var
구문
설명
V = var(A)A의 요소의 분산을 반환합니다. 기본적으로, 분산은 N-1로 정규화됩니다. 여기서 N은 관측값의 개수입니다.
A가 관측값으로 구성된 벡터인 경우V는 스칼라입니다.A가 열이 확률 변수이고 행이 관측값인 행렬인 경우,V는 각 열에 대응하는 분산이 포함된 행 벡터입니다.A가 다차원 배열인 경우var(A)는 크기가 1이 아닌 첫 번째 배열 차원을 따라 연산을 수행하며, 요소를 벡터로 취급합니다. 이 차원에서V의 크기는1이 되고 다른 모든 차원의 크기는A와 동일합니다.A가 스칼라인 경우V는0입니다.A가0×0의 빈 배열이면V는NaN이 됩니다.A가 테이블 또는 타임테이블인 경우var(A)는 각 변수의 분산을 포함하는 한 행 크기의 테이블을 반환합니다. (R2023a 이후)
예제
입력 인수
입력 배열로, 벡터, 행렬, 다차원 배열, table형 또는 timetable형으로 지정됩니다. A가 스칼라이면 var(A)는 0을 반환합니다. A가 0×0의 빈 배열인 경우 var(A)는 NaN을 반환합니다.
데이터형: single | double | table | timetable
복소수 지원 여부: 예
가중치로, 다음 중 하나로 지정됩니다.
0—N-1로 정규화합니다. 여기서N은 관측값의 개수입니다. 관측값이 하나만 있는 경우 가중치는 1입니다.1—N으로 정규화합니다.음이 아닌 스칼라로 구성된 벡터는 분산이 계산되는
A의 대응하는 차원에 따라 가중됩니다.
데이터형: single | double
연산을 수행할 차원으로, 양의 정수 스칼라로 지정됩니다. 차원을 지정하지 않을 경우, 디폴트 값은 크기가 1이 아닌 첫 번째 배열 차원이 됩니다.
차원 dim은 길이가 1로 줄어드는 차원을 나타냅니다. size(V,dim)은 1이 되고, 다른 모든 차원의 크기는 변경되지 않습니다.
m×n 입력 행렬 A가 있다고 가정합니다.
var(A,0,1)은A의 각 열에서 요소들의 분산을 구하고,1×n행 벡터를 반환합니다.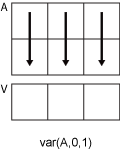
var(A,0,2)는A의 각 행에서 요소들의 분산을 구하고,m×1열 벡터를 반환합니다.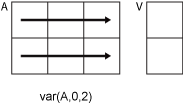
dim이 ndims(A)보다 큰 경우 var(A)는 A와 크기가 같은, 0으로 구성된 배열을 반환합니다.
차원의 벡터로, 양의 정수로 구성된 벡터로 지정됩니다. 각 요소는 입력 배열의 차원을 나타냅니다. 지정된 연산 차원의 출력값의 길이는 1이고, 다른 모든 차원의 길이는 변경되지 않습니다.
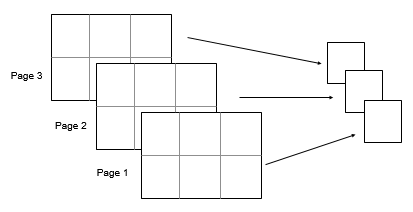
2×3×3 입력 배열 A가 있다고 가정하겠습니다. 이때 var(A,0,[1 2])는 A의 각 페이지에 대해 구한 분산을 요소로 갖는 1×1×3 배열을 반환합니다.
누락값 조건으로, 다음 값 중 하나로 지정됩니다.
"includemissing"또는"includenan"— 분산을 구할 때A의NaN값을 포함합니다. 연산 차원의 요소가 하나라도NaN인 경우 이에 대응하는V의 요소도NaN입니다."includemissing"과"includenan"은 동일하게 동작합니다."omitmissing"또는"omitnan"—A와w의NaN값을 무시하고, 더 적은 수의 점을 대상으로 분산을 구합니다. 연산 차원의 모든 요소가NaN인 경우 이에 대응하는V의 요소는NaN이 됩니다."omitmissing"과"omitnan"은 동일하게 동작합니다.