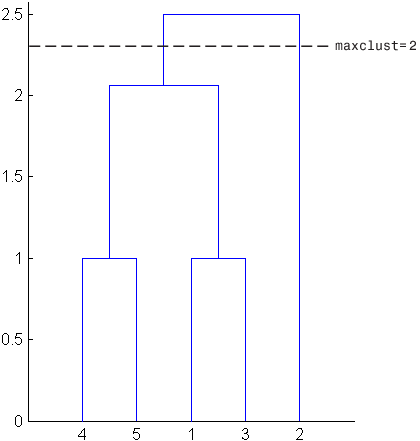
반면, maxclust를 3으로 설정하면 군집 함수가 객체 4와 객체 5를 한 군집에 그룹화하고, 객체 1과 객체 3을 두 번째 군집에 그룹화하고, 객체 2를 세 번째 군집에 그룹화합니다. 다음 명령은 이를 보여줍니다.
T = cluster(Z,"maxclust",3)T =
1
3
1
2
2이번에는 cluster 함수가 하위 점에서 계층을 절단합니다. 이는 다음 그림에서 덴드로그램의 3개 선을 교차하는 가로선에 해당합니다.